Mit einem Webcrawler können Sie Inhalte für einen AI Agent importieren. Damit versetzen Sie den AI Agent in die Lage, auf Kundenfragen mit KI-generierten Antworten zu reagieren, die auf Informationen in externen Websites basieren.
Dieser Beitrag hilft Ihnen bei der Fehlerbehebung beim Importieren von Inhalten für einen AI Agent mit einem Webcrawler und enthält die folgenden Themen:
Der Crawler schlägt aufgrund einer Zeitüberschreitung fehl
Wenn der Webcrawler nach mehreren Stunden fehlschlägt, liegt das in der Regel an einem Timeout. Crawls sind standardmäßig auf fünf Stunden begrenzt. Wenn der Fehler fünf Stunden nach Beginn des Importvorgangs aufgetreten ist, wurde er wahrscheinlich durch eine Zeitüberschreitung verursacht.
Führen Sie in diesem Fall folgende Lösungsschritte aus:
- Wenn die Website kein JavaScript enthält, wählen Sie unter Crawler-Typ den deutlich schnelleren Typ „Reiner HTTP-Client (Cheerio)“ aus und versuchen Sie es erneut.
- Wenn Sie wissen, dass Sie bestimmte Inhalte der Website nicht benötigen, lesen Sie den Abschnitt Der Crawler gibt unnötige Seiten zurück.
- Teilen Sie den Vorgang mit den Einstellungen URLs einschließen oder URLs ausschließen in zwei oder mehr separate Vorgänge auf, bei denen jeweils nur Teile der Website bearbeitet werden.
Der Crawler gibt benötigte Seiten nicht zurück
Wenn im Ergebnis des Crawlers ganze URLs oder Beiträge fehlen, erweitern Sie seinen Bereich mit den Einstellungen Start-URLs und URLs einschließen. Wenn Sie sicher sind, dass Sie die richtigen Einstellungen vorgenommen haben, aber trotzdem Beiträge fehlen, überprüfen Sie die Anzahl der gecrawlten Seiten in der Importzusammenfassung. Wenn die Anzahl im Bereich des Standardwerts der Einstellung Max. zu crawlende Seiten (4.000) liegt, wählen Sie einen höheren Wert und versuchen Sie es noch einmal.
Der Crawler gibt unnötige Seiten zurück
Wenn der Crawler mehr Seiten oder Beiträge als nötig zurückgibt, verwenden Sie die Einstellung URLs ausschließen, um redundante oder überflüssige Inhalte (z. B. englische Seiten für einen rein spanischen AI Agent oder Inhalte, die für die Beantwortung von Kundenfragen nicht benötigt werden) zu ignorieren.
Achten Sie darauf, nicht versehentlich bestimmte Unterseiten auszuschließen, die Sie benötigen. Start-URLs legen fest, wo der Crawler beginnt. Von hier aus folgt er allen Links auf dieser und den nachfolgenden Seiten, bis die angegebene maximale Crawling-Tiefe erreicht ist. Wenn Sie jedoch Seiten ausschließen, werden auch keine Seiten gecrawlt, die nur von diesen ausgeschlossenen Seiten aus verlinkt sind und nicht eigens als Start-URLs angegeben wurden.
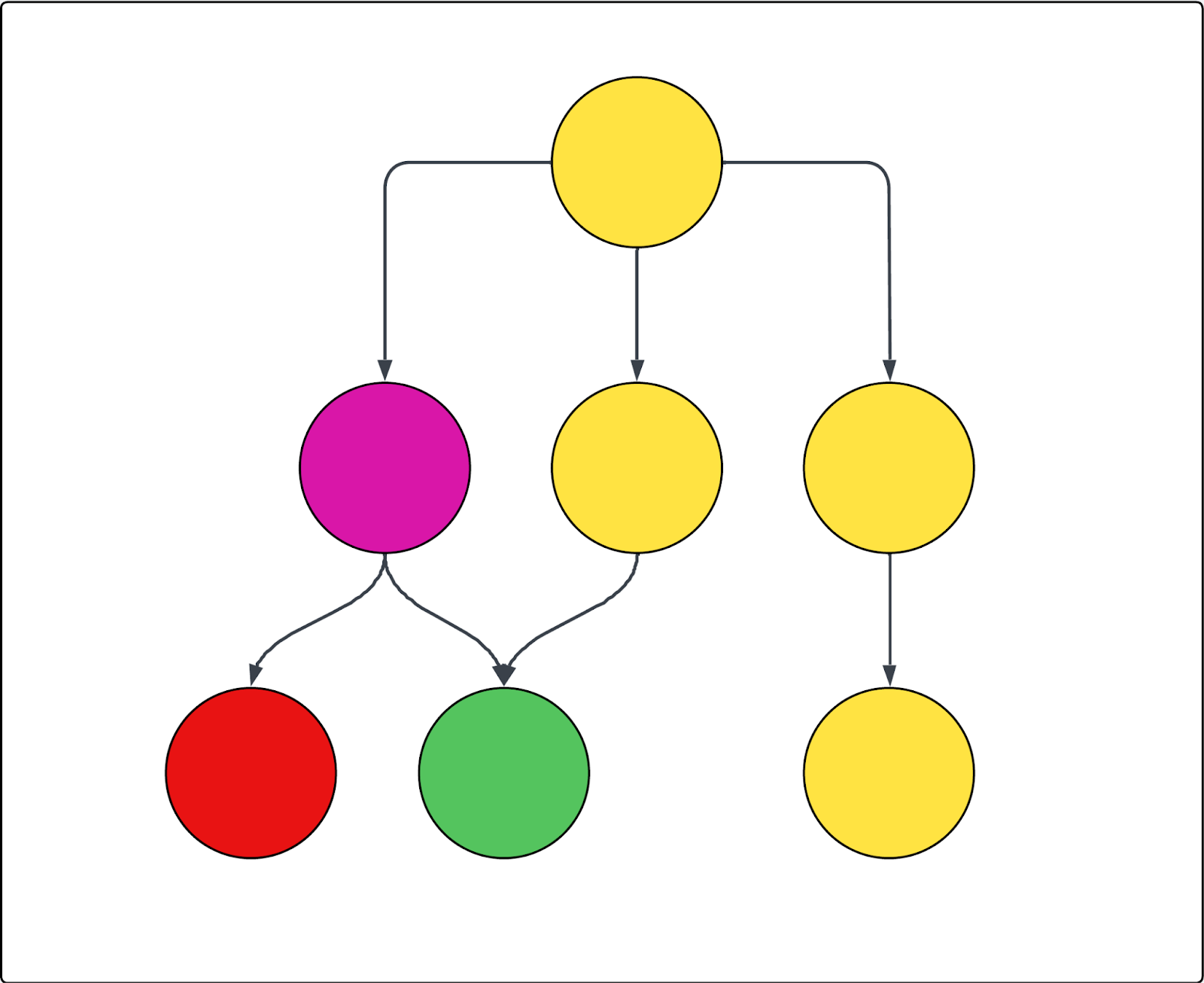
Sehen Sie sich das folgende Beispieldiagramm an. Jeder Kreis steht für eine Seite und jeder Pfeil für einen Link von dieser Seite. Angenommen, der Crawler beginnt mit der obersten Seite, da diese als einzige Start-URL festgelegt ist, und die lila Seite ist ausgeschlossen. In diesem Fall gilt Folgendes:
- Die rote Seite kann nicht gecrawlt werden
- Alle gelben Seiten werden gecrawlt
- Die grüne Seite wird ebenfalls gecrawlt, obwohl sie von der ausgeschlossenen violetten Seite verlinkt ist, da auch von einer der eingeschlossenen gelben Seiten aus ein Link zu ihr führt.
Der Crawler bearbeitet die richtigen Seiten, gibt aber die falschen Inhalte zurück
Wenn der Crawler zwar die richtigen Seiten bearbeitet, aber die falschen Inhalte dieser Seiten zurückgibt, können Sie diese Inhalte mit den Tools in den erweiterten Crawler-Einstellungen auffinden und ausschließen. Hierzu müssen Sie zunächst den richtigen CSS-Selektor für das Element heraussuchen, das Sie einschließen oder ausschließen möchten, und diesen dann in die richtige Einstellung einfügen. Dazu müssen Sie wissen, was ein CSS-Selektor ist und wie Sie ihn finden.
In diesem Abschnitt werden folgende Themen behandelt:
Auffinden und Verwenden von CSS-Selektoren
In diesem Abschnitt erfahren Sie, was CSS-Selektoren sind und wie Sie den richtigen CSS-Selektor finden. Wenn Sie mit diesen Informationen bereits vertraut sind, können Sie stattdessen mit den Abschnitten zur Fehlerbehebung fortfahren.
In diesem Abschnitt werden folgende Themen behandelt:
Überblick über CSS-Selektoren
CSS-Selektoren sind Muster, mit denen sich bestimmte HTML-Elemente einer Webseite gezielt auswählen lassen. Sie erleichtern das Auffinden und Extrahieren benötigter Daten auf komplexen Webseiten.
Beim Crawlen und Scrapen von Web-Inhalten helfen CSS-Selektoren dabei, in der Struktur einer Seite gezielt die richtigen Teile – etwa <div>, <span> oder Elemente mit bestimmten Klassen und IDs – auszuwählen. Der Selektor .product-title findet beispielsweise alle Elemente mit der Klasse "product-title". Das Rautenzeichen (#) wird verwendet, um Elemente anhand ihrer eindeutigen ID auszuwählen. So wählt der Selektor #main-header beispielsweise das Element mit der id="main-header" aus.
Suchen nach einem CSS-Selektor
Zunächst einmal müssen Sie den CSS-Selektor finden, den Sie verwenden möchten. Bei den folgenden Anweisungen wird davon ausgegangen, dass Sie den Webbrowser Chrome verwenden. Die einzelnen Schritte sind bei den meisten anderen Browsern aber ähnlich.
So finden Sie einen CSS-Selektor:
- Machen Sie auf der Website den gewünschten Text oder das gewünschte anklickbare Element ausfindig
-
Klicken Sie mit der rechten Maustaste auf das Element und dann auf Untersuchen.
Die Chrome-Entwicklerkonsole „DevTools“ wird geöffnet und der Code des Elements hervorgehoben.
-
Klicken Sie in der DevTools-Konsole mit der rechten Maustaste auf den hervorgehobenen Code und wählen Sie Kopieren > Kopieren Selektor.
Der CSS-Selektor wird in die Zwischenablage kopiert.
Überprüfen eines CSS-Selektors
Nachdem Sie den CSS-Selektor gefunden haben, sollten Sie ihn überprüfen.
So bestätigen Sie den CSS-Selektor:
-
Drücken Sie bei geöffneter DevTools-Konsole die Tastenkombination Strg+F (Windows und Linux) oder Cmd+F (Mac).
In der Registerkarte „Elemente“ der DevTools-Konsole wird eine Suchleiste eingeblendet.
- Fügen Sie den CSS-Selektor aus der Zwischenablage in das Suchfeld ein.
- Vergewissern Sie sich, dass im HTML-Code und auf der Seite selbst (meist durch eine farbige Umrandung) das gewünschte Element hervorgehoben ist.
Wenn nur das gewünschte Element hervorgehoben ist, haben Sie den richtigen Selektor gewählt. Wenn zu viele oder die falschen Elemente hervorgehoben sind, versuchen Sie es mit einem übergeordneten Element oder passen Sie Ihre Auswahl entsprechend an.
Sie können auch verschiedene Selektoren testen. Manchmal funktionieren kürzere oder spezifischere Selektoren besser. Klicken Sie zu diesem Zweck im HTML-Code beispielsweise auf über- oder untergeordnete Elemente, um ihre CSS-Klassen oder -IDs anzuzeigen, und kopieren Sie auch diese Selektoren.
In den nächsten beiden Abschnitten erfahren Sie, wie Sie mithilfe dieser Selektoren Inhalte finden, die Sie crawlen oder nicht crawlen möchten.
Der Crawler überspringt Seiteninhalte
Wenn der Crawler zwar die richtigen Seiten bearbeitet, aber Inhalte dieser Seiten fehlen, können die folgenden erweiterten Crawler-Einstellungen hilfreich sein:
- HTML-Transformer: Der Crawler liest zunächst den gesamten HTML-Code einer Seite aus und entfernt anschließend mit einem HTML-Transformer überflüssige Inhalte. Dabei kann es passieren, dass der Transformer zu weit geht und Inhalte entfernt, die Sie eigentlich behalten wollten. Wenn Inhalte fehlen, sollten Sie deshalb zunächst einmal den HTML-Transformer ausschalten, damit keine Inhalte entfernt werden, und anschließend die Importzusammenfassung überprüfen.
- HTML-Elemente beibehalten: Behalten Sie nur bestimmte HTML-Elemente, indem Sie einen oder mehrere CCS-Selektoren angeben. Alle anderen Inhalte werden ignoriert, sodass Sie sich ganz auf die relevanten Informationen konzentrieren können
-
Anklickbare Elemente erweitern: Diese Option dient zur Erfassung der Inhalte von Akkordeons und Dropdownlisten. Die Standardeinstellung ist für Webseiten gedacht, bei denen Dropdownlisten wie bei der Web-Entwicklung üblich als
aria=falsedefiniert sind. Wenn der Crawler also auf ein solches Element stößt, klickt er darauf. Geben Sie für jede Schaltfläche, jeden Link und jedes andere Element, das verborgene Inhalte einblendet, einen CSS-Selektor ein. Dadurch ist der Crawler in der Lage, den gesamten Text zu erfassen. Stellen Sie sicher, dass der Selektor gültig ist - Inhalt von Containern beibehalten: Wenn erweiterbarer Inhalt beim Klicken auf ein anderes Element geschlossen wird, können Sie mit dieser Einstellung dafür sorgen, dass einmal angeklickte Elemente geöffnet bleiben. Geben Sie wiederum für jedes Element, das verborgene Inhalte einblendet und auch dann geöffnet bleiben soll, wenn ein anderes Element angeklickt wird, einen CSS-Selektor ein.
-
Auf Auswahl warten und Kurz auf Auswahl warten: Wenn die Seite dynamischer Inhalte aufweist, die erst nach Ablauf einer bestimmten Zeit angezeigt werden, kann der Crawler diese übersehen, sofern Sie ihn nicht ausdrücklich anweisen, auf sie zu warten. Es gibt zwei Selektoren, mit denen Sie den Crawler warten lassen können.
- Die Einstellung Auf dynamischen Inhalt warten gibt an, wie lange der Crawler warten soll. Wenn der Selektor innerhalb dieser Zeit nicht gefunden wird, schlägt die Anfrage fehl und wird einige Male wiederholt
- Der Kurz auf Auswahl warten gibt an, wie lange der Crawler warten soll, sorgt zugleich aber dafür, dass der Crawler mit der Verarbeitung der Seite fortfährt, wenn der Selektor nicht gefunden wird.
- In Verbindung mit dem Crawler-Typ „Reiner HTTP-Client (Cheerio)“ funktionieren diese Einstellungen nicht, da dieser keine JavaScript-Inhalte abruft.
- Maximale Scroll-Höhe: Manche Seiten sind so lang, dass der Crawler aufgibt, bevor er ihr Ende erreicht hat. Wenn Inhalte ab einem bestimmten Punkt fehlen, können Sie den Crawler mit dieser Einstellung zwingen, eine bestimmte Anzahl von Pixeln zu scrollen.
Der Crawler gibt zu viele oder störende Seiteninhalte zurück
Wenn der Crawler zwar die richtigen Seiten bearbeitet, aber zusätzliche oder unnötige Inhalte abruft, die die Antworten des AI Agent stören würden (z. B. Marketingtexte, Navigationselemente, Kopf- und Fußzeilen oder sogar Cookies), können Sie diese mit den folgenden erweiterten Crawler-Einstellungen ausschließen:
- HTML-Elemente beibehalten: Behalten Sie nur bestimmte HTML-Elemente, indem Sie einen oder mehrere CCS-Selektoren angeben. Alle übrigen Inhalte werden ignoriert, sodass Sie sich ganz auf die relevanten Informationen konzentrieren können. Bei vielen Help Centern ist dies die einfachste Möglichkeit, um Beitragsinhalte gezielt ohne Navigationselemente, verwandte Beiträge sowie unnötige Banner und Kopfzeilen abzurufen.
- HTML-Elemente entfernen: Verwenden Sie CSS-Selektoren, um anzugeben, welche HTML-Elemente aus dem Crawl entfernt werden sollen. Dies ist die präziseste und effektivste Methode, um bestimmte bekannte Inhalte auszuschließen
Verwandte Beiträge:
- Best Practices zum Importieren von Inhalten für AI Agents mit einem Webcrawler
- Verwalten von importierten Wissensquellen für AI Agents
Hinweis zur Übersetzung: Dieser Beitrag wurde mit automatischer Übersetzungssoftware übersetzt, um dem Leser ein grundlegendes Verständnis des Inhalts zu vermitteln. Trotz angemessener Bemühungen, eine akkurate Übersetzung bereitzustellen, kann Zendesk keine Garantie für die Genauigkeit übernehmen.
Sollten in Bezug auf die Genauigkeit der Informationen im übersetzten Beitrag Fragen auftreten, beziehen Sie sich bitte auf die englische Version des Beitrags, die als offizielle Version gilt.