ナレッジソースとは、AIエージェントが顧客からの質問に対してAI生成の回答を作成する際に使用する情報です。ナレッジソースをAIエージェントに追加することで、すべての回答をスクリプト化することなく、カスタマーに役立つ回答を自動生成できるようになります。
この記事では、次のトピックについて説明します。
- ナレッジソースについて
- ZendeskヘルプセンターをAIエージェントに接続する
- 外部のナレッジソースをAIエージェントに接続する
- ナレッジソースの接続を切断する
- ナレッジソースをインポートする(旧バージョン)
- 接続済みのすべてのナレッジソースを表示する
関連記事:
ナレッジソースについて
AIエージェントには、以下のタイプのナレッジソースを接続することができます。
- Zendeskヘルプセンター:Zendeskアカウント(または複数のブランドを設定している場合は、特定のブランド)に関連付けられたヘルプセンター。
- 外部のナレッジソース:Webクローラーやナレッジベースコネクタを通じてZendeskアカウントに取り込まれる、外部ソースからのコンテンツ。
1つのAIエージェントに複数のナレッジソースを接続することができます。たとえば、複数のZendeskヘルプセンター、複数の外部ソース、またはその両方を組み合わせて接続することが可能です。ただし、ナレッジソースの総数は、適切な範囲に収めることをおすすめします。ソースが多すぎると、返答の精度が低下したり、応答速度が遅くなったりする場合があります。
AIエージェントが接続されたヘルプセンターを検索する場合、検索実行時点のヘルプセンターの最新コンテンツが検索対象となります。一方、接続された外部のナレッジソースを検索する場合は、前回の同期時点で利用可能だった情報が検索対象となります。なお、同期は通常24時間ごとに行われます。
制限付きヘルプセンターコンテンツを使用している場合、AIエージェントの応答は記事の閲覧権限を反映します。具体的には以下のとおりです。
- カスタマーが認証済みの場合、AIエージェントは関連する制限付き記事を使用して応答を生成できます。
- カスタマーが未認証の場合は、公開記事のみを使用して応答を生成します。
詳細については、「制限付きヘルプセンターコンテンツを使用するAIエージェントの応答」を参照してください。
ZendeskヘルプセンターをAIエージェントに接続する
ZendeskヘルプセンターをAIエージェントに接続すると、AIエージェントはヘルプセンターのコンテンツを使用して、顧客からの質問に対する回答を生成できるようになります。
ヘルプセンターをAIエージェントに接続するには、事前にヘルプセンターをアクティブにしておく必要があります。
Zendeskヘルプセンターを接続するには
- AIエージェントワークスペースで、操作するAIエージェントを選択します。
- サイドバーの「
 コンテンツ」をクリックし、「ナレッジソース」を選択します。
コンテンツ」をクリックし、「ナレッジソース」を選択します。 - 「ソースを編集」をクリックします。
「ナレッジソース」ダイアログが表示されます。
- 上部のフィールドで、「ヘルプセンター」を選択します。
- リストから、AIエージェントに接続するZendeskヘルプセンターを選択します。
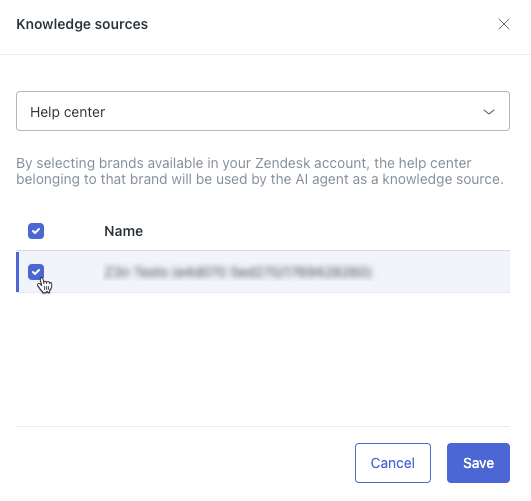 ヒント:ヘルプセンターが表示されない場合は、アクティブになっているか確認してください。
ヒント:ヘルプセンターが表示されない場合は、アクティブになっているか確認してください。 - 「保存」をクリックします。
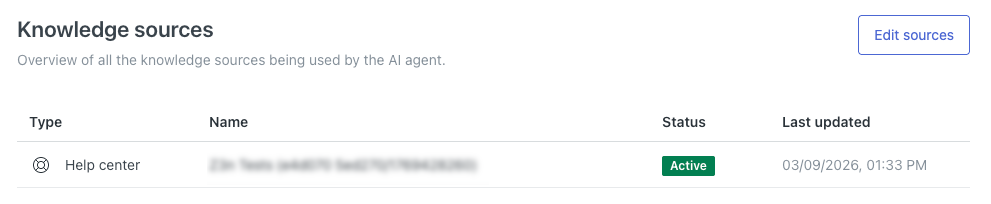
ヘルプセンターが「ナレッジソース」のリストに表示されます。
外部のナレッジソースをAIエージェントに接続する
外部のナレッジソースをAIエージェントに接続すると、AIエージェントはカスタマーの質問に対する回答を生成する際に、そのナレッジソースの情報を利用できます。
外部のナレッジソースを接続するには
- まだ接続を行っていない場合は、Zendeskアカウントに外部のナレッジベースを接続します。
- AIエージェントワークスペースで、操作するAIエージェントを選択します。
- サイドバーの「 コンテンツ」をクリックし、「ナレッジソース」を選択します。
- 「ソースを編集」をクリックします。
「ナレッジソース」ダイアログが表示されます。
- 上部のフィールドで、「外部コンテンツ」を選択します。
- リストで、必要に応じて外部のナレッジソースのタイプを展開し、AIエージェントに接続するソースを選択します。
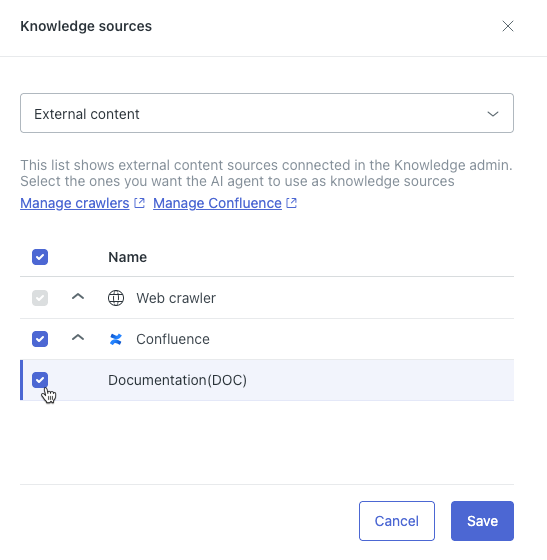
- 「保存」をクリックします。
選択した外部のナレッジソースが「ナレッジソース」リストに表示されます。
ナレッジソースの接続を切断する
AIエージェントからナレッジソースを接続解除すると、カスタマーの質問に対する回答を生成する際に、そのソースからの情報をAIエージェントが利用できなくなります。
ナレッジソースの接続を切断するには
- AIエージェントワークスペースで、操作するAIエージェントを選択します。
- サイドバーの「 コンテンツ」をクリックし、「ナレッジソース」を選択します。
- 「ソースを編集」をクリックします。
「ナレッジソース」ダイアログが表示されます。
- 上部のフィールドで、「ヘルプセンター」または「外部コンテンツ」を選択します。
リストで、接続を切断するナレッジソースの選択を解除します。
- 「保存」をクリックします。
接続を切断したナレッジソースは、「ナレッジソース」リストから削除されます。
ナレッジソースをインポートする(旧バージョン)
クライアントの管理者は、以下のタイプのナレッジソースをインポートして、AIエージェントに使用させることができます。
Zendeskヘルプセンターをインポートする(旧バージョン)
クライアントの管理者はZendeskヘルプセンターをインポートできます。
Zendeskヘルプセンターをインポートするには
- AIエージェントワークスペースで、操作するAIエージェントを選択します。
- サイドバーの「 コンテンツ」をクリックし、「ナレッジソース」を選択します。
- 「ソースを追加」をクリックします。
「ソースを追加」ペインが開きます。
- 「タイプ」で「Zendesk」を選択します。
- 「ヘルプセンターのURL」には、ヘルプセンターのロケールを含むサブドメインを入力してください(例: https://yoursubdomain.zendesk.com/hc/en-us)。
ロケールを指定しない場合、ヘルプセンターのデフォルトロケールがアップロードされます。
- 「ソース名」に、ソースの名前を入力します。
この名前は、AIエージェントのレポートダッシュボードに表示されるレポートで使用されます。
- 「インポートの頻度」で、ヘルプセンターのコンテンツを再インポートする頻度を選択します。
- 毎日:コンテンツは、日曜日と毎月15日を除き、毎日再インポートされます。ナレッジソースを頻繁に更新している場合を除き、推奨されません。
- 毎週:コンテンツは毎週、日曜日に再インポートされます。
- 毎月:コンテンツは毎月15日に再インポートされます。
-
なし:コンテンツは一度だけインポートされ、再インポートされることはありません。
再インポートの正確なタイミングは保証されていません。スケジュールされた日には処理されますが、毎回同じ時刻に完了するとは限りません。
定期的な再インポートにより、AIエージェントは最新の状態に保たれます。ほとんどの組織にとっては、毎週または毎月のペースで問題ありません。スケジュールされた再インポートとは別に、変更内容をすぐに反映させたい場合は、手動で再インポートを実行できます。

- ヘルプセンターがユーザーにサインインを要求する場合、またはそれ以外に、アクセス制限のある記事をインポートしたい場合:
- 「プライベート記事をインポート」のトグルをオンに切り替えます。
- 「メールアドレス」に、制限されたコンテンツへのアクセスを許可するユーザーのメールアドレスを入力します。
これは通常、ナレッジベース管理者のメールアドレスです。
- 「APIアクセストークン」に、この目的のために生成したAPIトークンを入力します。
- 「インポート」をクリックします。
Salesforceヘルプセンターをインポートする(旧バージョン)
クライアントの管理者はSalesforceヘルプセンターをインポートできます。
Salesforceヘルプセンターをインポートするには
- AIエージェントワークスペースで、操作するAIエージェントを選択します。
- サイドバーの「 コンテンツ」をクリックし、「ナレッジソース」を選択します。
- 「ソースを追加」をクリックします。
「ソースを追加」ペインが開きます。
- 「タイプ」で「Salesforce」を選択します。
- 「Salesforceにサインイン」をクリックします。
- Salesforce環境にログインします。
- 「ヘルプセンターのURL」に、お使いのSalesforceヘルプセンターの正確URLを入力します。
- 「ソース名」に、ソースの名前を入力します。
この名前は、AIエージェントのレポートダッシュボードに表示されるレポートで使用されます。
- 「インポートの頻度」で、ヘルプセンターのコンテンツを再インポートする頻度を選択します。
- 毎日:コンテンツは、日曜日と毎月15日を除き、毎日再インポートされます。ナレッジソースを頻繁に更新している場合を除き、推奨されません。
- 毎週:コンテンツは毎週、日曜日に再インポートされます。
- 毎月:コンテンツは毎月15日に再インポートされます。
-
なし:コンテンツは一度だけインポートされ、再インポートされることはありません。
再インポートの正確なタイミングは保証されていません。スケジュールされた日には処理されますが、毎回同じ時刻に完了するとは限りません。
定期的な再インポートにより、AIエージェントは最新の状態に保たれます。ほとんどの組織にとっては、毎週または毎月のペースで問題ありません。スケジュールされた再インポートとは別に、変更内容をすぐに反映させたい場合は、手動で再インポートを実行できます。
- 「インポート」をクリックします。
Freshdeskヘルプセンターをインポートする(旧バージョン)
クライアントの管理者はFreshdeskヘルプセンターをインポートできます。
Freshdeskヘルプセンターをインポートするには
- AIエージェントワークスペースで、操作するAIエージェントを選択します。
- サイドバーの「 コンテンツ」をクリックし、「ナレッジソース」を選択します。
- 「ソースを追加」をクリックします。
「ソースを追加」ペインが開きます。
- 「タイプ」で「Freshdesk」を選択します。
- 「ヘルプセンターのURL」に、お使いのFreshdeskヘルプセンターの正確なURLを入力します。
ヘルプセンター全体、またはヘルプセンターの特定のセクションのみを追加することができます。
- 「ソース名」に、ソースの名前を入力します。
この名前は、AIエージェントのレポートダッシュボードに表示されるレポートで使用されます。
- 「インポートの頻度」で、ヘルプセンターのコンテンツを再インポートする頻度を選択します。
- 毎日:コンテンツは、日曜日と毎月15日を除き、毎日再インポートされます。ナレッジソースを頻繁に更新している場合を除き、推奨されません。
- 毎週:コンテンツは毎週、日曜日に再インポートされます。
- 毎月:コンテンツは毎月15日に再インポートされます。
-
なし:コンテンツは一度だけインポートされ、再インポートされることはありません。
再インポートの正確なタイミングは保証されていません。スケジュールされた日には処理されますが、毎回同じ時刻に完了するとは限りません。
定期的な再インポートにより、AIエージェントは最新の状態に保たれます。ほとんどの組織にとっては、毎週または毎月のペースで問題ありません。スケジュールされた再インポートとは別に、変更内容をすぐに反映させたい場合は、手動で再インポートを実行できます。
- 「APIアクセストークン」に、この目的のためにFreshdeskで生成したAPIトークンを入力します。
- 「インポート」をクリックします。
Confluenceサイトまたはスペースをインポートする(旧バージョン)
クライアントの管理者は、Confluenceサイトまたはスペースをインポートできます。
Confluenceのコネクションはナレッジベースで作成および管理されます。AIエージェントにConfluenceサイトまたはスペースを接続するには、まずナレッジベースでConfluenceコネクションを作成する必要があります。
AIエージェント向けの他のナレッジソースとは異なり、Confluenceコンテンツの再インポート頻度を指定することはできません。Confluenceのコネクションは24時間ごとに自動的に同期されますが、必要に応じて手動でコンテンツを再同期できます。
Confluenceサイトまたはスペースをインポートするには
- AIエージェントワークスペースで、操作するAIエージェントを選択します。
- サイドバーの「 コンテンツ」をクリックし、「ナレッジソース」を選択します。
- 「ソースを追加」をクリックします。
「ソースを追加」ペインが開きます。
- 「タイプ」で「Confluence」を選択します。
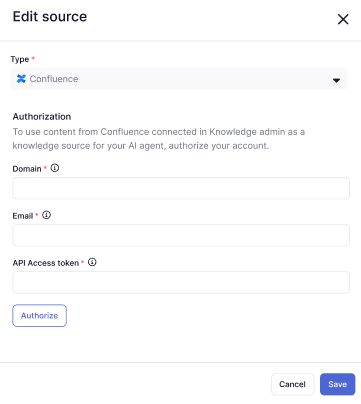
- 「ドメイン」に、ZendeskサブドメインのURLを入力します(例:
https://yoursubdomain.zendesk.com)。 - 「メール」に、Zendesk管理者のメールアドレスを入力します。
- 「APIアクセストークン」に、この目的のために生成したAPIトークンを入力します。
- 「認証」をクリックします。
- Zendeskアカウントに既に接続済みのConfluenceサイトまたはスペースを選択するか、新しいConfluenceコネクションを作成してください。
複数選択することもできます。
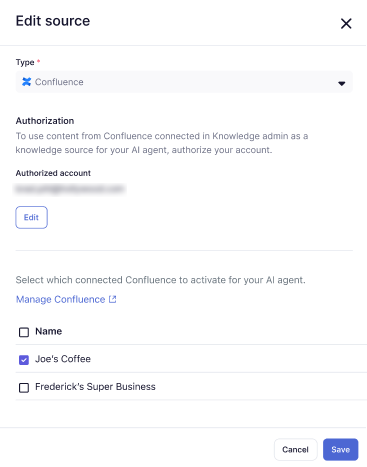
- 「保存」をクリックします。
選択したConfluenceサイトまたはスペースが、ナレッジソースのリストに追加されました。
CSVファイルをインポートする(旧バージョン)
クライアントの管理者は、ナレッジソースのCSVファイルをインポートできます。
CSVファイルをインポートするには
- AIエージェントワークスペースで、操作するAIエージェントを選択します。
- サイドバーの「 コンテンツ」をクリックし、「ナレッジソース」を選択します。
- 「ソースを追加」をクリックします。
「ソースを追加」ペインが開きます。
- 「タイプ」で「ファイル(CSV)」を選択します。
- 「ナレッジソースのCSVファイルを選択」をクリックします。
- インポートするCSVファイルを選択します。
ファイルが適切にフォーマットされていることを確認するには、「CSVファイルの形式に関する要件」を参照してください。
- 「ソース名」に、ソースの名前を入力します。
この名前は、AIエージェントのレポートダッシュボードに表示されるレポートで使用されます。
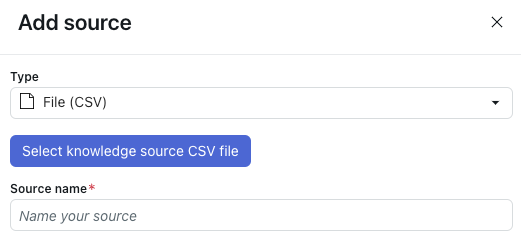
- 「インポート」をクリックします。
CSVファイルの形式に関する要件
ナレッジソースとしてアップロードするCSVファイルには、インポートする記事ごとに1行を使う必要があります。また、CSVファイルには必ず以下の列を含めてください。
- title:記事のタイトル。
-
content:記事の全コンテンツ。
- コンテンツにはHTMLタグを含めることができるため、削除する必要はありません。むしろ、HTMLタグによって記事に構造が与えられることで、AIエージェントがセクションを特定しやすくなります。
- コンテンツにMarkdownを含めることもできますが、Markdownが有効である必要があります。有効でない場合、そのセルのコンテンツはインポートされません。さらに、Markdownが2,000文字を超える1行のセルとして書かれている場合、警告なしでインポートが失敗する可能性があります。
また、以下のオプションの列を含めることもできます。
- labels:スペースで区切られたラベル名のリスト。値には、コンテンツを分類するために使用したい任意の内容を設定できます。
- locale:記事を言語や市場ごとに分類・管理するために使用します。技術的には任意の値を指定できますが、標準的なロケール表記(例:en-US や fi-FI)に従うことが推奨されます。
- article_url:記事が掲載されている外部のWebアドレス。このURLは、ウィジェットでのソース表示や、AIエージェントのレポーティングダッシュボードのレポートで使用されます。
ファイル形式では、次の要件を使用する必要があります。
- 列区切り文字にはカンマ(,)、文字列の引用符には二重引用符(")を使用すること。
- 最初の行は列ヘッダーとすること。
- ASCII文字のみを使用すること。CSVファイルに非ASCII文字が含まれていると、読み込みに失敗します。
この記事の下部からテンプレートをダウンロードできます。
Webクローラーを使ってコンテンツをインポートする(旧バージョン)
クライアントの管理者は、Webクローラーを使用してWebサイトのコンテンツをインポートできます。
Webクローラーによるインポートについて詳しくは、「Webクローラーを使用してコンテンツをAIエージェントにインポートするためのベストプラクティス」および「AIエージェントのWebクローラーのインポートに関する問題のトラブルシューティング」を参照してください。
Webクローラーを使ってコンテンツをインポートするには
- AIエージェントワークスペースで、操作するAIエージェントを選択します。
- サイドバーの「 コンテンツ」をクリックし、「ナレッジソース」を選択します。
- 「ソースを追加」をクリックします。
「ソースを追加」ペインが開きます。
- 「タイプ」で「Webクローラー」を選択します。
- 「ソース名」に、ソースの名前を入力します。
この名前は、AIエージェントのレポートダッシュボードに表示されるレポートで使用されます。
- 「開始URL」フィールドにリストされたページのみから情報をインポートし、サブページを含めたくない場合は、「正確なURLをクロール」を選択してください。
このオプションを選択しない場合、Webクローラーは「開始URL」にリストされた各URLから、最大15階層下のサブページまでクロールします。
- 「開始URL」に、Webクローラーに巡回させたいURLを入力します。
各URLは、1行ずつ分けて記載してください。
- 「インポートの頻度」で、クロールで収集したコンテンツを再インポートする頻度を選択します。
- 毎日:コンテンツは、日曜日と毎月15日を除き、毎日再インポートされます。ナレッジソースを頻繁に更新している場合を除き、推奨されません。
- 毎週:コンテンツは毎週、日曜日に再インポートされます。
- 毎月:コンテンツは毎月15日に再インポートされます。
-
なし:コンテンツは一度だけインポートされ、再インポートされることはありません。
再インポートの正確なタイミングは保証されていません。スケジュールされた日には処理されますが、毎回同じ時刻に完了するとは限りません。
定期的な再インポートにより、AIエージェントは最新の状態に保たれます。ほとんどの組織にとっては、毎週または毎月のペースで問題ありません。スケジュールされた再インポートとは別に、変更内容をすぐに反映させたい場合は、手動で再インポートを実行できます。
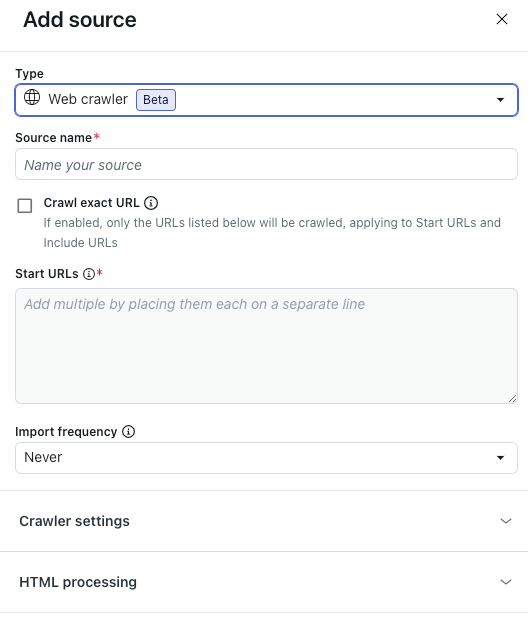
- (オプション)「クローラーの設定」を展開して、詳細設定を行います。
詳しくは「クローラーの詳細設定」を参照してください。
メモ:これらの設定は、技術的に複雑な要件を持つ組織に限り推奨されます。多くの組織では、こうした設定は必要ありません。 - (オプション)「HTML処理」を展開して、高度なHTML設定を行います。
詳しくは「HTMLの詳細設定」をご覧ください。
メモ:これらの設定は、技術的に複雑な要件を持つ組織に限り推奨されます。多くの組織では、こうした設定は必要ありません。 - 「インポート」をクリックします。
クローラーの詳細設定
-
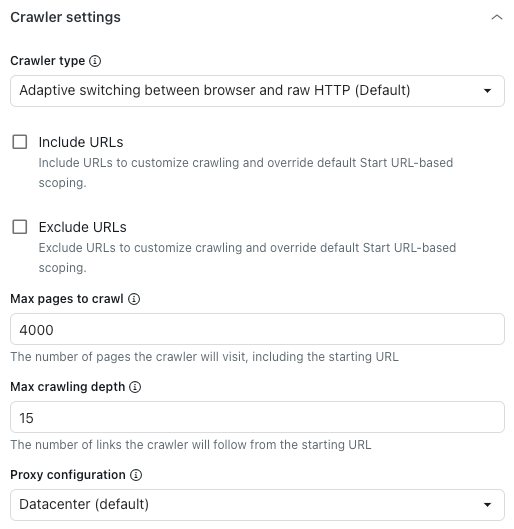
「クローラーの設定」セクションの「クローラーのタイプ」で、以下のオプションのいずれかを選択します。
- ブラウザと生HTTP間の適応型スイッチング(デフォルト):高速で、存在する場合はJavaScriptコンテンツをレンダリングします。
- ヘッドレスブラウザ(Firefox + Playwright):信頼性が高く、JavaScriptコンテンツをレンダリングします。ブロッキングを回避するのに最適ですが、遅くなる場合があります。
- 生HTTPクライアント(Cheerio):最速ですが、JavaScriptコンテンツをレンダリングしません。
- JavaScriptを使用した生ページのクローラー:JavaScriptをレンダリングしたようなページ表示を想定してクロールします。
- 上記の「開始URL」フィールドで設定したクロール範囲をカスタマイズするには、「含めるURL」または「除外するURL」を選択します。
各設定の下にあるフィールドに、含めるまたは除外するURLを入力してください。各URLは1行ずつ入力します。
これらの設定は、サブページのクロール中に見つかったリンクにのみ影響します。特定のページをクロールしたい場合は、「開始URL」フィールドにそのURLを必ず指定してください。たとえば、URL構造に一貫性がない場合(以下の例を参照):
- 開始URL:
https://support.example.com/en/support/home - 記事のURL:
https://support.example.com/en/support/solutions/articles/…
-
https://support.example.com/en/support/**
こうすることで、たとえ記事のパスが開始URLと異なっていても、Webクローラーがすべての記事を取得できるようになります。
別の例として、次のページは非常に範囲が広く、採用情報ページのような無関係なページも含まれています。- 開始URL:
https://www.example.com/en
https://www.example.com/en/careers/**
ヒント:グロブは、プレーンテキストよりも強力で、特殊文字を使って動的なURLパターンを作成できるため、Webクローラーによる検索に活用できます。以下にいくつかの例を示します。-
https://support.example.com/**を指定すると、Webクローラーは https://support.example.com/ で始まるすべてのURLにアクセスできます。 -
https://{store,docs}.example.com/**を指定すると、Webクローラーは https://store.example.com/ または https://docs.example.com/ で始まるすべてのURLにアクセスできます。 -
https://example.com/**/*\?*foo=*を指定すると、Webクローラーは、任意の値を持つfooのクエリパラメータを含むすべてのURLにアクセスできます。
- 開始URL:
- 「クロールする最大ページ数」には、開始URLを含め、Webクローラーがクロールするページの上限を入力します。
これには、開始URL、ページネーションページ、コンテンツのないページなどが含まれます。この制限に達すると、Webクローラーは自動的に停止します。
- 「クロールの最大深度」には、Webクローラーが開始URLから何階層までリンクをたどるかの上限を入力します。
開始URLの深度は0です。開始URLから直接リンクされたページは深度1、その次にリンクされたページは深度2……というように順に深くなっていきます。この設定を使用して、誤ってWebクローラーが暴走することを防ぎます。
- 「プロキシ設定」で、以下のオプションのいずれかを選択します。
- データセンター(デフォルト):データスクレイピングのための最速の方法。
-
レジデンシャル:パフォーマンスは低下しますが、ブロックされる可能性は低くなります。デフォルトのプロキシがブロックされている場合や、特定の国からクロールする必要がある場合に最適です。
HTMLの詳細設定
-
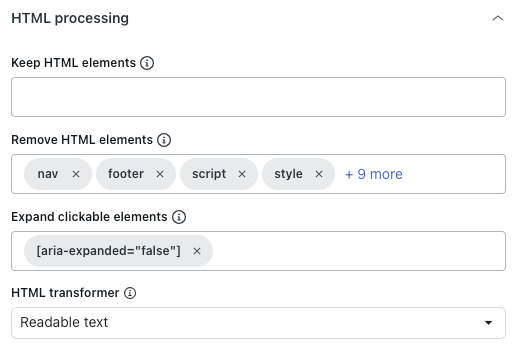
「HTML処理」セクションの「HTML要素を保持」で、指定したHTML要素のみを保持するCSSセレクタを入力します。
その他のコンテンツはすべて削除されるため、関連性の高い情報のみに焦点を合わせやすくなります。
- 「HTML要素を削除」では、テキストやMarkdownに変換したりHTMLとして保存する前に、どのHTML要素を削除するかを選択します。
これにより、不要なコンテンツを除外できます。
- 「クリック可能な要素を展開」に、クリック対象となるDOM要素にマッチする有効なCSSセレクタを入力します。
これは、折りたたまれているセクションを展開して、テキストコンテンツを取得するのに役立ちます。
- 「HTMLトランスフォーマー」で以下のいずれかの値を選択し、HTMLを処理して、重要なコンテンツを抽出し、ナビゲーションやポップアップなどの不要な要素を取り除く方法を定義します。
- Extractus:(非推奨)Extractusライブラリを使用します。
- なし:上記の「HTML要素を削除」オプションで指定されたHTML要素のみを削除します。
- 判読可能なテキスト:MozillaのReadabilityライブラリを使用して、ナビゲーション、ヘッダー、フッター、その他の不要な要素を取り除き、記事の主要なコンテンツを抽出します。記事の多いWebサイトやブログに最適です。
-
判読可能なテキスト(可能な場合):MozillaのReadabilityライブラリを使って主要なコンテンツを抽出します。ページが記事でないとみなされた場合は、元のHTMLにフォールバックします。これは、記事や製品ページなど、さまざまな種類のコンテンツが混在するWebサイトに適しています。記事以外のページでも、より多くのコンテンツを保持できるためです。
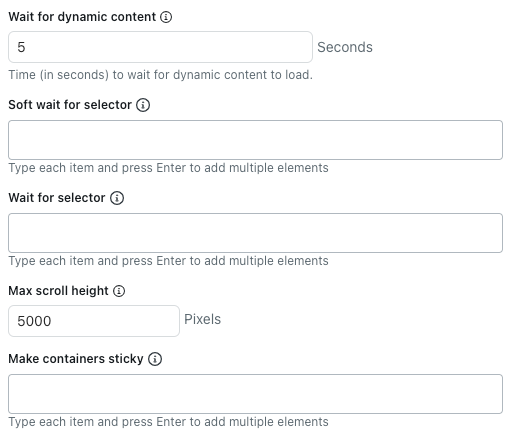
- 「動的コンテンツを待機」に、Webクローラーが動的コンテンツの読み込み完了を待つ秒数を指定します。デフォルトでは、5秒間の待機またはページの読み込みが完了するまでの、どちらか早い方まで待機します。
- 「セレクターをソフト待機」に、Webクローラーがコンテンツを抽出する前に、読み込み完了を待つHTML要素のCSSセレクタを入力します。
選択した要素が存在しない場合でも、Webクローラーはそのページをクロールします。
各CSSセレクタは、1行ずつ個別に指定してください。
- 「セレクターを待機」に、Webクローラーがコンテンツを抽出する前に、必ず読み込みを完了させる必要があるHTML要素のCSSセレクタを入力します。
選択した要素が存在しない場合、Webクローラーはそのページをクロールしません。
各CSSセレクタは、1行ずつ個別に指定してください。
- 「スクロールの最大高」に、Webクローラーがスクロールする最大ピクセル数を入力します。
クローラーは、ネットワークがアイドル状態になるか、このスクロール高に達するまで、さらに多くのコンテンツを読み込むためにページをスクロールします。スクロールを完全に無効にするには、この値を0に設定します。
raw HTTPクライアントを使用する場合は、JavaScriptを実行したり動的コンテンツを読み込んだりしないため、この設定は適用されません。
- 「コンテナをスティッキーにする」では、非表示の状態でも子コンテンツを保持するHTML要素のCSSセレクタを入力します。
各CSSセレクタは、1行ずつ個別に指定してください。
ページによっては、非表示のコンテンツが完全に削除されることがあります。そうした場合でも、「クリック可能な要素を展開」オプションを使用することで、必要な情報を取得しやすくなります。
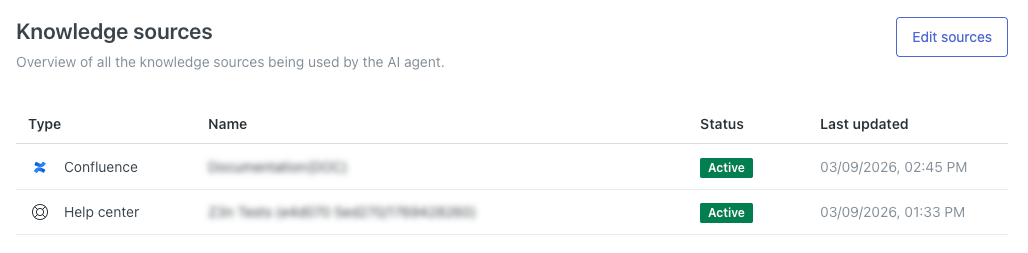
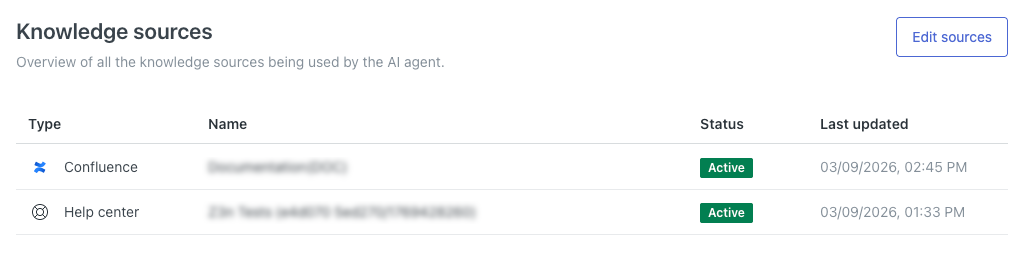
接続済みのすべてのナレッジソースを表示する
AIエージェントの設定画面では、現在接続されているすべてのコンテンツソースを確認できます。AIエージェントはこれらのコンテンツソースを利用して、カスタマーの質問に対する回答を生成します。
接続されているすべてのコンテンツソースを表示するには
- AIエージェントワークスペースで、操作するAIエージェントを選択します。
-
サイドバーの「 コンテンツ」をクリックし、「ナレッジソース」を選択します。
このページには、AIエージェントに現在接続されているすべてのナレッジソースのリストが表示されます。