Puede usar un rastreador web para importar contenido en su agente IA. Así su agente IA podrá crear respuestas generadas por IA para las preguntas de los clientes basándose en información de sitios web externos.
Este artículo le ayudará a resolver los problemas que puedan surgir al importar contenido para un agente IA con ayuda de un rastreador web y contiene los siguientes temas:
El rastreo falló porque se agotó el tiempo de espera
Si un rastreo web falla después de varias horas, normalmente se debe a que se agotó el tiempo de espera. De manera predeterminada, los rastreos están limitados a cinco horas. Si la falla ocurrió cinco horas después del inicio de la importación, lo más probable es que se haya agotado el tiempo de espera.
Si esto sucede, pruebe estos pasos de resolución:
- Si el sitio web no utiliza JavaScript, establezca el Tipo de rastreador en Cliente HTTP sin procesar (Cheerio), un rastreador mucho más rápido, y vuelva a intentar hacer el rastreo.
- Si sabe que el sitio incluye contenido que no se necesita, consulte El rastreo incluye páginas innecesarias.
- Divide el rastreo en dos o más rastreos separados (usando las opciones de configuración Incluir URL o Excluir URL) que extraigan datos de distintas partes del sitio web.
Al rastreo le faltan páginas
Si faltan URL o artículos completos en el rastreo, aumente el alcance del rastreo usando las opciones URL de inicio e Incluir URL. Si está seguro de que la configuración es correcta pero aún faltan artículos, verifique el número de páginas rastreadas en el resumen de importación. Si se encuentra alrededor del Máximo de páginas predeterminado (4000), intente aumentar este límite.
El rastreo incluye páginas innecesarias
Si el rastreo incluye más páginas o artículos de lo necesario (por ejemplo, contenido repetitivo o inaplicable, como páginas en inglés cuando solo se necesita español, o contenido que el agente IA no necesita para responder a las preguntas de los clientes), utilice la opción Excluir URL.
Algo que se debe evitar es excluir accidentalmente ciertas subpáginas. Los URL de inicio definen dónde debe comenzar el rastreador. Luego sigue todos los vínculos de esa página y las páginas subsiguientes, hasta la Profundidad máxima de rastreo especificada. Sin embargo, si se excluyen páginas, nunca se rastrearán las páginas vinculadas solo desde las páginas excluidas a menos que se especifique por separado que son URL de inicio.
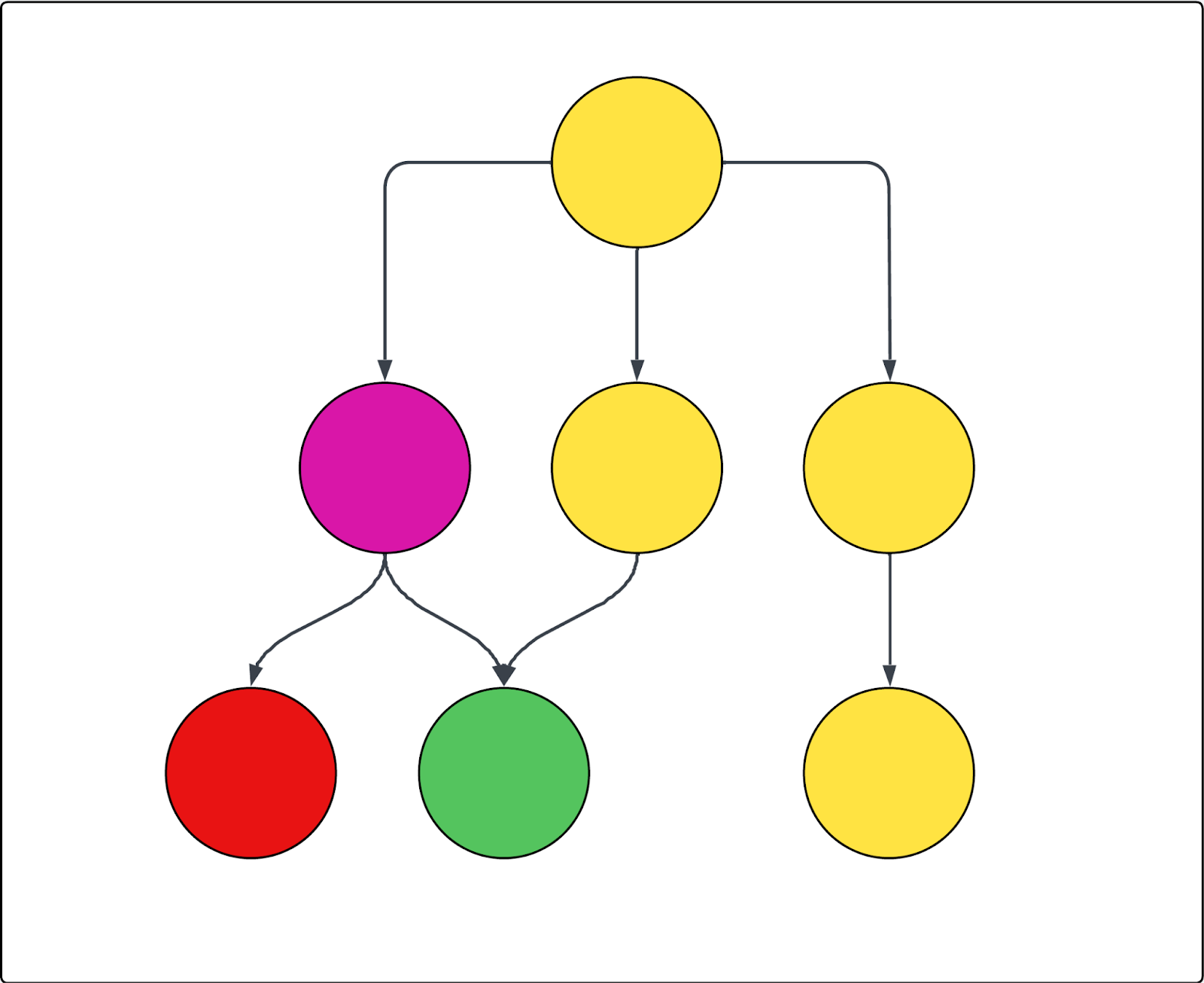
Vea el diagrama a continuación como ejemplo. Cada círculo representa una página, y cada flecha, un vínculo desde esa página. Si el rastreo comienza en la página superior (que es el único URL de inicio) y se excluye la página morada, lo siguiente es verdadero:
- No se puede rastrear la página roja
- Todas las páginas amarillas se rastrean
- La página verde también se rastrea, aunque esté vinculada desde la página morada excluida, porque también está vinculada desde una de las páginas amarillas incluidas.
El rastreo incluye las páginas correctas pero el contenido equivocado
Si el rastreo devuelve las páginas correctas, pero el contenido incorrecto dentro de esas páginas, las opciones avanzadas del rastreador incluyen herramientas para buscar e incluir o excluir dicho contenido. Debe buscar el selector CSS correcto para el elemento que desea incluir o excluir y luego insertarlo en la opción correspondiente. Para ello, es útil comprender qué es un selector CSS y cómo encontrarlo.
En esta sección se tratan los siguientes temas:
Comprender y encontrar los selectores CSS
En esta sección se presentan los selectores CSS y se explica cómo encontrar el correcto. Si ya conoce esta información, vaya directamente a las secciones de resolución de problemas a continuación.
En esta sección se tratan los siguientes temas:
Acerca de los selectores CSS
Los selectores CSS son patrones que se usan para seleccionar elementos HTML específicos en una página web y enfocarse en ellos. Hacen que sea más fácil encontrar y extraer los datos exactos que se necesitan de páginas web complejas.
En el rastreo web y la extracción, los selectores CSS ayudan a extraer datos porque identifican las partes exactas de la estructura de una página, como <div>, <span>, o elementos que tienen ciertas ID y clases. Por ejemplo, el selector .product-title se enfoca en todos los elementos que tienen la clase "product-title". El signo de número o almohadilla (#) se usa para seleccionar elementos en función de su ID única. Por ejemplo, #main-header selecciona el elemento que tiene id="main-header".
Buscar un selector CSS
Primero, se debe buscar el selector CSS que se desea usar. Las siguientes instrucciones suponen que se está usando el navegador web Chrome. Sin embargo, los pasos probablemente sean similares para otros navegadores.
Para buscar un selector CSS:
- Ubique el texto o el elemento en el que se puede hacer clic en la página web en la que desea enfocarse.
-
Haga clic con el botón derecho directamente en ese elemento y seleccione Inspeccionar.
Se abre el panel Chrome DevTools y se resalta el fragmento de código coincidente.
-
En el panel DevTools, haga clic con el botón derecho en el código resaltado y seleccione Copiar > Copiar selector.
Ahora el selector CSS ya está copiado en el portapapeles.
Verificar un selector CSS
Después de encontrar el selector CSS, es conveniente verificarlo.
Para verificar el selector CSS:
-
Con DevTools todavía abierto, presione Ctrl+F (en Windows o Linux) o Cmd+F (en Mac)
Esto activa una barra de búsqueda dentro de la pestaña Elementos del panel DevTools.
- Pegue el selector CSS que acaba de copiar en este cuadro de búsqueda
- Verifique que los elementos resaltados en el HTML y en la página misma (a menudo con un contorno de color) coincidan con lo que se espera.
Si solo está resaltado el elemento que desea, quiere decir que el selector es correcto. Si se han resaltado demasiados elementos o los elementos incorrectos, pruebe con un elemento principal o ajuste su selección.
Si lo desea, puede probar distintos selectores. A veces, los selectores más cortos o específicos funcionan mejor. Puede hacer clic en los elementos principal o secundarios en el HTML para ver sus ID o clases CSS e intentar copiar esos selectores también.
Las dos secciones siguientes explican cómo usar estos selectores para enfocarse en el contenido que desea o no desea rastrear.
El rastreo está omitiendo contenido de la página
Si el rastreador tiene las páginas correctas, pero a esas páginas les falta contenido, las siguientes opciones avanzadas del rastreador pueden ser de utilidad:
- Transformador HTML: el rastreador extrae inicialmente todo el HTML de una página y luego aplica un transformador HTML para eliminar el contenido innecesario. A veces el transformador puede ir demasiado lejos y eliminar contenido que en realidad se desea conservar. Por lo tanto, lo primero que se debe intentar cuando falta contenido es cambiar esta opción a Ninguno para que no se elimine ningún contenido y luego mirar el resumen de importación.
- Conservar elementos HTML: mantenga solo elementos HTML específicos proporcionando uno o más selectores de CSS. El resto del contenido se ignora para que pueda concentrarse en la información pertinente
-
Expandir elementos en los que se puede hacer clic: utilice esta opción para capturar el contenido que se encuentra detrás de los acordeones y los menús desplegables. La configuración predeterminada está pensada para incluir las páginas web que siguen las prácticas de desarrollo web estándar y definen los menús desplegables como
aria=false. Por lo tanto, si el rastreador encuentra ese tipo de elemento, se hará clic en él para abrirlo. Ingrese un selector CSS para cualquier elemento en el que se debe hacer clic, como botones o vínculos que amplían el contenido oculto. Esto ayuda al rastreador a capturar todo el texto. Asegúrese de que el selector sea válido - Hacer que los contenedores sean fijos: si el contenido ampliable se cierra cuando se hace clic en un elemento diferente, puede usar esta opción para asegurarse de que dichos elementos permanezcan abiertos después de hacer clic en ellos. Como antes, ingrese un selector CSS para cualquier elemento en el que se debe hacer clic y que luego debe permanecer abierto incluso después de que se ha hecho clic en otros elementos, como botones o vínculos que amplían el contenido oculto
-
Esperar selector y Espera temporal para selector: Si la página tiene contenido dinámico que aparece solo después de cierto tiempo, es posible que el rastreador la pase por alto a menos que se le indique que espere. Hay dos maneras de decirle al rastreador que espere con un selector CSS.
- La opción Esperar contenido dinámico determina cuánto tiempo debe esperar el rastreador. Si el selector no se encuentra antes del límite de tiempo, se considera una solicitud fallida y se reintenta un par de veces
- La opción Espera temporal para selector determina cuánto tiempo debe esperar el rastreador, pero también se asegura de que el rastreador continúe rastreando la página si no se encuentra el selector, lo que evita fallas.
- Estas opciones no funcionan con el tipo de rastreador Cliente HTTP sin procesar (Cheerio) porque este no obtiene contenido de JavaScript.
- Altura máxima de desplazamiento: algunas páginas son tan largas que el rastreador se da por vencido antes de llegar al final. Si falta contenido después de un punto determinado, puede usar esta opción para forzar al rastreador a desplazarse por un número específico de píxeles.
El rastreo está devolviendo demasiado contenido o contenido desorganizado
Si el rastreo tiene las páginas correctas, pero hay contenido adicional o innecesario en esas páginas (por ejemplo, texto de marketing, navegación, encabezados o pies de página, o incluso cookies) que podría estar interfiriendo con las respuestas del agente IA, utilice las siguientes opciones avanzadas del rastreador para excluir ese contenido:
- Conservar elementos HTML: mantenga solo elementos HTML específicos proporcionando uno o más selectores de CSS. El resto del contenido se ignora para que pueda concentrarse en la información pertinente. En muchos centros de ayuda, este es el método más sencillo para asegurarse de que el contenido del artículo principal esté bien enfocado y evitar elementos de navegación, artículos relacionados y pancartas y encabezados innecesarios
- Eliminar elementos HTML: utilice selectores CSS para especificar qué elementos HTML se deben eliminar del rastreo. Esta es la manera más precisa y eficaz de excluir contenido conocido especificado
Artículos relacionados:
- Importación de contenido para los agentes IA con un rastreador web: mejores prácticas
- Administración de fuentes de conocimiento importadas para los agentes IA
Descargo de responsabilidad de la traducción: Este artículo ha sido traducido usando software de traducción automática para proporcionar una idea básica del contenido. Se han realizado esfuerzos razonables para proporcionar una traducción exacta, sin embargo, Zendesk no garantiza la exactitud de la traducción.
Si surge alguna pregunta relacionada con la exactitud de la información incluida en el artículo traducido, consulte la versión en inglés del artículo, que es la versión oficial.