Zusammenfassung: ◀▼
Sie können mehrere Webcrawler einrichten, um Inhalte von externen Websites zu indizieren, damit sie dann in Help-Center-Suchen und in den Kontextfenstern für Agenten berücksichtigt werden. Crawler nutzen Sitemaps, um Seiten zu finden, und können ganze Websites oder nur bestimmte URLs indizieren. Die indizierten Inhalte werden in den Suchergebnissen mit Filteroptionen angezeigt. Crawler verwenden kein JavaScript und benötigen öffentlich zugängliche Seiten. Sie verwalten Crawler, planen regelmäßige Indizierungen und stellen Konformität mit den Berechtigungen der jeweiligen Website sicher.
Mit einem Webcrawler können Sie externe Inhalte ganz ohne Entwicklerressourcen crawlen und für die Verwendung in Ihrem Zendesk-Konto indizieren. Sie können mehrere Crawler einrichten, um verschiedene Inhalte in einer oder mehreren Websites zu indizieren. Außerdem haben Sie die Möglichkeit, eine Liste bestimmter URLs festzulegen, damit Sie nicht die gesamte Website crawlen müssen.
Wenn Benutzer in Ihrem Help Center eine Suche durchführen, werden externe Inhalte, die der Crawler gefunden hat, entsprechend ihrer Relevanz auf der Seite mit den Suchergebnissen angezeigt. Benutzer können die Ergebnisse filtern und auf die Links klicken, um die externen Inhalte in einer neuen Browser-Registerkarte anzuzeigen.
Überblick über Webcrawler
Sie können bis zu 20 Webcrawler einrichten, um externe Inhalte auf einer oder mehreren Websites zu indizieren. Inhalte gecrawler Websites und Webseiten werden überall dort bereitgestellt, wo Sie externe Inhalte in Ihrem Zendesk-Konto verwenden. Externe Websites, auf die der Crawler zugreifen soll, müssen eine Sitemap aufweisen, in der die Seiten für den Webcrawler aufgelistet sind. Seiten, auf die der Crawler zugreifen soll, müssen außerdem öffentlich sein (nicht authentifiziert).
- die gesamte Website crawlen, lokalisiert der Crawler die Sitemap der angegebenen Start-URL bzw. die angegebene Sitemap und arbeitet automatisch alle Webseiten dieser Website ab.
- den Crawl auf einzelne Seiten beschränken möchten, können Sie bis zu fünf URLs angeben. Sobald Sie mehr als eine URL eingeben, wird die Option Crawl auf diese URLs beschränken automatisch ausgewählt. Wenn Sie nur eine Start-URL eingeben, können Sie diese Option manuell auswählen, um den Crawl auf diese eine Seite zu beschränken. Bei Eingabe einer Sitemap wird diese Option deaktiviert und ist nicht auswählbar, da der Crawler in diesem Fall alle in der Sitemap angegebenen Seiten crawlen muss.
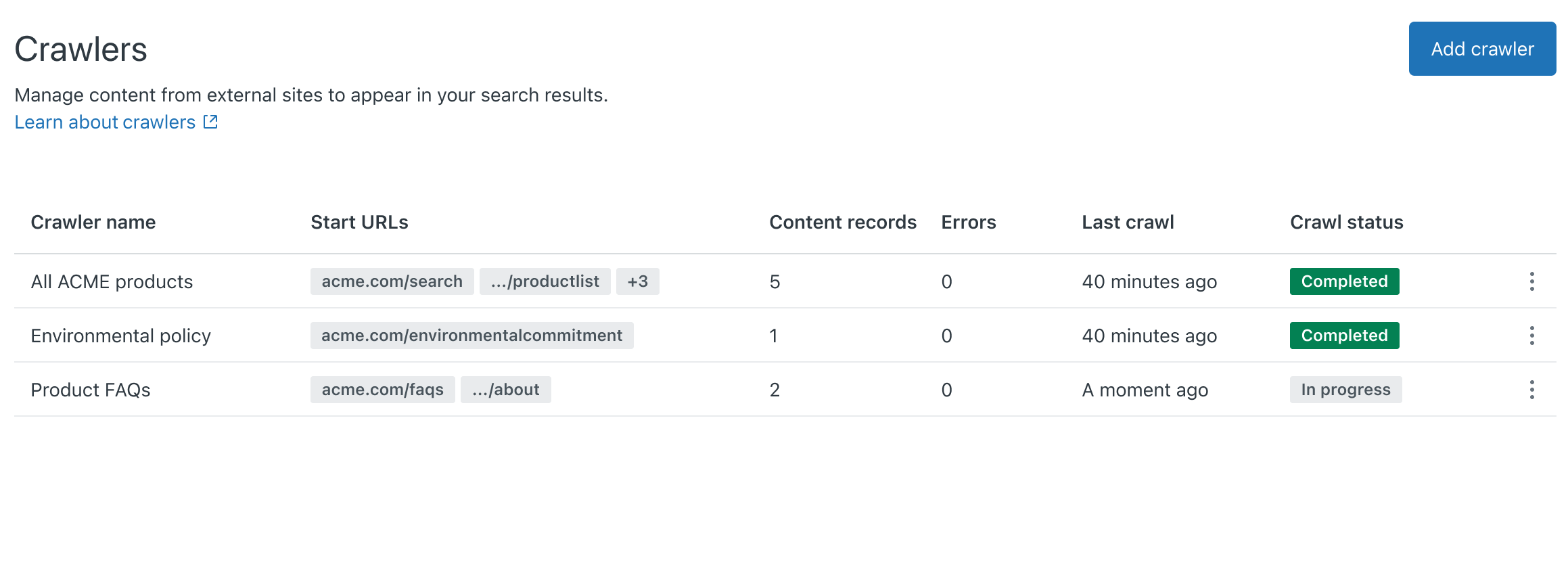
Wenn Sie einen neuen Crawler erstellen, wird anhand des ihm zugewiesenen Namen ein Quellenwert erstellt. Quellenwerte dienen als Filter für Ihre Help-Center-Suche. Wenn Sie den Namen später ändern möchten, können Sie ihn jederzeit bearbeiten oder durch einen anderen Quellennamen ersetzen. Weitere Informationen finden Sie unter Verwalten von Webcrawlern.
Konfigurierte Crawler werden in regelmäßigen Zeitabständen ausgeführt, besuchen die in der Sitemap aufgeführten Seiten und übernehmen deren Inhalte in die Indizes für die Help-Center-Suche. Webcrawler indizieren alle beim erstmaligen Laden im Seitenquelltext enthaltenen Informationen, auch wenn diese durch ein UI-Element, etwa ein Akkordeon, verborgen sind. Da Crawler allerdings kein JavaScript ausführen, indizieren sie keine Inhalte, die mittels JavaScript oder dynamisch nach dem ersten Laden der Seite dargestellt werden.
Webcrawler indizieren keine Links auf den von ihnen besuchten Seiten, sondern beschränken sich ausschließlich auf die Seiten in der Sitemap, für die sie eingerichtet wurden. Wenn der Crawler bei einem regelmäßigen Crawl keine Informationen von einer Website sammeln kann (z. B. wenn die Website nicht erreichbar ist oder Netzwerkprobleme vorliegen), bleiben im Help Center die Ergebnisse des vorherigen Crawls verfügbar und können weiterhin durchsucht werden.
Einrichten eines Webcrawlers
- Der Webcrawler funktioniert nicht mit Websites, die die Komprimierungscodierung gzip verwenden. Von diesen Websites werden keine Suchergebnisse angezeigt.
- Eine Crawl-Verzögerung („crawl-delay“) wird vom Webcrawler nicht beachtet, wenn sie in robots.txt-Einträgen für externe Websites festgelegt ist.
- Das Tag „changefreq” hat keinerlei Auswirkungen auf den Webcrawler.
So richten Sie einen Webcrawler ein
-
Klicken Sie in der Seitenleiste von Wissensadministrator auf Einstellungen (
 ).
).
- Klicken Sie auf Sucheinstellungen.
- Klicken Sie unter Crawler auf Verwalten.
- Klicken Sie auf Crawler hinzufügen.

- Klicken Sie auf Weiter.
- Geben Sie unter Inhalt von einer Website synchronisieren Folgendes ein:
- Den Crawler-Namen, den Sie dem Crawler zuweisen möchten. Dieser Name wird in der Crawler-Verwaltungsliste angezeigt und verwendet, um den Quellenwert für das Filtern Ihrer Help-Center-Suche zu erstellen.
-
Die Start-URLs der Website oder der Seiten, die Sie crawlen möchten. Wenn Sie:
- eine gesamte Website crawlen möchten, geben Sie die primäre Domäne (z. B. zendesk.com) oder den Pfadnamen der Sitemap (z. B. zendesk.com/sitemap.xml) ein.
-
den Crawl auf einzelne Seiten beschränken möchten, geben Sie die Domäne/Webseite in dieses Feld ein (z. B. test.com/faq.htm). Klicken Sie gegebenenfalls auf + Weitere hinzufügen. Sie können insgesamt fünf URLs angeben.
Wenn Sie diese Option wählen, durchsucht und indiziert der Crawler nur die bei der Einrichtung angegebenen Start-URLs.
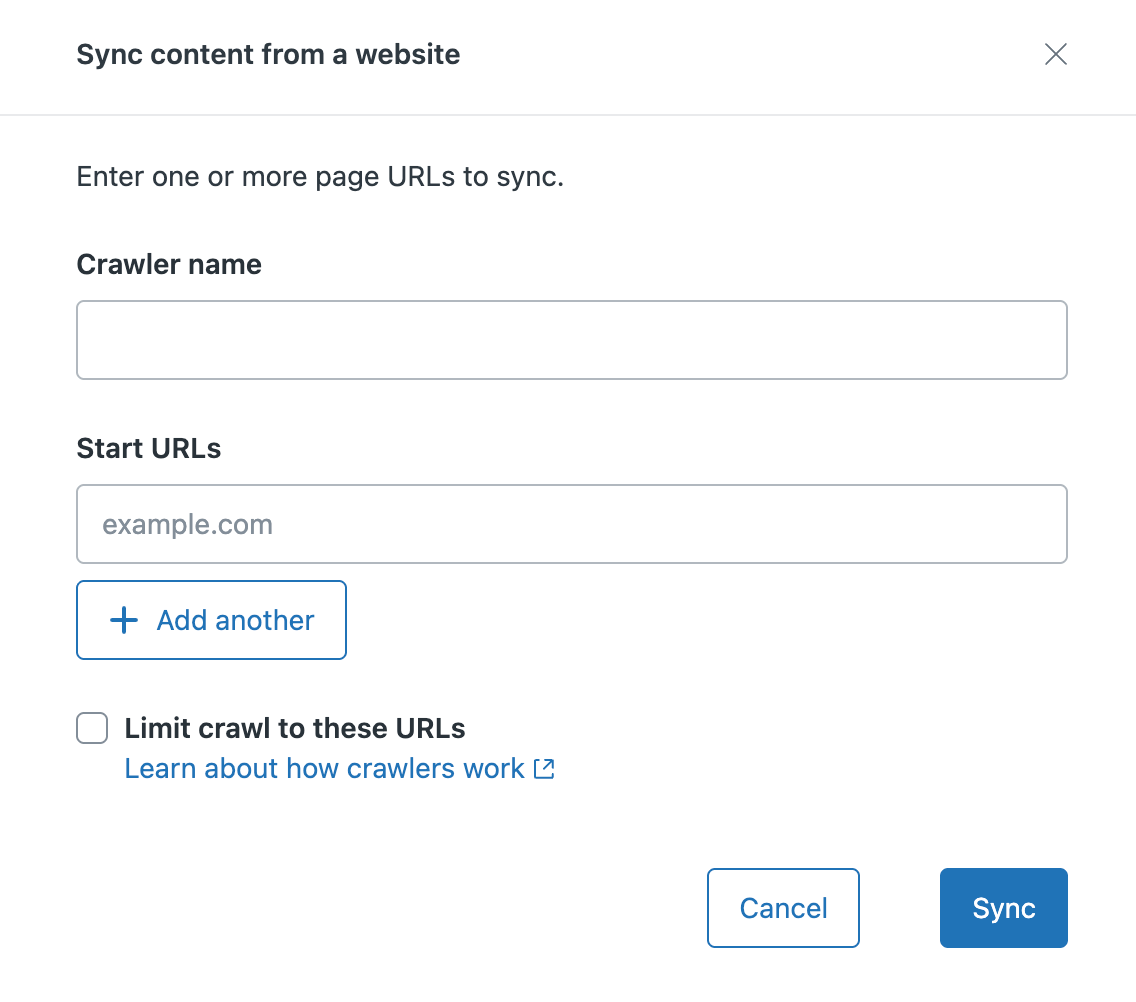
- Klicken Sie auf Synchronisierung. Der Webcrawler wird der Seite „Crawler“ hinzugefügt und innerhalb von 24 Stunden versuchen, die angegebene Sitemap abzurufen und zu analysieren. Wenn er die Sitemap erfolgreich verarbeiten konnte, beginnt der Crawler, die Seiten zu crawlen und ihren Inhalt zu indizieren. Andernfalls erhält der Inhaber des Crawlers eine E-Mail-Benachrichtigung mit Tipps zur Behebung des Problems. Anschließend wird der Crawler den Versuch in regelmäßigen Abständen wiederholen.Hinweis: Der User Agent für den Webcrawler ist „Zendesk/External-Content“. Um zu verhindern, dass der Crawler durch eine Blockierungsanfrage der Firewall behindert wird, tragen Sie Zendesk/External-Content in Ihre Zulassungsliste ein.
- Help-Center-Suche: Sie müssen die Inhalte auswählen, die in den Suchergebnisse berücksichtigt bzw. außer Acht gelassen werden sollen. Weitere Informationen finden Sie unter Berücksichtigen externer Inhalte in den Help-Center-Suchergebnissen.
- Bereich „Wissen“ im Kontextfenster für Agenten: Befolgen Sie die Anweisungen unter Konfigurieren des Abschnitts „Wissen“ im Kontextfenster.