您可以 使用网络抓取程序将内容导入 到高级人工智能专员中。这样您的人工智能专员就可以根据外部网站的信息,针对客户的问题创建人工智能生成的答案。
这篇文章可帮助您解决在使用网络抓取程序为高级人工智能专员导入内容时可能遇到的问题。
本文章包含以下主题:
相关文章:
抓取失败,因为已超时
如果网络抓取在几个小时后失败,通常是因为超时造成的。默认情况下,抓取限于五小时。如果在导入开始五个小时后发生失败,可能是因为超时了。
如果发生这种情况,您可以尝试执行以下解决步骤:
- 如果网站不依赖于 JavaScript,请将 抓取程序类型 设置为速度更快的原始 HTTP 客户端 (Cheerio) 抓取程序,然后重试。
- 如果您知道网站包含您并不实际需要的内容,请参阅 抓取的内容包含不必要的页面中的指南。
- 将爬网拆分为两个或更多单独的抓取(使用 包含 URL 或 排除 URL 设置),每次仅抓取网站的部分内容。
抓取缺失页面
如果抓取过程中缺失完整 URL 或文章,请使用 开始 URL 和 包含 URL扩大抓取范围。如果您确定设置正确但仍缺少文章,请在 导入概要中检查已抓取页面数。如果在默认的“ 要抓取的最大页数”(4,000)左右,请尝试增加此设置。
抓取包含不需要的页面
如果抓取包括的页面或文章多于必要数量(例如重复或不适用的内容,例如英语页面,而您只需要西班牙语,或者您的人工智能专员不需要回答客户问题),请使用 排除 URL 设置。
要避免的就是意外排除某些子页面。开始 URL 定义了抓取程序的开始位置。然后,它将跟踪从该页面和后续页面开始,一直到指定的 最大抓取深度的所有链接。但是,如果您排除页面,则永远不会抓取仅从排除页面链接的任何页面,除非单独指定为 开始 URL。
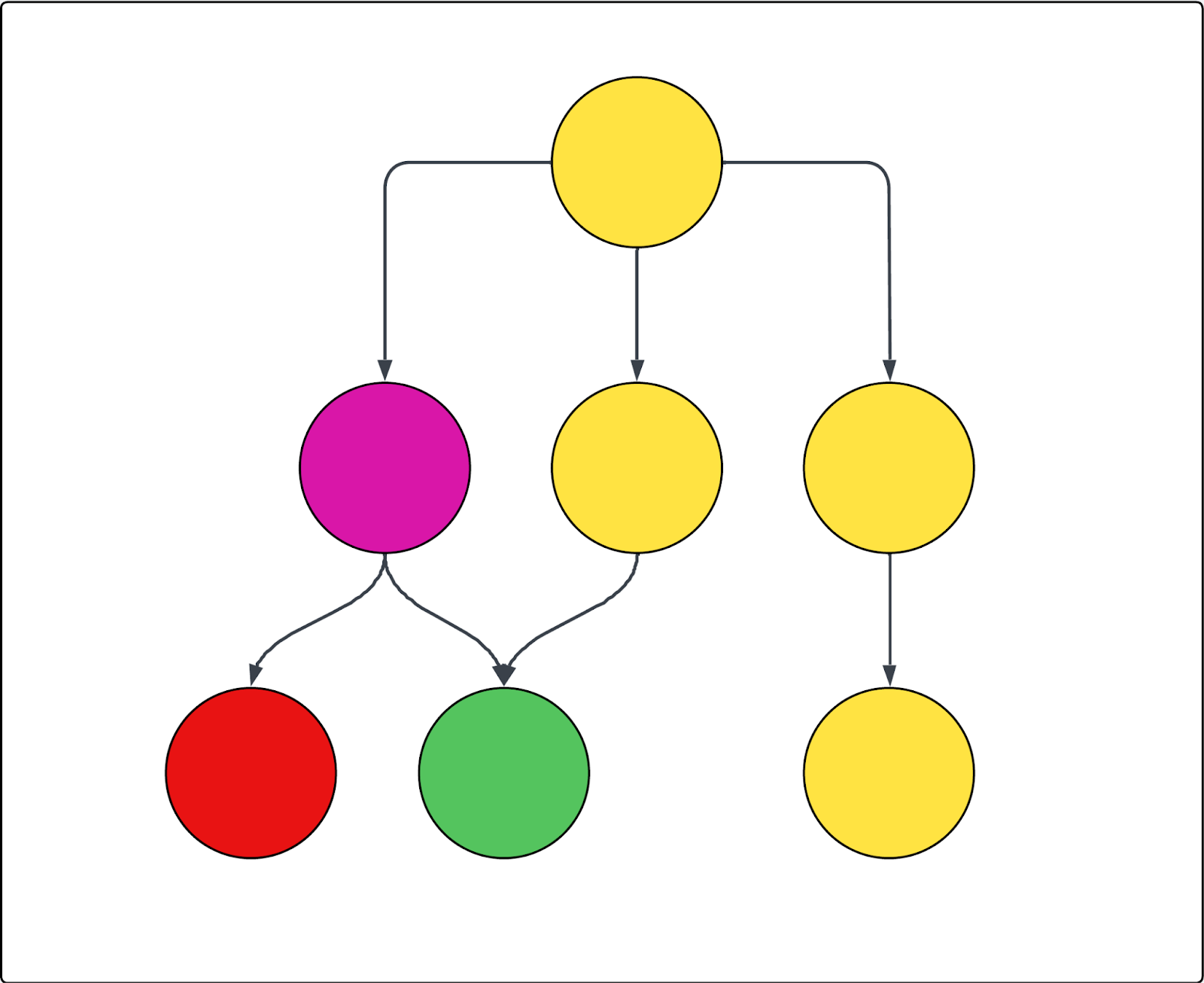
请参阅下图示例。每个圆圈代表一个页面,每个箭头代表来自该页面的一个链接。如果抓取从顶部页面开始(如 中,它是唯一的 开始 URL),并且紫色页面被排除在外,则以下为 true:
- 红色页面无法抓取。
- 将对所有黄页进行抓取。
- 绿色页面也会被抓取,即使它是从排除的紫色页面链接的,因为它也是从包含的黄页之一链接的。
抓取正确的页面,但包含错误的内容
如果抓取程序返回正确页面,但返回这些页面内的错误内容,则 高级抓取程序设置 将提供用于查找并包含或排除此类内容的工具。您需要为要包含或排除的元素找到正确的 CSS 选择器,然后将其插入到正确的设置中。要做到这一点,您需要了解什么是 CSS 选择器,以及如何找到它。
本部分包含以下主题:
了解并查找 CSS 选择器
关于 CSS 选择器
CSS 选择器是用于选择并定位网页上特定 HTML 元素的模式。借助它们,您可以从复杂的网页中轻松查找并提取所需的数据。
在网络抓取和抓取中,CSS 选择器可通过查明页面结构的确切部分来帮助提取数据,例如 <div>, <span>、 或带有特定类和 ID 的元素。例如,选择器 .product-title 将所有 为 的元素定位到 "product-title".井号 (#) 用于按元素的唯一 ID 选择元素。例如, #main-header 选择带有 的元素 id="main-header".
查找 CSS 选择器
首先,您需要找到要使用的 CSS 选择器。以下说明假定您使用的是 Chrome 网络浏览器。但是,对于其他浏览器,步骤可能类似。
查找 CSS 选择器
- 在要定位到的网页上找到文本或可单击项目。
-
直接右键单击该元素,然后选择 检查。
Chrome 开发者工具面板随即打开,匹配的代码段将突出显示。
-
在 DevTools 面板中,右键单击突出显示的代码,然后选择 复制>复制选择器。
现在您已将 CSS 选择器复制到剪贴板。
验证 CSS 选择器
找到 CSS 选择器后,最好进行验证。
验证 CSS 选择器
-
在 DevTools 仍然打开的情况下,按 Ctrl+F(在 Windows 或 Linux 上)或 Cmd+F(在 Mac 上)。
这将激活 DevTools 面板元素标签内的搜索栏。
- 将您刚复制的 CSS 选择器粘贴到此搜索框中。
- 验证 HTML 和页面本身(通常带有彩色轮廓)中突出显示的元素是否与您的预期匹配。
如果仅突出显示所需的元素,则选择器是准确的。如果突出显示的元素过多或错误,请尝试使用父元素或调整选择。
您可以选择测试不同的选择器。有时,选择器越短越具体,效果会更好。您可以单击 HTML 中的父元素或子元素,查看其 CSS 类或 ID,并尝试复制这些选择器。
接下来的两部分将引导您了解如何使用这些选择器来定位您要抓取或不想抓取的内容。
抓取正在跳过页面内容
如果您的抓取有正确的页面,但缺少这些页面的内容,以下 高级抓取程序设置 可能会有所帮助:
- HTML 转换程序抓取程序最初会抓取页面中的所有 HTML,然后应用 HTML 变换器移除无关内容。有时,转换工具可能做得太过分,会移除您实际要保留的内容。因此,当内容缺失时,首先要将此设置转为“无”,这样就不会移除内容,然后 检查导入概要。
- 保留 HTML 元素通过提供一个或多个 CSS 选择器,仅保留特定的 HTML 元素。所有其它内容都将被忽略,帮助您专注于相关信息。
-
展开可点击元素使用此选项捕获可折叠面板和下拉菜单背后的内容。默认设置旨在涵盖遵循标准 Web 开发实践并将下拉菜单定义为
aria=false.也就是说,抓取程序遇到此类元素时会单击打开。输入可单击元素的 CSS 选择器,例如可展开隐藏内容的按钮或链接。这有助于抓取程序捕获所有文本。确保选择器有效。 - 使容器具有粘性如果可展开内容在单击另一个元素时关闭,您可以使用此设置确保此类元素在单击后保持打开状态。因此,再次输入 CSS 选择器,使之成为可单击且在单击其他元素后仍保持打开状态的元素,例如展开隐藏内容的按钮或链接。
-
等待选择器 和 软等待选择器:如果页面中的动态内容仅在特定时间后显示,则抓取程序可能会错过该内容,除非指示其等待。有两种方法可以使用 CSS 选择器告诉抓取程序等待。
- 等待动态内容 设置可确定抓取程序等待的时间。如果在时限前未找到选择器,则视为请求失败,并会重试数次。
- “软等待”选择器会限制 抓取程序等待的时间,但也可确保抓取程序在找不到选择器的情况下继续抓取页面,从而避免抓取失败。
- 这些设置不适用于原始 HTTP 客户端 (Cheerio) 抓取程序类型,因为它不会获取任何 JavaScript 内容。
- 最大滚动高度:有些页面过长,导致抓取程序在结束前放弃。如果在某个点以下缺失内容,您可以使用此设置强制抓取程序滚动指定的像素数。
抓取返回的页面内容过多或杂乱
如果您的抓取有正确的页面,但这些页面上有多余或不必要的内容(例如,市场营销文本、导航、页首或页脚,甚至是 Cookie),且您怀疑会干扰人工智能专员的答案,请使用以下 高级抓取程序设置 以排除该内容:
- 保留 HTML 元素通过提供一个或多个 CSS 选择器,仅保留特定的 HTML 元素。所有其它内容都将被忽略,帮助您专注于相关信息。对于许多帮助中心而言,这是最简单的方法,可确保主要文章内容具有针对性,同时避免导航、相关文章以及不必要的横幅和页首。
- 移除 HTML 元素使用 CSS 选择器指定要从抓取中移除的 HTML 元素。这是排除特定已知内容最精确、最有效的方法。
翻译免责声明:本文章使用自动翻译软件翻译,以便您了解基本内容。 我们已采取合理措施提供准确翻译,但不保证翻译准确性
如对翻译准确性有任何疑问,请以文章的英语版本为准。