知识源是您的人工智能专员用于创建人工智能生成的客户问题答案的信息。为人工智能专员添加知识源可使其生成答案以帮助客户,而无需您为每个回复都编写脚本。
本文章包含以下主题:
相关文章:
关于知识来源
您可以将以下类型的知识源连接到人工智能专员:
您可以将多个知识源连接到一个人工智能专员。例如,您可以连接多个 Zendesk 帮助中心、多个外部来源,或两者的组合。尽管如此,我们还是建议您将知识来源的总数控制在合理范围内。在某些情况下,来源过多会导致准确性降低并延迟增加。
人工智能专员需要连接一个或多个知识源才能创建人工智能生成的答案。如果您在对话中添加生成式回复块,或指示生成式程序生成知识回复,而您没有已连接的知识来源,则会发生技术错误。
当人工智能专员搜索已连接的帮助中心时,它将搜索执行搜索时帮助中心的当前内容。但是,当人工智能专员搜索已连接的外部知识源时,它会搜索截至上次同步(通常每 24 小时进行一次)时的可用信息。
如果您使用的是受限帮助中心内容,人工智能专员将遵根据文章查看权限进行回复,即:
- 如果客户已通过身份验证,人工智能专员可以使用相关受限文章生成回复。
- 如果客户未经身份验证,人工智能专员只能使用公开文章生成回复。
有关更多信息,请参阅在人工智能专员回复中使用受限的帮助中心内容。
将 Zendesk帮助中心连接到人工智能专员
您可以将与您的任意品牌关联的 Zendesk帮助中心连接到人工智能专员。然后,人工智能专员可以使用帮助中心内容生成客户问题的答案。
您必须先激活帮助中心,然后才能将其连接到人工智能专员。
连接 Zendesk帮助中心
- 在人工智能专员工作区中,选择您要处理的人工智能专员。
- 单击
 ,然后选择知识来源。
,然后选择知识来源。 - 单击编辑来源。
随即出现一个知识来源对话框。
- 在顶部的字段中,选择帮助中心。
- 在列表中,选择您要连接到人工智能专员 的Zendesk帮助中心。
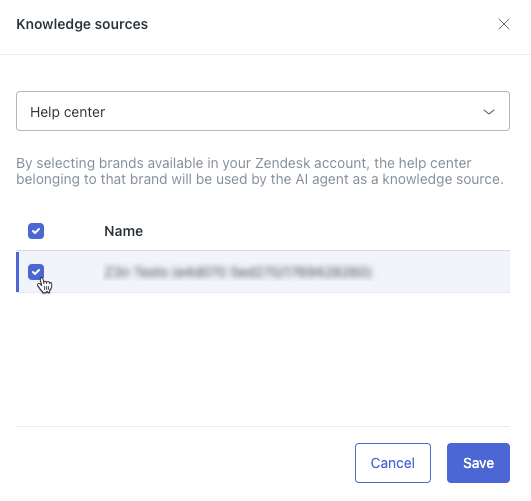 提示:如果您没有看到帮助中心,请确保您已激活它。
提示:如果您没有看到帮助中心,请确保您已激活它。 - 单击保存。
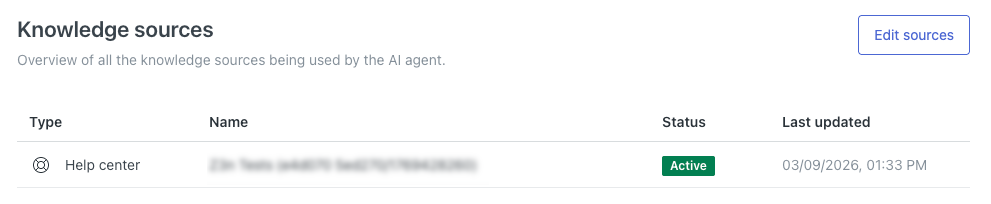
您的帮助中心将显示在知识来源列表中。
将外部知识源连接到人工智能专员
您还可以将外部知识源连接到人工智能专员,以便人工智能专员在生成客户问题的答案时使用来自该来源的信息。
连接外部知识源
- 将一个外部知识源连接到您的 Zendesk 帐户(如果您还没有这样做)。
- 在人工智能专员工作区中,选择您要处理的人工智能专员。
- 单击,然后选择知识来源。
- 单击编辑来源。
随即出现一个知识来源对话框。
- 在顶部的字段中,选择外部内容。
- 在列表中,根据需要展开外部知识源的类型,然后选择您要连接到人工智能专员 的来源。
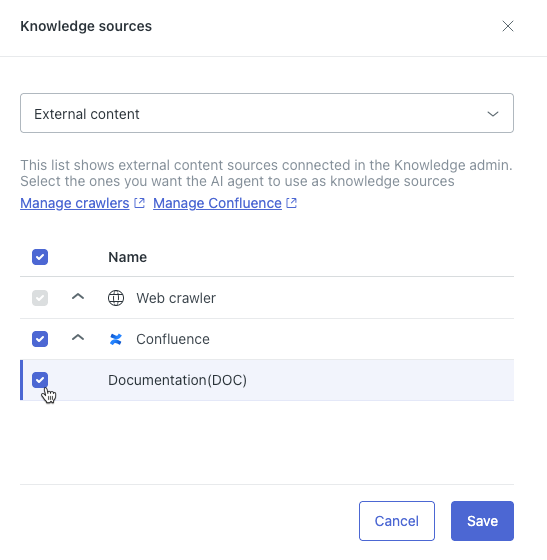
- 单击保存。
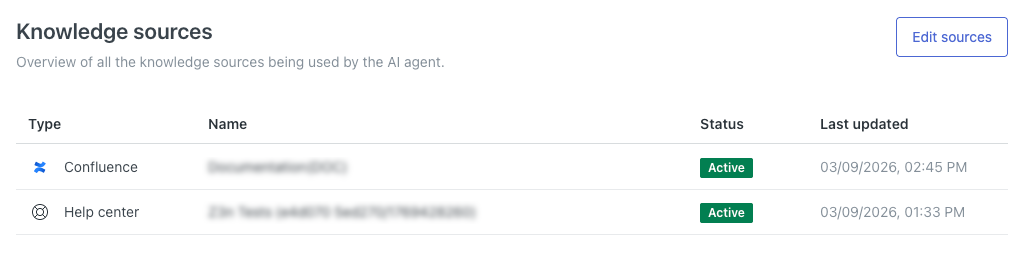
您的外部知识源将显示在知识源列表中。
断开与知识来源的连接
您可以断开知识源与人工智能专员的连接,以防止人工智能专员在生成客户问题的答案时使用该知识源中的信息。
断开与知识来源的连接
- 在人工智能专员工作区中,选择您要处理的人工智能专员。
- 单击,然后选择知识来源。
- 单击编辑来源。
随即出现一个知识来源对话框。
- 在顶部的字段中,选择帮助中心或外部内容。
在列表中,取消选择您要断开连接的知识来源。
- 单击保存。
已断开连接的知识来源将从知识来源列表中移除。
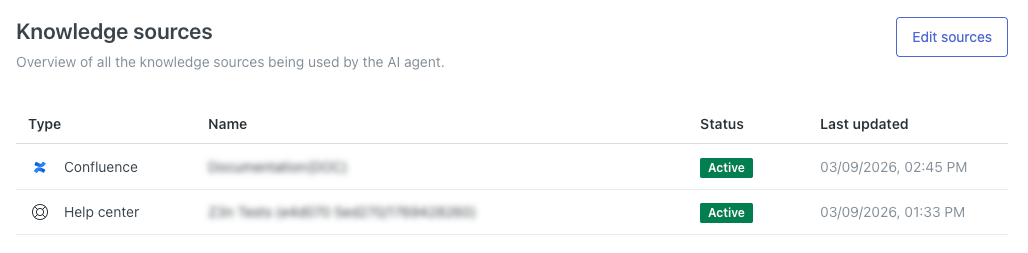
查看所有已连接的知识来源
在人工智能专员的设置中,您可以查看当前已连接的所有内容来源。人工智能专员将使用这些来源生成客户问题的答案。
查看所有已连接内容来源
- 在人工智能专员工作区中,选择您要处理的人工智能专员。
-
单击,然后选择知识来源。
此页面显示当前已连接到该人工智能专员的所有知识源列表。
翻译免责声明:本文章使用自动翻译软件翻译,以便您了解基本内容。 我们已采取合理措施提供准确翻译,但不保证翻译准确性
如对翻译准确性有任何疑问,请以文章的英语版本为准。