Les sources de connaissances sont les informations qu’un agent IA utilise pour créer des réponses générées par l’IA aux questions de vos clients. L’ajout de sources de connaissances à votre agent IA lui permet de générer des réponses pour aider les clients sans que vous ayez à scripter chaque réponse.
Cet article aborde les sujets suivants :
- À propos des sources de connaissances
- Connexion d’un centre d’aide Zendesk à un agent IA
- Connexion d’une source de connaissances externe à un agent IA
- Déconnexion d’une source de connaissances
- Importation d’une source de connaissances (legacy)
- Consultation de toutes les sources de connaissances connectées
Article connexe :
À propos des sources de connaissances
Vous pouvez connecter les types de sources de connaissances suivants à un agent IA :
- Centres d’aide Zendesk : le centre d’aide associé à votre compte Zendesk (ou une marque spécifique si vous avez configuré plusieurs marques).
- Sources de connaissances externes : le contenu de sources externes, importé dans votre compte Zendesk via un crawler Web ou un connecteur de connaissances.
Vous pouvez connecter plusieurs sources de connaissances à un seul agent IA. Par exemple, connectez plusieurs centres d’aide Zendesk, plusieurs sources externes ou les deux. Néanmoins, nous vous conseillons de ne pas importer un nombre trop important de sources de connaissances, car cela cause parfois des problèmes de précision ou de latence.
Quand un agent IA effectue des recherches dans un centre d’aide connecté, il effectue ses recherches dans le contenu actuel du centre d’aide, au moment auquel la recherche a lieu. Cependant, quand un agent IA effectue des recherches dans une source de connaissances externe connectée, il effectue ses recherches dans les informations qui étaient disponibles au moment de la dernière synchronisation (en général, une synchronisation a lieu toutes les 24 heures).
Si vous utilisez du contenu de centre d’aide restreint, l’agent IA respecte les permissions de consultation des articles, ce qui signifie que :
- Si le client est authentifié, l’agent IA peut uniquement utiliser des articles restreints pertinents pour générer sa réponse.
- Si le client n’est pas authentifié, l’agent IA peut uniquement utiliser des articles publics pour générer sa réponse.
Pour en savoir plus, consultez Utilisation du contenu du centre d’aide restreint dans les réponses de l’agent IA.
Connexion d’un centre d’aide Zendesk à un agent IA
Vous pouvez connecter un centre d’aide Zendesk à un agent IA pour que l’agent IA puisse utiliser le contenu du centre d’aide pour générer des réponses aux questions des clients.
Votre centre d’aide doit être activé avant que vous ne puissiez le connecter à un agent IA.
Pour connecter un centre d’aide Zendesk
- Dans l’espace de travail des agents IA, sélectionnez l’agent IA que vous voulez utiliser.
- Cliquez sur
 Contenu dans la barre latérale, puis sélectionnez Sources de connaissances.
Contenu dans la barre latérale, puis sélectionnez Sources de connaissances. - Cliquez sur Modifier les sources.
Une boîte de dialogue Sources de connaissances s’affiche.
- Dans le champ en haut de la boîte de dialogue, sélectionnez Centre d’aide.
- Dans la liste, sélectionnez le centre d’aide Zendesk que vous voulez connecter à l’agent IA.
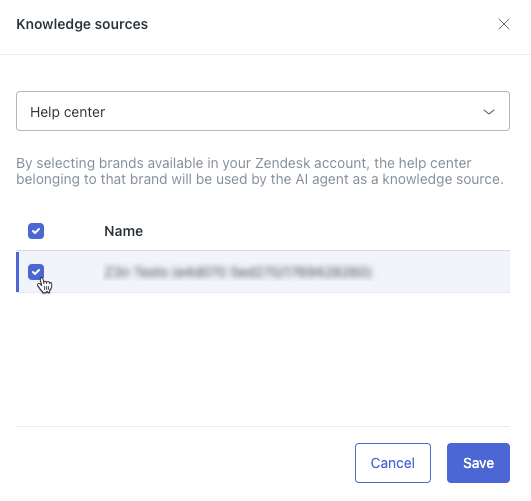 Conseil : si vous ne voyez pas votre centre d’aide, vérifiez que vous l’avez activé.
Conseil : si vous ne voyez pas votre centre d’aide, vérifiez que vous l’avez activé. - Cliquez sur Enregistrer.
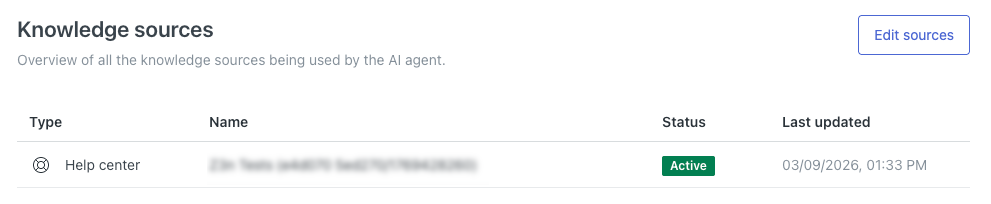
Votre centre d’aide s’affiche dans la liste des sources de connaissances.
Connexion d’une source de connaissances externe à un agent IA
Vous pouvez aussi connecter une source de connaissances externe à un agent IA pour qu’il puisse utiliser les informations provenant de cette source pour générer les réponses aux questions des clients.
Pour connecter une source de connaissances externe
- Si vous ne l’avez pas déjà fait, connectez une source de connaissances externe à votre compte Zendesk.
- Dans l’espace de travail des agents IA, sélectionnez l’agent IA que vous voulez utiliser.
- Cliquez sur Contenu dans la barre latérale, puis sélectionnez Sources de connaissances.
- Cliquez sur Modifier les sources.
Une boîte de dialogue Sources de connaissances s’affiche.
- Dans le champ en haut de la boîte de dialogue, sélectionnez Contenu externe.
- Dans la liste, développez le type de source de connaissances externe si besoin est, puis sélectionnez la source que vous voulez connecter à l’agent IA.
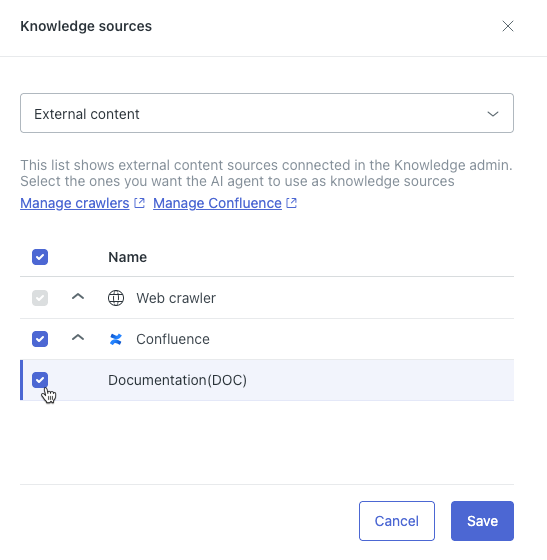
- Cliquez sur Enregistrer.
Votre source de connaissances externe s’affiche dans la liste des sources de connaissances.
Déconnexion d’une source de connaissances
Vous pouvez déconnecter une source de connaissances d’un agent IA afin de l’empêcher d’utiliser les informations de cette source pour générer des réponses aux questions des clients.
Pour déconnecter une source de connaissances
- Dans l’espace de travail des agents IA, sélectionnez l’agent IA que vous voulez utiliser.
- Cliquez sur Contenu dans la barre latérale, puis sélectionnez Sources de connaissances.
- Cliquez sur Modifier les sources.
Une boîte de dialogue Sources de connaissances s’affiche.
- Dans le champ en haut de la boîte de dialogue, sélectionnez Centre d’aide ou Contenu externe.
Dans la liste, désélectionnez la source de connaissances que vous voulez déconnecter.
- Cliquez sur Enregistrer.
La source de connaissances déconnectée est supprimée de la liste des sources de connaissances.
Importation d’une source de connaissances (legacy)
Les administrateurs clients peuvent importer les types de sources de connaissances suivants pour un agent IA :
Importation d’un centre d’aide Zendesk (legacy)
Les administrateurs clients peuvent importer un centre d’aide Zendesk.
Pour importer un centre d’aide Zendesk
- Dans l’espace de travail des agents IA, sélectionnez l’agent IA que vous voulez utiliser.
- Cliquez sur Contenu dans la barre latérale, puis sélectionnez Sources de connaissances.
- Cliquez sur Ajouter une source.
La page Ajouter une source s’ouvre.
- Dans Type, sélectionnez Zendesk.
- Dans URL du centre d’aide, saisissez votre sous-domaine, sans oublier la langue du centre d’aide, par exemple https://votre_sousdomaine.zendesk.com/hc/en-us).
Si vous ne fournissez pas de langue, c’est la langue par défaut du centre d’aide qui est chargée.
- Dans Nom de la source, saisissez un nom pour votre source.
Ce nom est utilisé dans le tableau de bord des rapports Agents IA.
- Dans Fréquence d’importation, sélectionnez la fréquence à laquelle vous voulez que le contenu du centre d’aide soit réimporté :
- Quotidienne : le contenu est réimporté tous les jours, sauf les dimanches et le 15 du mois. Les importations quotidiennes ne sont pas recommandées, sauf si votre source de connaissances est mise à jour très souvent.
- Hebdomadaire : le contenu est réimporté chaque dimanche.
- Mensuelle : le contenu est réimporté le 15 de chaque mois.
-
Jamais : le contenu est importé une fois et n’est jamais réimporté.
Le moment exact d’une réimportation n’est pas garanti. La réimportation a lieu le jour où elle est planifiée, mais peut ne pas être toujours prête à la même heure.
En réimportant régulièrement le contenu du centre d’aide, vous vous assurez que votre agent IA reste à jour. La plupart des organisations peuvent se contenter d’importations hebdomadaires ou mensuelles. N’oubliez pas que vous pouvez toujours effectuer une réimportation manuelle si des modifications apportées hors du calendrier des réimportations doivent être reflétées dans les réponses de votre agent IA.

- Si votre centre d’aide exige que les utilisateurs se connectent ou si vous voulez importer des articles restreints :
- Cliquez sur le bouton pour activer Importer les articles privés.
- Dans E-mail, saisissez l’adresse e-mail d’un utilisateur autorisé à accéder au contenu restreint.
Il s’agit généralement de l’adresse e-mail d’un administrateur Connaissances.
- Dans Token d’accès à l’API, saisissez un token API que vous générez dans ce but.
- Cliquez sur Importer.
Importation d’un centre d’aide Salesforce (legacy)
Les administrateurs clients peuvent importer un centre d’aide Salesforce.
Pour importer un centre d’aide Salesforce
- Dans l’espace de travail des agents IA, sélectionnez l’agent IA que vous voulez utiliser.
- Cliquez sur Contenu dans la barre latérale, puis sélectionnez Sources de connaissances.
- Cliquez sur Ajouter une source.
La page Ajouter une source s’ouvre.
- Dans Type, sélectionnez Salesforce.
- Cliquez sur Se connecter à Salesforce.
- Connectez-vous à votre environnement Salesforce.
- Dans URL du centre d’aide, saisissez l’URL complète de votre centre d’aide Salesforce.
- Dans Nom de la source, saisissez un nom pour votre source.
Ce nom est utilisé dans le tableau de bord des rapports Agents IA.
- Dans Fréquence d’importation, sélectionnez la fréquence à laquelle vous voulez que le contenu du centre d’aide soit réimporté :
- Quotidienne : le contenu est réimporté tous les jours, sauf les dimanches et le 15 du mois. Les importations quotidiennes ne sont pas recommandées, sauf si votre source de connaissances est mise à jour très souvent.
- Hebdomadaire : le contenu est réimporté chaque dimanche.
- Mensuelle : le contenu est réimporté le 15 de chaque mois.
-
Jamais : le contenu est importé une fois et n’est jamais réimporté.
Le moment exact d’une réimportation n’est pas garanti. La réimportation a lieu le jour où elle est planifiée, mais peut ne pas être toujours prête à la même heure.
En réimportant régulièrement le contenu du centre d’aide, vous vous assurez que votre agent IA reste à jour. La plupart des organisations peuvent se contenter d’importations hebdomadaires ou mensuelles. N’oubliez pas que vous pouvez toujours effectuer une réimportation manuelle si des modifications apportées hors du calendrier des réimportations doivent être reflétées dans les réponses de votre agent IA.
- Cliquez sur Importer.
Importation d’un centre d’aide Freshdesk (legacy)
Les administrateurs clients peuvent importer un centre d’aide Freshdesk.
Pour importer un centre d’aide Freshdesk
- Dans l’espace de travail des agents IA, sélectionnez l’agent IA que vous voulez utiliser.
- Cliquez sur Contenu dans la barre latérale, puis sélectionnez Sources de connaissances.
- Cliquez sur Ajouter une source.
La page Ajouter une source s’ouvre.
- Dans Type, sélectionnez Freshdesk.
- Dans URL du centre d’aide, saisissez l’URL complète de votre centre d’aide Freshdesk.
Vous pouvez ajouter la totalité de votre centre d’aide ou seulement une section spécifique.
- Dans Nom de la source, saisissez un nom pour votre source.
Ce nom est utilisé dans le tableau de bord des rapports Agents IA.
- Dans Fréquence d’importation, sélectionnez la fréquence à laquelle vous voulez que le contenu du centre d’aide soit réimporté :
- Quotidienne : le contenu est réimporté tous les jours, sauf les dimanches et le 15 du mois. Les importations quotidiennes ne sont pas recommandées, sauf si votre source de connaissances est mise à jour très souvent.
- Hebdomadaire : le contenu est réimporté chaque dimanche.
- Mensuelle : le contenu est réimporté le 15 de chaque mois.
-
Jamais : le contenu est importé une fois et n’est jamais réimporté.
Le moment exact d’une réimportation n’est pas garanti. La réimportation a lieu le jour où elle est planifiée, mais peut ne pas être toujours prête à la même heure.
En réimportant régulièrement le contenu du centre d’aide, vous vous assurez que votre agent IA reste à jour. La plupart des organisations peuvent se contenter d’importations hebdomadaires ou mensuelles. N’oubliez pas que vous pouvez toujours effectuer une réimportation manuelle si des modifications apportées hors du calendrier des réimportations doivent être reflétées dans les réponses de votre agent IA.
- Dans Token d’accès à l’API, saisissez un token API que vous générez dans Freshdesk dans ce but.
- Cliquez sur Importer.
Importation d’un site ou d’un espace Confluence (legacy)
Les administrateurs clients peuvent importer un site ou un espace Confluence.
La création et la gestion des connexions Confluence se font dans Connaissances. Vous devez créer une connexion Confluence dans Connaissances avant de pouvoir connecter un site ou un espace Confluence pour votre agent IA.
Contrairement aux autres sources de connaissances pour les agents IA, vous ne pouvez pas spécifier de fréquence de réimportation pour le contenu Confluence. Les connexions Confluence sont automatiquement synchronisées toutes les 24 heures, mais vous pouvez resynchroniser le contenu manuellement si besoin est.
Pour importer un site ou un espace Confluence
- Dans l’espace de travail des agents IA, sélectionnez l’agent IA que vous voulez utiliser.
- Cliquez sur Contenu dans la barre latérale, puis sélectionnez Sources de connaissances.
- Cliquez sur Ajouter une source.
La page Ajouter une source s’ouvre.
- Dans Type, sélectionnez Confluence.
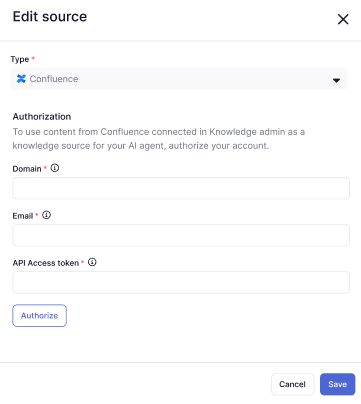
- Dans Domaine, saisissez l’URL de votre sous-domaine Zendesk (par exemple,
https://yoursubdomain.zendesk.com). - Dans E-mail, saisissez l’adresse e-mail d’un administrateur Zendesk.
- Dans Token d’accès à l’API, saisissez un token API que vous générez dans ce but.
- Cliquez sur Autoriser.
- Sélectionnez un site ou un espace Confluence qui est déjà connecté à votre compte Zendesk ou créez une nouvelle connexion Confluence.
Vous pouvez en sélectionner plusieurs.
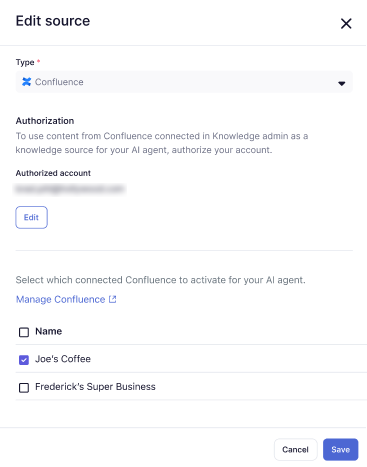
- Cliquez sur Enregistrer.
Le site ou l’espace Confluence que vous avez sélectionné est ajouté à votre liste de sources de connaissances.
Importation d’un fichier CSV (legacy)
Les administrateurs clients peuvent importer un fichier CSV comme source de connaissances.
Pour importer un fichier CSV
- Dans l’espace de travail des agents IA, sélectionnez l’agent IA que vous voulez utiliser.
- Cliquez sur Contenu dans la barre latérale, puis sélectionnez Sources de connaissances.
- Cliquez sur Ajouter une source.
La page Ajouter une source s’ouvre.
- Dans Type, sélectionnez Fichier (CSV).
- Cliquez sur Sélectionner un fichier CSV comme source de connaissances.
- Sélectionnez le fichier CSV à importer.
Consultez Formatage du fichier CSV pour vous assurer que votre fichier est formaté correctement.
- Dans Nom de la source, saisissez un nom pour votre source.
Ce nom est utilisé dans le tableau de bord des rapports Agents IA.
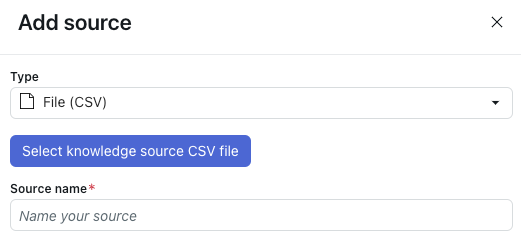
- Cliquez sur Importer.
Formatage du fichier CSV
Le fichier CSV que vous importez comme source de connaissances doit avoir une ligne pour chaque article que vous souhaitez importer. Il doit inclure les colonnes suivantes :
- title : le titre de l’article.
-
content : le contenu intégral de l’article.
- Le contenu peut inclure des balises HTML, vous n’avez donc pas besoin de les supprimer. D’ailleurs, ces balises peuvent être utiles pour structurer les articles, ce qui aide l’agent IA à comprendre les sections d’un article.
- Le contenu peut aussi contenir du code Markdown, mais il doit être valide. Sinon, le contenu de la cellule ne sera pas importé. En outre, si le code Markdown a été rédigé de telle façon que la cellule est une seule ligne de plus de 2 000 caractères, l’importation échoue sans avertissement.
Vous pouvez aussi inclure les colonnes facultatives suivantes :
- labels : une liste de libellés séparés par des espaces. Vous pouvez choisir n’importe quelles valeurs qui vous permettent de catégoriser le contenu.
- locale : cela vous permet d’organiser les articles par langue ou par marché. En théorie, vous pouvez utiliser n’importe quelles valeurs, mais vous conseillons de suivre les normes courantes (p. ex., en-US ou fr-FR).
- article_url : l’adresse Web externe où se trouve l’article. Cela est utilisé pour l’attribution des sources dans le widget et dans le tableau de bord des rapports des agents IA.
Le format de fichier doit aussi utiliser :
- des virgules (,) comme séparateur de colonne et des guillemets doubles (") comme caractère de citation de chaîne ;
- la première ligne pour les en-têtes de colonnes ;
- des caractères ASCII uniquement (l’importation des fichiers CSV échoue s’ils contiennent des caractères non-ASCII).
Vous pouvez télécharger un modèle à la fin de cet article.
Importation du contenu avec un crawler Web (legacy)
Les administrateurs clients peuvent importer le contenu d’un site Web en utilisant un crawler Web.
Pour en savoir plus sur les importations des crawlers Web, consultez Meilleures pratiques pour l’utilisation d’un crawler Web pour importer du contenu dans les agents IA et Dépannage des problèmes liés aux importations du crawler Web pour les agents IA.
Pour importer du contenu indexé par les moteurs de recherche
- Dans l’espace de travail des agents IA, sélectionnez l’agent IA que vous voulez utiliser.
- Cliquez sur Contenu dans la barre latérale, puis sélectionnez Sources de connaissances.
- Cliquez sur Ajouter une source.
La page Ajouter une source s’ouvre.
- Dans Type, sélectionnez Crawler Web.
- Dans Nom de la source, saisissez un nom pour votre source.
Ce nom est utilisé dans le tableau de bord des rapports Agents IA.
- Sélectionnez Explorer l’URL exacte si vous voulez que le crawler Web importe les informations des pages Web répertoriées dans le champ URL de départ, sans inclure les sous-pages.
Quand cette option n’est pas sélectionnée, le crawler Web applique un niveau d’exploration maximal de 15 sous-pages pour les URL répertoriées dans le champ URL de départ.
- Dans URL de départ, saisissez les URL que vous voulez que le crawler Web explore.
Saisissez une seule URL par ligne.
- Dans Fréquence d’importation, sélectionnez la fréquence à laquelle vous voulez que le contenu exploré soit réimporté :
- Quotidienne : le contenu est réimporté tous les jours, sauf les dimanches et le 15 du mois. Les importations quotidiennes ne sont pas recommandées, sauf si votre source de connaissances est mise à jour très souvent.
- Hebdomadaire : le contenu est réimporté chaque dimanche.
- Mensuelle : le contenu est réimporté le 15 de chaque mois.
-
Jamais : le contenu est importé une fois et n’est jamais réimporté.
Le moment exact d’une réimportation n’est pas garanti. La réimportation a lieu le jour où elle est planifiée, mais peut ne pas être toujours prête à la même heure.
En réimportant régulièrement le contenu du centre d’aide, vous vous assurez que votre agent IA reste à jour. La plupart des organisations peuvent se contenter d’importations hebdomadaires ou mensuelles. N’oubliez pas que vous pouvez toujours effectuer une réimportation manuelle si des modifications apportées hors du calendrier des réimportations doivent être reflétées dans les réponses de votre agent IA.
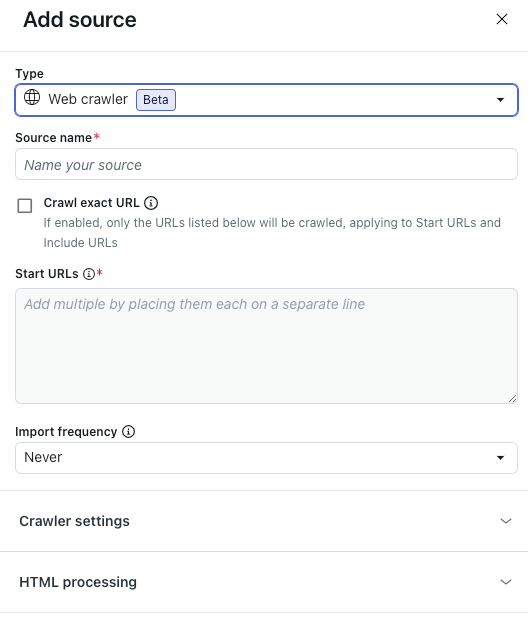
- (facultatif) Développez la section Paramètres du crawler pour configurer les paramètres avancés du crawler.
Consultez Configuration des paramètres de crawler avancés pour en savoir plus.
Remarque – Ces paramètres ne sont conseillés que pour les organisations avec des exigences techniques complexes. De nombreuses organisations n’en ont pas besoin. - (facultatif) Développez la section Traitement HTML pour configurer les paramètres HTML avancés.
Consultez Configuration des paramètres HTML avancés pour en savoir plus.
Remarque – Ces paramètres ne sont conseillés que pour les organisations avec des exigences techniques complexes. De nombreuses organisations n’en ont pas besoin. - Cliquez sur Importer.
Configuration des paramètres de crawler avancés
-
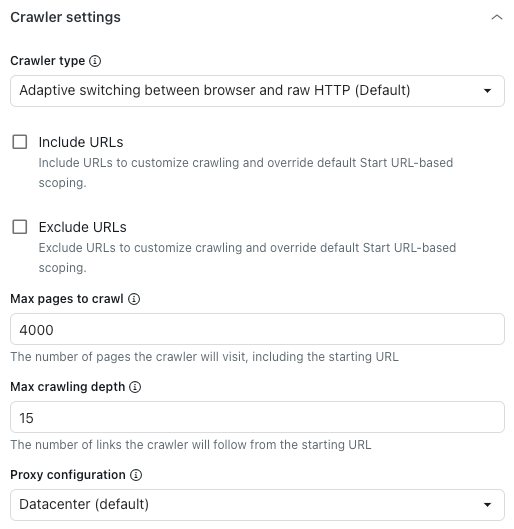
Sous Paramètres du crawler, dans Type de crawler, sélectionnez l’une des options suivantes :
- Commutation adaptative entre le navigateur et HTTP brut (par défaut) : rapide, rend le contenu JavaScript s’il y en a.
- Navigateur sans tête (Firefox + Playwright) : fiable, rend le contenu JavaScript, idéal pour éviter les blocages, mais peut parfois être lent.
- Client HTTP brut (Cheerio) : option la plus rapide, mais ne rend pas le contenu JavaScript.
- Brut avec JavaScript : pour explorer la page comme si vous utilisiez JavaScript.
- Sélectionnez Inclure les URL ou Exclure des URL pour personnaliser le niveau d’exploration défini dans le champ URL de départ ci-dessus.
Dans le champ sous chaque paramètre, saisissez les URL que vous voulez inclure ou exclure. Saisissez une seule URL par ligne.
Ces paramètres n’affectent que les liens trouvés pendant l’exploration des sous-pages. Si vous voulez explorer une page, spécifiez son URL dans le champ URL de départ.Par exemple, si la structure des URL n’est pas homogène comme dans l’exemple ci-dessous :
- URL de départ :
https://support.example.com/en/support/home - URL de l’article :
https://support.example.com/en/support/solutions/articles/…
-
https://support.example.com/en/support/**
Ainsi, le crawler Web inclura tous les articles, même si leur chemin n’est pas le même que celui du chemin de l’URL de départ.
La page ci-dessous est un autre exemple, car elle est très large et inclut des pages qui ne sont pas pertinentes (la page des carrières, p. ex.) :- URL de départ :
https://www.example.com/en
https://www.example.com/en/careers/**
Conseil : les globs, des schémas qui vous permettent d’utiliser des caractères spéciaux pour créer des URL dynamiques que le crawler Web peut explorer, sont plus puissants que le texte brut. Voici quelques exemples :-
https://support.example.com/**permet au crawler d’accéder à toutes les URL qui commencent par https://support.example.com/. -
https://{store,docs}.example.com/**permet au crawler d’accéder à toutes les URL qui commencent par https://docs.example.com. -
https://example.com/**/*\?*foo=*permet au crawler d’accéder à toutes les URLs qui contiennent des paramètres de requête foo avec n’importe quelle valeur.
- URL de départ :
- Dans Nombre maximal de pages à explorer, saisissez le nombre de pages maximum que le crawler Web explorera, URL de départ comprise.
Cela inclut l’URL de départ, les pages de pagination, les pages sans contenu, etc. Le crawler Web s’arrêtera automatiquement une fois cette limite atteinte.
- Dans Profondeur d’exploration maximale, saisissez le nombre maximal de liens que le crawler Web suivra à partir de l’URL de départ.
L’URL de départ a une profondeur de 0. Les pages liées directement depuis l’URL de départ ont une profondeur de 1 et ainsi de suite. Utilisez ce paramètre pour éviter tout emballement accidentel de la part du crawler Web.
- Sous Configuration du proxy, choisissez l’une des options suivantes :
- Centre de données (par défaut) : méthode la plus rapide pour extraire des données.
-
Résidentiel : performances réduites, mais moins de chances d’être bloqué. Méthode idéale quand le proxy par défaut est bloqué ou quand vous devez explorer à partir d’un pays spécifique.
Configuration des paramètres HTML avancés)
-
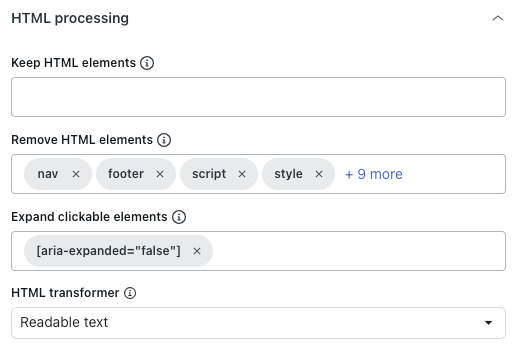
Sous Traitement HTML, dans Conserver les éléments HTML, saisissez un sélecteur CSS pour conserver uniquement les éléments HTML spécifiés.
Tout le reste du contenu sera supprimé, ce qui vous aide à vous concentrer sur les informations pertinentes.
- Dans Retirer des éléments HTML, choisissez les éléments HTML à supprimer avant la conversion en texte ou Markdown, ou l’enregistrement au format HTML.
Cela vous aide à exclure le contenu indésirable ou inutile.
- Dans Développer les éléments cliquables, saisissez un sélecteur CSS valide correspondant aux éléments DOM sur lesquels les utilisateurs cliqueront.
Cela est utile pour développer les sections réduites afin de capture leur contenu texte.
- Dans Transformateur HTML, sélectionnez l’une des valeurs suivantes pour définir comment nettoyer le contenu HTML pour ne garder que le contenu important et supprimer le contenu superflu (navigation ou fenêtres contextuelles, p. ex.) :
- Extractus : (déconseillé) utilise la bibliothèque Extractus.
- Aucun : supprime uniquement les éléments HTML spécifiés dans l’option Retirer des éléments HTML ci-dessus.
- Retirer des éléments HTML : utilise la bibliothèque de lisibilité Mozilla pour extraire le contenu principal de l’article, en supprimant la navigation, les en-têtes, les pieds de page et autres éléments non essentiels. Idéal pour les sites Web et les blogs avec beaucoup d’articles.
-
Texte lisible si possible : utilise la bibliothèque de lisibilité Mozilla pour extraire le contenu principal de l’article, mais se replie sur le contenu HTML original si la page ne semble pas être un article. Cette option est utile pour les sites Web avec des types de contenu mixte, comme des articles et des pages de produits, car elle préserve plus de contenu des pages qui ne sont pas des articles.
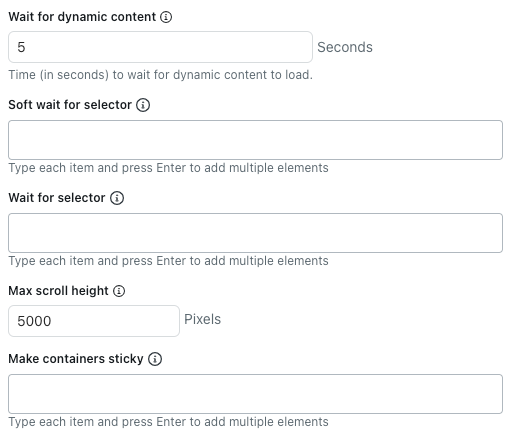
- Dans Attendre le contenu dynamique, saisissez le nombre de secondes pendant lesquelles le crawler doit attendre que le contenu dynamique se charge. Par défaut, il attend cinq secondes ou la fin du chargement de la page, selon ce qui se produit en premier.
- Dans Attendre patiemment le sélecteur, saisissez des sélecteurs CSS pour les éléments HTML desquels le crawler devrait attendre le chargement avant d’extraire le contenu.
Si l’élément sélectionné n’est pas présent, le crawler explore quand même la page.
Saisissez un seul sélecteur CSS par ligne.
- Dans Attendre le sélecteur, saisissez des sélecteurs CSS pour les éléments HTML desquels le crawler doit attendre le chargement avant d’extraire le contenu.
Si l’élément sélectionné n’est pas présent, le crawler n’explore pas la page.
Saisissez un seul sélecteur CSS par ligne.
- Dans Hauteur maximale de défilement, saisissez le nombre maximal de pixels que le crawler doit explorer.
Le crawler fait défiler la page pour charger plus de contenu jusqu’à ce que le réseau soit inactif ou que cette hauteur de défilement soit atteinte. Pour désactiver le défilement, définissez cette valeur sur 0.
Ce paramètre ne s’applique pas quand vous utilisez le client HTTP brut, car il n’exécute pas JavaScript et ne charge pas le contenu dynamique.
- Dans Rendre les conteneurs collants, saisissez des sélecteurs CSS pour les éléments HTML pour lesquels le contenu enfant doit être conservé, même s’il est masqué.
Saisissez un seul sélecteur CSS par ligne.
Cette option est utile quand vous utilisez l’option Développer les éléments cliquables sur des pages qui suppriment totalement le contenu masqué de la page.
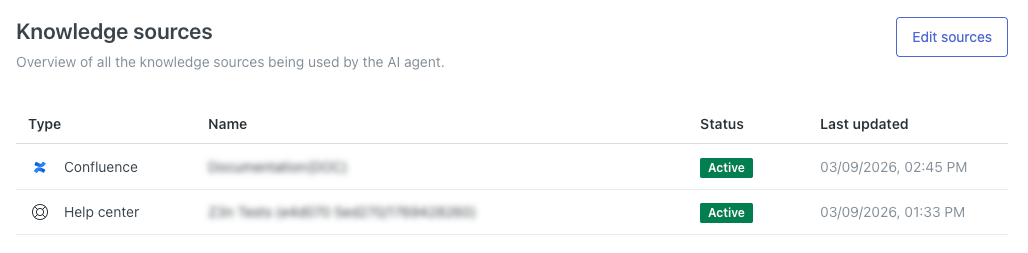
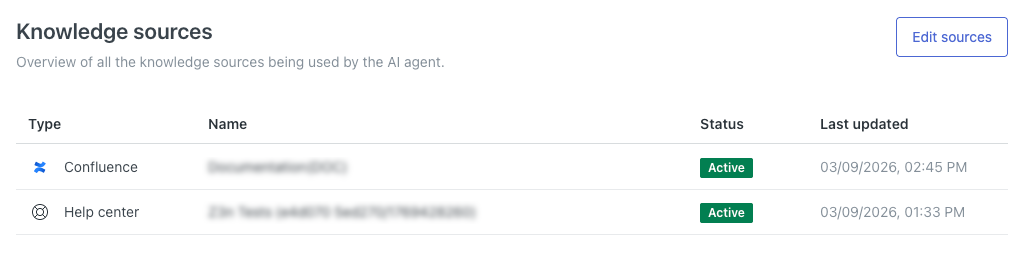
Consultation de toutes les sources de connaissances connectées
Dans les paramètres de votre agent IA, vous pouvez voir toutes les sources de contenu qui y sont connectées actuellement. L’agent IA utilisera ces sources pour générer des réponses aux questions des clients.
Pour consulter toutes les sources de contenu connectées
- Dans l’espace de travail des agents IA, sélectionnez l’agent IA que vous voulez utiliser.
-
Cliquez sur Contenu dans la barre latérale, puis sélectionnez Sources de connaissances.
Cette page affiche une liste de toutes les sources de connaissances connectées à l’agent IA.