Vous pouvez utiliser un crawler Web pour importer du contenu dans votre agent IA. Cela lui permet de créer des réponses générées par l’IA aux questions des clients, en s’appuyant sur les informations de sites Web externes.
Cet article vous aide à résoudre les problèmes que vous pourriez rencontrer quand vous utilisez le crawler Web pour importer du contenu pour un agent IA.
Cet article aborde les sujets suivants :
- L’exploration a échoué, car elle a expiré
- Il manque des pages dans l’exploration
- L’exploration inclut des pages inutiles
- L’exploration inclut les bonnes pages, mais le mauvais contenu
Articles connexes :
L’exploration a échoué, car elle a expiré
Si une exploration Web échoue après plusieurs heures, c’est généralement parce qu’elle a expiré. Par défaut, les explorations sont limitées à cinq heures. Si l’échec a lieu cinq heures après le début de l’importation, il est probable que, là aussi, il s’agisse d’une expiration.
Si cela se produit, voici des mesures que vous pouvez prendre pour essayer de résoudre le problème :
- Si le site Web n’utilise pas JavaScript, configurez le type de crawler sur Client HTTP brut (Cheerio), un crawler beaucoup plus rapide, et réessayez.
- Si vous savez que le site inclut du contenu dont vous n’avez pas besoin, consultez L’exploration inclut des pages inutiles.
- Segmentez l’exploration en deux explorations ou plus (en utilisant les paramètres Inclure les URL ou Exclure les URL) qui n’extraient que certaines parties du site Web.
Il manque des pages dans l’exploration
Si des URL ou des articles manquent dans l’exploration, élargissez la portée de votre exploration en utilisant URL de départ et Inclure les URL. Si vous êtes sûr que les paramètres sont corrects, mais que des articles manquent toujours, vérifiez le nombre de pages explorées dans le résumé de l’importation. S’il est proche du nombre maximal des pages à explorer (4 000), essayez d’accroître ce paramètre.
L’exploration inclut des pages inutiles
Si l’exploration inclut trop de pages ou d’articles (par exemple, du contenu répétitif ou inapplicable, comme des pages en anglais quand vous n’avez besoin que des pages en français, ou du contenu dont votre agent IA n’a pas besoin pour répondre aux questions des clients), utilisez le paramètre Exclure les URL.
Il faut faire attention de ne pas exclure accidentellement certaines sous-pages. Les URL de départ définissent où le crawler commencera. Il suivra ensuite tous les liens de cette page et des pages subséquentes, jusqu’à atteindre la profondeur maximale d’exploration. Cependant, si vous excluez des pages, les pages qui sont liées uniquement depuis des pages exclues ne seront jamais explorées, sauf si vous les spécifiez indépendamment comme URL de départ.
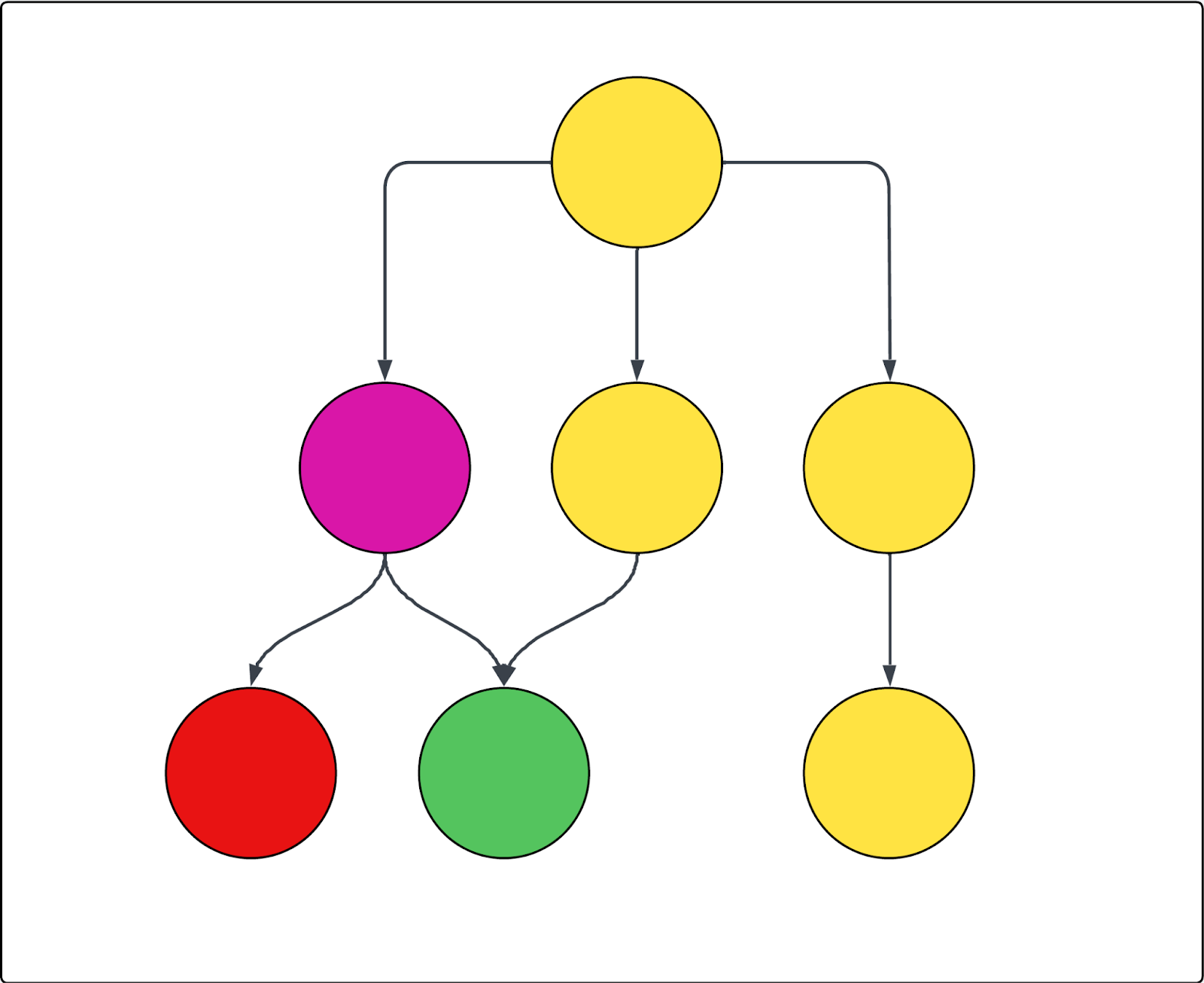
Consultez le diagramme suivant pour voir un exemple. Chaque cercle représente une page et chaque flèche représente un lien depuis cette page. Si l’exploration commence en haut de la page (ici, c’est la seule URL de départ) et si la page violette est exclue, alors ce qui suit est vrai :
- La page rouge ne peut pas être explorée.
- Toutes les pages jaunes sont explorées.
- La page verte sera également explorée, bien qu’elle soit liée depuis la page violette exclue, car elle est aussi liée depuis l’une des pages jaunes incluses.
L’exploration inclut les bonnes pages, mais le mauvais contenu
Si l’exploration renvoie les bonnes pages, mais le mauvais contenu au sein de ces pages, les paramètres avancés du crawler incluent des outils qui vous permettent de trouver et d’inclure ou d’exclure un tel contenu. Vous devez trouver le bon sélecteur CSS pour l’élément que vous voulez inclure ou exclure, puis l’insérer dans le bon paramètre. Pour ce faire, il est utile de comprendre ce qu’est un sélecteur CSS et comment le trouver.
Cette section aborde les sujets suivants :
Que sont les sélecteurs CSS et comment les trouver ?
Cette section présente les sélecteurs CSS et vous explique comment trouver le bon. Si vous savez comment faire, vous pouvez aller directement aux sections de dépannage ci-dessous.
Cette section aborde les sujets suivants :
À propos des sélecteurs CSS
Les sélecteurs CSS sont des schémas utilisés pour sélectionner et cibler des éléments HTML spécifiques sur une page Web. Ils permettent de trouver et d’extraire plus aisément les données dont vous avez besoin de pages Web complexes.
Dans l’exploration et l’extraction Web, les sélecteurs CSS aident à extraire les données en identifiant les parties exactes de la structure d’une page, comme les éléments <div>, <span> ou les éléments avec certaines classes ou certains identifiants. Par exemple, le sélecteur .product-title cible tous les éléments avec la classe "product-title". Le dièse (#) est utilisé pour sélectionner des éléments en fonction de leur ID unique. Par exemple, #main-header sélectionne l’élément avec id="main-header".
Comment trouver un sélecteur CSS
D’abord, vous devez trouver le sélecteur CSS que vous voulez utiliser. Les instructions ci-dessous supposent que vous utilisez Chrome comme navigateur Web, mais les étapes à suivre sont probablement similaires pour les autres navigateurs.
Pour trouver un sélecteur CSS
- Cherchez le texte ou l’élément cliquable sur la page Web que vous voulez cibler.
- Faites un clic droit directement sur cet élément et sélectionnez Inspecter.
Le volet des outils de développement Chrome s’ouvre, avec la section de code correspondante en surbrillance.
- Dans le volet des outils de développement, faites un clic droit sur le code en surbrillance et sélectionnez Copier > Copier le sélecteur.
Le sélecteur CSS est copié dans votre presse-papiers.
Comment vérifier un sélecteur CSS
Une fois que vous avez trouvé le sélecteur CSS, nous vous conseillons de le vérifier.
Pour vérifier le sélecteur CSS
- Avec le volet des outils de développement encore ouvert, appuyez sur Ctrl+F (Windows ou Linux) ou Cmd+F (Mac).
Cela active une barre de recherche dans l’onglet Eléments du volet des outils de développement.
- Collez le sélecteur CSS que vous venez de copier dans le champ de recherche.
- Vérifiez que les éléments en surbrillance dans le code HTML et sur la page (souvent avec un contour de couleur) correspondent à ce que vous attendez.
Si seul l’élément que vous vouliez est en surbrillance, votre sélecteur est correct. Si trop d’éléments ou les mauvais éléments sont en surbrillance, essayez un élément parent ou modifiez votre sélection.
(facultatif) Vous pouvez tester différents sélecteurs. Parfois, des sélecteurs plus courts ou plus spécifiques fonctionnent mieux. Vous pouvez cliquer sur des éléments parents ou enfants dans le code HTML pour voir les classes CSS ou les ID, et essayez de copier aussi ces sélecteurs.
Les deux prochaines sections vous expliquent comment utiliser ces sélecteurs pour cibler le contenu que vous voulez ou ne voulez pas explorer.
L’exploration ignore une partie du contenu des pages
Si votre exploration renvoie les bonnes pages, mais qu’une partie de leur contenu manque, les paramètres avancés du crawler ci-dessous peuvent vous aider :
- Transformateur HTML : au départ, le crawler extrait tout le code HTML d’une page, puis il applique un transformateur HTML pour supprimer le contenu superflu. Il peut arriver que ce transformateur aille trop loin et supprime du contenu que vous voulez garder. Si du contenu manque, commencez par essayer de définir ce paramètre sur Aucun pour qu’aucun contenu ne soit supprimé, puis consultez le résumé de l’importation.
- Conserver les éléments HTML : conservez uniquement des éléments HTML spécifiques en fournissant un ou plusieurs sélecteurs CSS. Tout le reste du contenu est ignoré pour vous aider à vous concentrer sur les informations pertinentes.
-
Développer les éléments cliquables : utilisez cette option pour capturer le contenu qui se « cache » derrière les accordéons et les listes déroulantes. Le paramètre par défaut est fait pour couvrir les pages Web qui suivent les pratiques de développement Web standards et définit les listes déroulantes comme
aria=false. Cela signifie que si le crawler rencontre un élément de ce type, il clique pour l’ouvrir. Saisissez un sélecteur CSS pour tous les éléments sur lesquels le crawler doit cliquer, comme les boutons ou les liens qui développent du contenu caché. Cela aide le crawler à capturer tout le texte. Vérifiez que le sélecteur est valide. - Rendre les conteneurs collants : si le contenu développable se ferme quand le crawler clique sur un autre élément, vous pouvez utiliser ce paramètre pour que ces éléments restent ouverts une fois que le crawler a cliqué dessus. Encore une fois, saisissez un sélecteur CSS pour tous les éléments sur lesquels le crawler doit cliquer et qui doivent ensuite rester ouverts, comme les boutons ou les liens qui développent du contenu caché.
-
Attendre le sélecteur et Attendre patiemment le sélecteur : si la page contient du contenu dynamique qui ne s’affiche qu’après un laps de temps donné, le crawler risque de le manquer, sauf s’il lui est demandé d’attendre. Il y a deux manières de dire au crawler d’attendre avec un sélecteur CSS.
- Le paramètre Attendre le contenu dynamique détermine combien de temps le crawler doit attendre. Si le sélecteur n’est pas trouvé avant la fin de ce laps de temps, la demande est considérée comme ayant échoué et quelques nouvelles tentatives ont lieu.
- Le paramètre Attendre patiemment le sélecteur détermine combien de temps le crawler doit attendre, mais garantit aussi que le crawler continue d’explorer la page si le contenu n’est pas trouvé, ce qui évite les échecs.
- Ces paramètres ne fonctionnent pas avec le type de crawler Client HTTP brut (Cheerio), car il n’extrait pas le contenu JavaScript.
- Hauteur maximale de défilement : certaines pages sont si longues que le crawler abandonne avant la fin. S’il vous manque du contenu au-delà d’un certain point, vous pouvez utiliser ce paramètre pour forcer le crawler à faire défiler un nombre de pixels spécifié.
L’exploration renvoie trop de contenu ou un contenu désordonné
Si votre exploration contient les bonnes pages, mais contient du contenu supplémentaire ou inutile pour ces pages (texte marketing, navigation, en-têtes ou pieds de page, cookies, etc.) qui pourrait perturber les réponses de l’agent IA, utilisez les paramètres avancés du crawler ci-dessous pour exclure ce contenu :
- Conserver les éléments HTML : conservez uniquement des éléments HTML spécifiques en fournissant un ou plusieurs sélecteurs CSS. Tout le reste du contenu est ignoré pour vous aider à vous concentrer sur les informations pertinentes. Pour de nombreux centres d’aide, c’est l’approche la plus simple pour vous assurer que le contenu principal des articles est ciblé, tout en évitant la navigation, les articles connexes et les bannières et en-têtes inutiles.
- Retirer des éléments HTML : utilisez des sélecteurs CSS pour spécifier les éléments HTML à supprimer de l’exploration. C’est la méthode la plus précise et la plus efficace pour exclure du contenu connu spécifique.
Traduction - exonération : cet article a été traduit par un logiciel de traduction automatisée pour permettre une compréhension élémentaire de son contenu. Des efforts raisonnables ont été faits pour fournir une traduction correcte, mais Zendesk ne garantit pas l’exactitude de la traduction.
Si vous avez des questions quant à l’exactitude des informations contenues dans l’article traduit, consultez la version anglaise de l’article, qui représente la version officielle.