Webクローラーを使用して、コンテンツをAIエージェントに取り込むことができます。これにより、外部Webサイトの情報に基づいて、カスタマーの質問に対するAI生成の回答を作成できるようになります。
この記事では、Webクローラーを使用してコンテンツをAIエージェントにインポートする際のトラブルシューティングについて説明します。
タイムアウトが原因でクロールが失敗する場合
Webクロールが数時間経過した後に失敗する場合、その多くはタイムアウトが原因です。クロールはデフォルトで最大5時間に制限されています。インポート開始から約5時間後に失敗した場合、タイムアウトが発生した可能性が高いと考えられます。
このような場合は、次の解決手順を試してください。
- WebサイトがJavaScriptに依存していない 場合は、「クローラータイプ」を、より高速な「Raw HTTP client(Cheerio)」に設定して再試行します。
- サイトに実際には不要なコンテンツが含まれている場合は、「クロールに不要なページが含まれる場合」を参照してください。
- 「含めるURL」や「除外するURL」の設定を使ってクロールを複数に分割し、それぞれでWebサイトの一部のみを対象にクロールします。
一部のページがクロールされない場合
URL 全体や一部の記事がクロールされていない場合は、「開始URL」や「含めるURL」を設定して、クロール範囲を広げてください。設定に問題がないにもかかわらず記事が欠落する場合は、「インポート概要」でクロールされたページ数を確認します。クロール数が、デフォルトの「クロールする最大ページ数」(4,000)付近に達している場合は、この上限を引き上げて再実行してください。
クロールに不要なページが含まれる場合
クロール結果に不要なページや記事が含まれている場合(たとえば、スペイン語のみが必要なのに英語ページも含まれる場合や、AIエージェントの回答に不要なコンテンツが含まれる場合)は、「除外するURL」を設定してください。
ただし、必要なサブページを誤って除外しないよう注意が必要です。「開始URL」は、クローラーの起点となるページを定義します。クローラーは、そこからリンクをたどり、指定した「クロールの最大深度」までページを取得します。ただし、除外されたページからのみリンクされているページは、別途「開始URL」として指定しない限り、クロールされません。
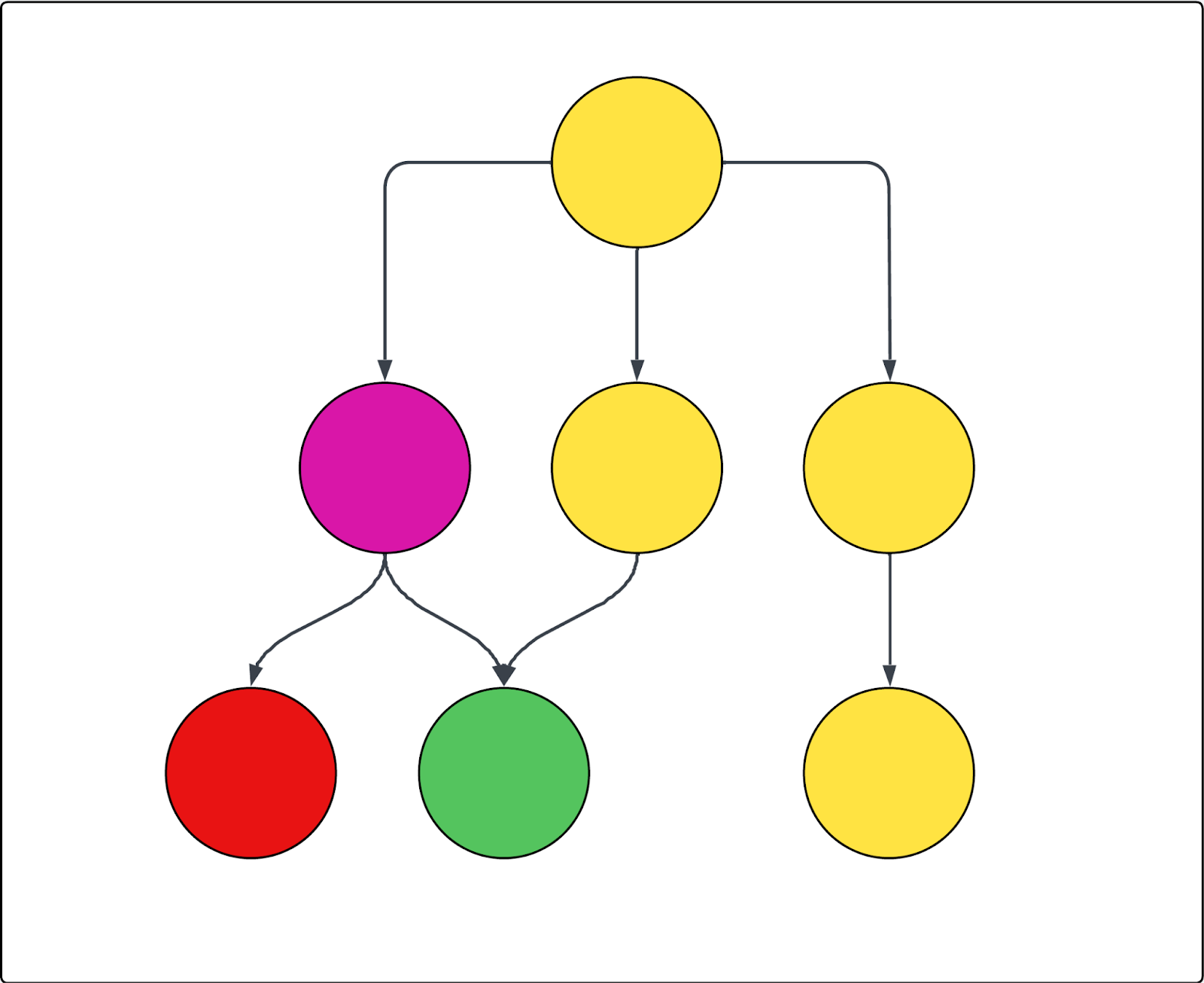
以下の図はその一例です。円はページ、矢印はページ間のリンクを表しています。クロールが最上位ページ(唯一の開始URL)から始まり、紫色のページを除外した場合、結果は次のとおりです。
- 赤色のページはクロールできません
- 黄色のページはすべてクロールされます
- 緑色のページは、除外された紫色のページからもリンクされていますが、黄色のページからもリンクされているため、クロールされます
クロール結果のページは正しいが、内容が正しくない場合
クロールで正しいページは取得できているものの、ページ内のコンテンツが意図した内容になっていない場合は、高度なクローラー設定を使用して、特定のコンテンツを含める、または除外することができます。そのためには、対象となる要素のCSSセレクターを特定し、該当する設定に指定する必要があります。CSS セレクターを正しく指定するには、その仕組みと見つけ方を理解しておくことが重要です。
ここでは、以下のトピックについて説明します。
CSSセレクターの基礎と見つけ方
このセクションでは、CSSセレクターの概要と、適切なセレクターを見つける手順について説明します。すでにCSSセレクターに関する知識がある場合は、以下のトラブルシューティングセクションに進んでください。
ここでは、以下のトピックについて説明します。
CSSセレクターとは
CSSセレクターは、Webページ上の特定のHTML要素を選択するためのパターンです。複雑なWebページの中から、必要なデータを正確に特定して抽出しやすくなります。
Webページのクロールやスクレイピングでは、CSSセレクターを使って、 <div>や <span>、特定のクラスやIDを持つ要素など、ページ構造の特定部分を指定してデータを取得します。たとえば、セレクター .product-title は、クラス名が "product-title" のすべての要素を対象とします。また、シャープ記号(#)は一意のIDを持つ要素を指定するために使用されます。たとえば、#main-header は、id="main-header" を持つ要素を選択します。
CSSセレクターを特定する
まず、使用したいCSSセレクターを特定する必要があります。以下の手順は、Chromeブラウザを使用していることを前提としています。他のブラウザでも概ね同様の操作で確認できます。
CSSセレクターを見つける
- 対象とするテキストやクリック可能な項目をWebページ上で探します
-
その要素を直接右クリックし、「検査」を選択します。
Chrome DevToolsが開き、該当するHTMLコードがハイライト表示されます。
-
DevToolsパネルで、ハイライトされたコードを右クリックし、「>をコピー」「セレクターをコピー」を選択します。
CSSセレクターがクリップボードにコピーされます。
CSSセレクターを検証する
CSSセレクターを見つけたら、確認することをお勧めします。
CSSセレクターを検証するには、次の手順に従います。
-
DevToolsを開いたまま、Ctrl+F(WindowsまたはLinux)またはCmd+F(Mac)を押します。
これにより、DevToolsのElements(要素)タブ内に検索バーが表示されます。
- この検索ボックスに、先ほどコピーしたCSSセレクターを貼り付けます
- HTML上およびページ上でハイライト表示される要素(多くの場合、色付きの枠線で表示されます)が、想定どおりの内容かを確認します。
目的の要素のみがハイライト表示される場合、そのセレクターは正確です。ハイライト表示される要素が多すぎる、または意図しない要素が含まれる場合は、親要素を指定する、またはセレクターを調整してください。
必要に応じて、別のセレクターを試すこともできます。セレクターは、短くしたり、より具体的にしたほうが適切に機能する場合があります。HTML内で親要素や子要素をクリックすると、それぞれのCSSクラスやIDを確認でき、それらを使って別のセレクターをコピーして試すことも可能です。
以降の2つのセクションでは、これらのセレクターを使用して、クロールに含めるコンテンツと除外するコンテンツを指定する方法を説明します。
クロール時にページ内コンテンツが取得されない場合
クロール対象のページ自体は正しいものの、ページ内の一部コンテンツが取得されていない場合は、以下の高度なクローラー設定が役立ちます。
- HTMLトランスフォーマー:クローラーは最初にページ内のすべてのHTMLを取得し、その後HTMLトランスフォーマーを適用して不要なコンテンツを除去します。この処理が過剰に働くと、保持したいコンテンツまで削除されることがあります。コンテンツが欠落している場合は、まずこの設定を「なし」に変更し、コンテンツの除去を行わない状態でインポート概要を確認してください
- HTML要素を保持:1つ以上のCSSセレクターを指定し、特定のHTML要素のみを取得します。それ以外のコンテンツは無視されるため、必要な情報だけに絞ってクロールできます
-
クリック可能な要素を展開:アコーディオンやドロップダウンの内側など、クリック操作によって表示されるコンテンツを取得するための設定です。デフォルトでは、標準的なWeb開発慣行に従い、
aria=falseと定義されたドロップダウン要素が対象となります。つまり、クローラーは該当要素を検出すると自動的にクリックして展開します。非表示コンテンツを展開するボタンやリンクなど、クリックすべき要素のCSSセレクターを指定してください。これによりクローラーがすべてのテキストをキャプチャできます。セレクターが有効であることを必ず確認してください - コンテナをスティッキーにする:別の要素をクリックすると、すでに展開されたコンテンツが閉じてしまう場合に使用します。この設定を有効にすると、指定した要素はクリック後も開いた状態を維持します。非表示コンテンツを展開するボタンやリンクなど、他の操作後も開いたままにしたい要素のCSSセレクターを指定します。
-
動的コンテンツを待機 / セレクターをソフト待機:一定時間経過後に表示される動的コンテンツがある場合、待機設定を行わないとクローラーがその内容を取得できないことがあります。CSSセレクターを使って待機を指示する方法は2つあります。
- 動的コンテンツを待機:クローラーが待機する時間を設定します。セレクターが指定時間待機し、その間にセレクターが見つからなければリクエストは失敗とみなされ、数回再試行されます。
- セレクターをソフト待機:待機時間を設定しつつ、セレクターが見つからなくてもクロールを継続します。これにより失敗を防ぐことができます。
- これらの設定は、JavaScriptコンテンツを取得しないRaw HTTP client(Cheerio)クローラータイプでは機能しません。
- スクロールの最大高:ページが非常に長い場合、クローラーが途中で処理を終了してしまうことがあります。ページ下部のコンテンツが欠落する場合は、この設定で指定したピクセル数まで強制的にスクロールさせることができます。
クロール結果に不要な、または過剰なコンテンツが含まれる場合
クロール対象のページ自体は正しく取得できているものの、ページ内に余分なコンテンツ(マーケティング文言、ナビゲーション、ヘッダーやフッター、cookie情報など)が含まれており、AIエージェントの回答に影響を与えている可能性がある場合は、以下の高度なクローラー設定を使用して不要なコンテンツを除外できます。
- HTML要素を保持:1つ以上のCSSセレクターを指定し、特定のHTML要素のみを取得します。それ以外のコンテンツは無視されるため、必要な情報だけに絞ってクロールできます。多くのヘルプセンターでは、ナビゲーション、関連記事、不要なバナーやヘッダーを避けつつ、メインの記事コンテンツを確実に取得できる、最もシンプルな方法です。
- HTML要素を削除:CSSセレクターを使用して、クロールから除外するHTML要素を指定します。特定の既知のコンテンツを明示的に除外したい場合に、最も精密かつ強力な方法です。
関連記事
翻訳に関する免責事項:この記事は、お客様の利便性のために自動翻訳ソフ トウェアによって翻訳されたものです。Zendeskでは、翻訳の正確さを期すために相応の努力を払っておりますが、翻訳の正確性につ いては保証いたしません。
翻訳された記事の内容の正確性に関して疑問が生じた場合は、正式版である英語の記事 を参照してください。