Las fuentes de conocimiento son la información que usa el agente IA para crear respuestas generadas por IA a las preguntas de los clientes. Si se agregan fuentes de conocimiento al agente IA, este podrá generar respuestas que ayudan a los clientes sin que sea necesario redactar una respuesta para cada pregunta.
En este artículo se tratan los siguientes temas:
- Acerca de las fuentes de conocimiento
- Conectar un centro de ayuda de Zendesk con un agente IA
- Conectar una fuente de conocimiento externa con un agente IA
- Desconectar una fuente de conocimiento
- Importar una fuente de conocimiento (heredado)
- Ver todas las fuentes de conocimiento conectadas
Artículo relacionado:
Acerca de las fuentes de conocimiento
Es posible conectar los siguientes tipos de fuentes de conocimiento a un agente IA:
- Centros de ayuda de Zendesk: el centro de ayuda asociado con su cuenta de Zendesk (o una marca específica, si ha configurado varias marcas).
- Fuentes de conocimiento externas: el contenido de fuentes externas que se transfiere a su cuenta de Zendesk a través de un rastreador web o un conector de conocimiento.
Se pueden conectar varias fuentes de conocimiento a un solo agente IA (por ejemplo, varios centros de ayuda de Zendesk, varias fuentes externas o una combinación de ambos). No obstante, se recomienda mantener el número total de fuentes de conocimiento dentro de un límite razonable. Tener demasiadas fuentes puede, en algunos casos, reducir la precisión y aumentar la latencia.
Cuando un agente IA busca un centro de ayuda conectado, al realizar la búsqueda, busca el contenido actual del centro de ayuda. Sin embargo, cuando un agente IA busca una fuente de conocimiento externa conectada, lo que busca es la información que está disponible desde la última sincronización (el tiempo entre sincronizaciones suele ser de 24 horas).
Si está usando contenido de un centro de ayuda restringido, las respuestas del agente IA respetan los permisos de visualización de artículos, lo que quiere decir lo siguiente:
- Si el cliente está autenticado, el agente IA puede usar los artículos restringidos que le sirvan para generar su respuesta.
- Si el cliente no está autenticado, el agente IA solo puede usar artículos públicos para generar su respuesta.
Si desea más información, consulte Uso de contenido restringido del centro de ayuda en las respuestas del agente IA.
Conectar un centro de ayuda de Zendesk con un agente IA
Se puede conectar un centro de ayuda de Zendesk a un agente IA para que este pueda utilizar el contenido del centro de ayuda al generar respuestas para las preguntas de los clientes.
Tenga en cuenta que el centro de ayuda debe activarse antes de conectarse al agente IA.
Para conectar un centro de ayuda de Zendesk
- En el espacio de trabajo de agentes IA, seleccione el agente IA con el que desee trabajar.
- Haga clic en
 Contenido en la barra lateral y luego seleccione Fuentes de conocimiento.
Contenido en la barra lateral y luego seleccione Fuentes de conocimiento. - Haga clic en Editar fuentes.
Enseguida verá el diálogo Fuentes de conocimiento.
- En el campo de la parte superior, seleccione Centro de ayuda.
- En la lista, seleccione el centro de ayuda de Zendesk al que desea conectar el agente IA.
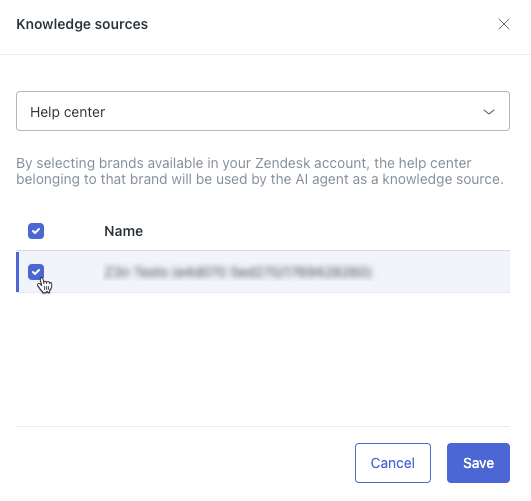 Sugerencia: Si no ve su centro de ayuda, verifique si lo activó.
Sugerencia: Si no ve su centro de ayuda, verifique si lo activó. - Haga clic en Guardar.
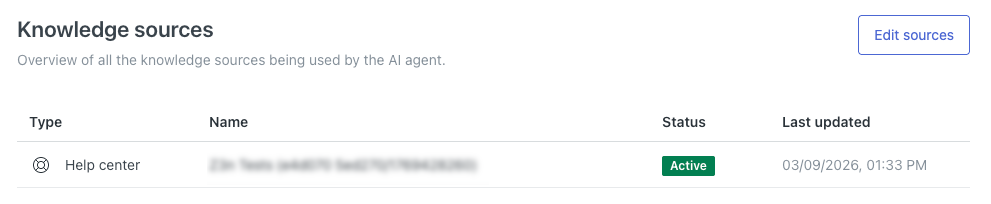
El centro de ayuda aparece en la lista de Fuentes de conocimiento.
Conectar una fuente de conocimiento externa con un agente IA
También se puede conectar una fuente de conocimiento externa a un agente IA para que este pueda utilizar la información de la fuente al generar respuestas para las preguntas de los clientes.
Para conectar una fuente de conocimiento externa
- Si aún no lo ha hecho, conecte una fuente de conocimiento externa con su cuenta de Zendesk.
- En el espacio de trabajo de agentes IA, seleccione el agente IA con el que desee trabajar.
- Haga clic en Contenido en la barra lateral y luego seleccione Fuentes de conocimiento.
- Haga clic en Editar fuentes.
Enseguida verá el diálogo Fuentes de conocimiento.
- En el campo de la parte superior, seleccione Contenido externo.
- En la lista, amplíe el tipo de fuente de conocimiento externa (si es necesario) y luego seleccione la fuente que desea conectar con el agente IA.
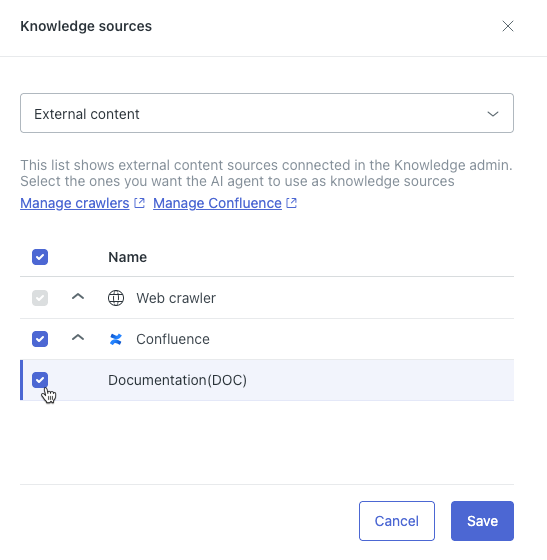
- Haga clic en Guardar.
Su fuente de conocimiento externa aparece en la lista Fuentes de conocimiento.
Desconectar una fuente de conocimiento
Se puede desconectar una fuente de conocimiento de un agente IA para evitar que este use la información de la fuente al generar respuestas para las preguntas de los clientes.
Para desconectar una fuente de conocimiento
- En el espacio de trabajo de agentes IA, seleccione el agente IA con el que desee trabajar.
- Haga clic en Contenido en la barra lateral y luego seleccione Fuentes de conocimiento.
- Haga clic en Editar fuentes.
Enseguida verá el diálogo Fuentes de conocimiento.
- En el campo de la parte superior, seleccione Centro de ayuda o Contenido externo.
En la lista, deseleccione la fuente de conocimiento que desea desconectar.
- Haga clic en Guardar.
La fuente de conocimiento desconectada se elimina de la lista Fuentes de conocimiento.
Importar una fuente de conocimiento (heredado)
Los administradores de clientes pueden importar los siguientes tipos de fuentes de conocimiento para un agente IA.
Importar un centro de ayuda de Zendesk (heredado)
Los administradores de clientes pueden importar un centro de ayuda de Zendesk.
Para importar un centro de ayuda de Zendesk
- En el espacio de trabajo de agentes IA, seleccione el agente IA con el que desee trabajar.
- Haga clic en Contenido en la barra lateral y luego seleccione Fuentes de conocimiento.
- Haga clic en Agregar fuente.
Se abre el panel Agregar fuente.
- En Tipo, seleccione Zendesk.
- En URL del centro de ayuda, ingrese su subdominio, incluida la configuración regional del centro de ayuda (por ejemplo, https://susubdominio.zendesk.com/hc/en-us).
Si no se proporciona una configuración regional, se carga la configuración regional predeterminada del centro de ayuda.
- En Nombre de origen, escriba un nombre para la fuente.
En el panel Informes de los agentes IA, se usa este nombre en los propios informes.
- En Frecuencia de importación, seleccione con qué frecuencia se debe volver a importar el contenido del centro de ayuda:
- Diario: el contenido se vuelve a importar todos los días excepto los domingos y el día 15 del mes. No se recomienda salvo que la fuente de conocimiento se actualice con mucha frecuencia.
- Semanal: el contenido se vuelve a importar todas las semanas (siempre el domingo).
- Mensual: el contenido se vuelve a importar el día 15 de cada mes.
-
Nunca: el contenido se importa una vez y nunca más se vuelve a importar.
No se garantiza el momento exacto de la reimportación. Se procesa durante el día para el que se programó, pero es posible que no siempre esté lista a la misma hora.
Si las importaciones se hacen de manera regular, el agente IA estará siempre al día. Para la mayoría de las organizaciones, un intervalo de una semana o un mes es suficiente. Recuerde que siempre puede volver a importar el contenido manualmente si hay cambios nuevos que tienen que reflejarse antes de la reimportación programada.

- Si su centro de ayuda exige que los usuarios inicien sesión o, por el motivo que sea, desea importar artículos restringidos:
- Active la opción Importar artículos privados.
- Para Correo electrónico, ingrese la dirección de correo electrónico de un usuario que tenga autorización para acceder al contenido restringido.
Suele ser la dirección de correo electrónico de un administrador de Conocimiento.
- En Token de acceso a API, ingrese un token de API generado para este propósito.
- Haga clic en Importar.
Importar un centro de ayuda de Salesforce (heredado)
Los administradores de clientes pueden importar un centro de ayuda de Salesforce.
Para importar un centro de ayuda de Salesforce
- En el espacio de trabajo de agentes IA, seleccione el agente IA con el que desee trabajar.
- Haga clic en Contenido en la barra lateral y luego seleccione Fuentes de conocimiento.
- Haga clic en Agregar fuente.
Se abre el panel Agregar fuente.
- En Tipo, seleccione Salesforce.
- Haga clic en Iniciar sesión en Salesforce.
- Inicie sesión en su entorno de Salesforce.
- En URL del centro de ayuda, ingrese el URL completo de su centro de ayuda de Salesforce.
- En Nombre de origen, escriba un nombre para la fuente.
En el panel Informes de los agentes IA, se usa este nombre en los propios informes.
- En Frecuencia de importación, seleccione con qué frecuencia se debe volver a importar el contenido del centro de ayuda:
- Diario: el contenido se vuelve a importar todos los días excepto los domingos y el día 15 del mes. No se recomienda salvo que la fuente de conocimiento se actualice con mucha frecuencia.
- Semanal: el contenido se vuelve a importar todas las semanas (siempre el domingo).
- Mensual: el contenido se vuelve a importar el día 15 de cada mes.
-
Nunca: el contenido se importa una vez y nunca más se vuelve a importar.
No se garantiza el momento exacto de la reimportación. Se procesa durante el día para el que se programó, pero es posible que no siempre esté lista a la misma hora.
Si las importaciones se hacen de manera regular, el agente IA estará siempre al día. Para la mayoría de las organizaciones, un intervalo de una semana o un mes es suficiente. Recuerde que siempre puede volver a importar el contenido manualmente si hay cambios nuevos que tienen que reflejarse antes de la reimportación programada.
- Haga clic en Importar.
Importar un centro de ayuda de Freshdesk (heredado)
Los administradores de clientes pueden importar un centro de ayuda de Freshdesk.
Para importar un centro de ayuda de Freshdesk
- En el espacio de trabajo de agentes IA, seleccione el agente IA con el que desee trabajar.
- Haga clic en Contenido en la barra lateral y luego seleccione Fuentes de conocimiento.
- Haga clic en Agregar fuente.
Se abre el panel Agregar fuente.
- En Tipo, seleccione Freshdesk.
- En URL del centro de ayuda, ingrese el URL completo de su centro de ayuda de Freshdesk.
Puede agregar todo su centro de ayuda o solo una sección determinada de su centro de ayuda.
- En Nombre de origen, escriba un nombre para la fuente.
En el panel Informes de los agentes IA, se usa este nombre en los propios informes.
- En Frecuencia de importación, seleccione con qué frecuencia se debe volver a importar el contenido del centro de ayuda:
- Diario: el contenido se vuelve a importar todos los días excepto los domingos y el día 15 del mes. No se recomienda salvo que la fuente de conocimiento se actualice con mucha frecuencia.
- Semanal: el contenido se vuelve a importar todas las semanas (siempre el domingo).
- Mensual: el contenido se vuelve a importar el día 15 de cada mes.
-
Nunca: el contenido se importa una vez y nunca más se vuelve a importar.
No se garantiza el momento exacto de la reimportación. Se procesa durante el día para el que se programó, pero es posible que no siempre esté lista a la misma hora.
Si las importaciones se hacen de manera regular, el agente IA estará siempre al día. Para la mayoría de las organizaciones, un intervalo de una semana o un mes es suficiente. Recuerde que siempre puede volver a importar el contenido manualmente si hay cambios nuevos que tienen que reflejarse antes de la reimportación programada.
- En Token de acceso a API, ingrese un token de API generado por usted en Freshdesk para este propósito.
- Haga clic en Importar.
Importar un sitio o espacio de Confluence (heredado)
Los administradores de clientes pueden importar un sitio o espacio de Confluence.
Las conexiones de Confluence se crean y administran en Conocimiento. Antes de conectar un sitio o espacio de Confluence con un agente IA, se debe crear una conexión de Confluence en Conocimiento.
Para el contenido de Confluence no se puede especificar la frecuencia de reimportación, algo que sí se puede hacer con otras fuentes de conocimiento para los agentes IA. Las conexiones de Confluence se sincronizan de manera automática cada 24 horas, pero si lo necesita puede resincronizar el contenido manualmente.
Para importar un sitio o espacio de Confluence
- En el espacio de trabajo de agentes IA, seleccione el agente IA con el que desee trabajar.
- Haga clic en Contenido en la barra lateral y luego seleccione Fuentes de conocimiento.
- Haga clic en Agregar fuente.
Se abre el panel Agregar fuente.
- En Tipo, seleccione Confluence.
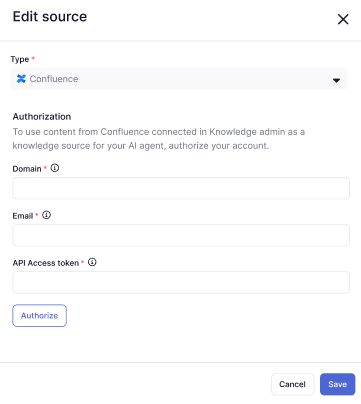
- En Dominio, ingrese el URL de su subdominio de Zendesk (por ejemplo,
https://susubdominio.zendesk.com). - En Correo electrónico, ingrese la dirección de correo electrónico de un administrador de Zendesk.
- En Token de acceso a API, ingrese un token de API generado para este propósito.
- Haga clic en Autorizar.
- Seleccione un sitio o un espacio de Confluence que ya esté conectado a su cuenta de Zendesk o cree una nueva conexión de Confluence.
Puede seleccionar más de uno.
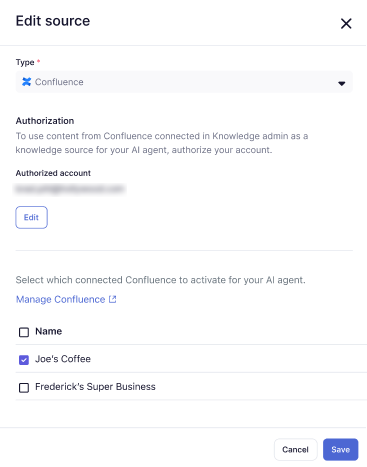
- Haga clic en Guardar.
El sitio o espacio de Confluence que seleccione se agrega a su lista de fuentes de conocimiento.
Importar un archivo CSV (heredado)
Los administradores de clientes pueden importar un archivo CSV como una fuente de conocimiento.
Para importar un archivo CSV
- En el espacio de trabajo de agentes IA, seleccione el agente IA con el que desee trabajar.
- Haga clic en Contenido en la barra lateral y luego seleccione Fuentes de conocimiento.
- Haga clic en Agregar fuente.
Se abre el panel Agregar fuente.
- En Tipo, seleccione Archivo (CSV).
- Haga clic en Seleccionar archivo CSV como fuente de conocimiento.
- Seleccione el archivo CSV que desea importar.
Consulte Formato necesario para el archivo CSV para asegurarse de que su archivo esté bien formateado.
- En Nombre de origen, escriba un nombre para la fuente.
En el panel Informes de los agentes IA, se usa este nombre en los propios informes.
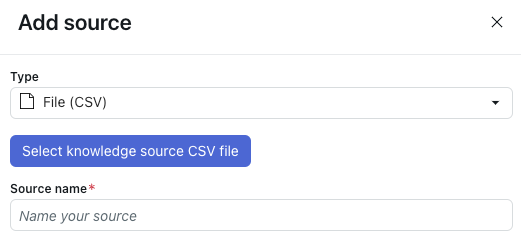
- Haga clic en Importar.
Formato necesario para el archivo CSV
El archivo CSV que cargue como una fuente de conocimiento debe tener una fila para cada artículo que desea importar. El archivo debe incluir las siguientes columnas:
- title: el título del artículo.
-
content: todo el contenido del artículo.
- El contenido puede incluir etiquetas HTML, de modo que no es necesario deshacerse de ellas. De hecho, las etiquetas pueden ser útiles porque estructuran los artículos, lo que ayuda al agente IA a comprender las distintas secciones.
- El contenido también puede contener Markdown, pero este tiene que ser válido o no se importará el contenido de esa celda. Además, si Markdown se escribe de tal manera que la celda es una sola línea de más de 2000 caracteres, la importación de la celda fallará sin mostrar ninguna advertencia.
También se pueden incluir las siguientes columnas opcionales:
- labels: una lista de nombres de rótulos separados por un espacio. Los valores pueden ser cualquier cosa que desee usar para clasificar el contenido.
- locale: se utiliza para organizar los artículos por idioma o mercado. Desde el punto de vista técnico, se admite cualquier valor, pero se recomienda seguir la notación estándar para la configuración regional (por ejemplo, en-US o fi-FI).
- article_url: la dirección web externa donde se encuentra el artículo. Se usa en la atribución de la fuente en el widget y en el panel de informes de los agentes IA.
El formato de archivo también debe usar lo siguiente:
- Comas (,) para separar las columnas y comillas dobles (") como el carácter para delimitar cadenas.
- La primera fila para los encabezados de columna.
- Solo caracteres ASCII. Los archivos CSV no se pueden importar si contienen caracteres que no son ASCII.
En la parte inferior de este artículo hay una plantilla que se puede descargar.
Importar contenido con un rastreador web (heredado)
Los administradores de clientes pueden importar el contenido de un sitio web usando un rastreador web.
Si desea más información sobre las importaciones realizadas con el rastreador web, consulte Importación de contenido para los agentes IA con un rastreador web: mejores prácticas y Resolución de problemas con las importaciones del rastreador web para los agentes IA.
Para importar contenido web rastreado
- En el espacio de trabajo de agentes IA, seleccione el agente IA con el que desee trabajar.
- Haga clic en Contenido en la barra lateral y luego seleccione Fuentes de conocimiento.
- Haga clic en Agregar fuente.
Se abre el panel Agregar fuente.
- En Tipo, seleccione Rastreador web.
- En Nombre de origen, escriba un nombre para la fuente.
En el panel Informes de los agentes IA, se usa este nombre en los propios informes.
- Seleccione Rastrear URL exacta si desea que el rastreador web importe información solo de las páginas web que aparecen en el campo URL de inicio, sin incluir ninguna subpágina.
Si esta opción no está seleccionada, el rastreador web aplica una profundidad de rastreo máxima de 15 subpáginas para los URL que se muestran en el campo URL de inicio.
- En URL de inicio, ingrese los URL que desea que rastree el rastreador web.
Ponga cada URL en una línea distinta.
- En Frecuencia de importación, seleccione con qué frecuencia se debe volver a importar el contenido rastreado del centro de ayuda:
- Diario: el contenido se vuelve a importar todos los días excepto los domingos y el día 15 del mes. No se recomienda salvo que la fuente de conocimiento se actualice con mucha frecuencia.
- Semanal: el contenido se vuelve a importar todas las semanas (siempre el domingo).
- Mensual: el contenido se vuelve a importar el día 15 de cada mes.
-
Nunca: el contenido se importa una vez y nunca más se vuelve a importar.
No se garantiza el momento exacto de la reimportación. Se procesa durante el día para el que se programó, pero es posible que no siempre esté lista a la misma hora.
Si las importaciones se hacen de manera regular, el agente IA estará siempre al día. Para la mayoría de las organizaciones, un intervalo de una semana o un mes es suficiente. Recuerde que siempre puede volver a importar el contenido manualmente si hay cambios nuevos que tienen que reflejarse antes de la reimportación programada.
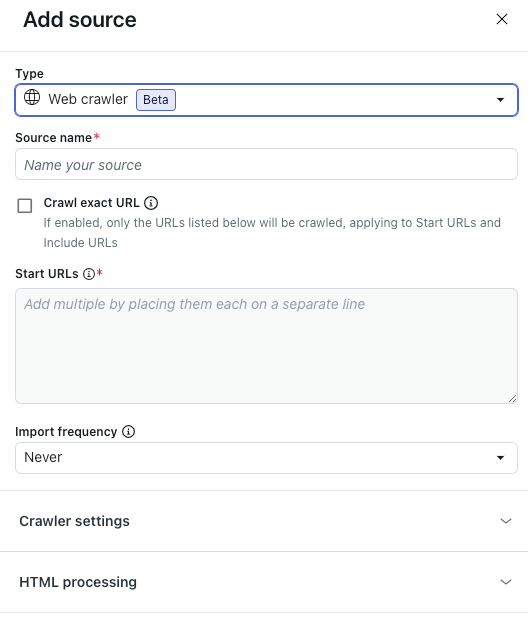
- (Opcional) Amplíe Configuración del rastreador para configurar las opciones avanzadas del rastreador.
Consulte Configurar las opciones avanzadas del rastreador si desea ver los detalles.
Nota: Estas opciones se recomiendan solo para las organizaciones que tienen requisitos técnicos complejos. Muchas organizaciones no las necesitan. - (Opcional) Amplíe Procesamiento de HTML para configurar las opciones avanzadas de HTML.
Consulte Configurar las opciones avanzadas de HTML si desea ver los detalles.
Nota: Estas opciones se recomiendan solo para las organizaciones que tienen requisitos técnicos complejos. Muchas organizaciones no las necesitan. - Haga clic en Importar.
Configurar las opciones avanzadas del rastreador
-
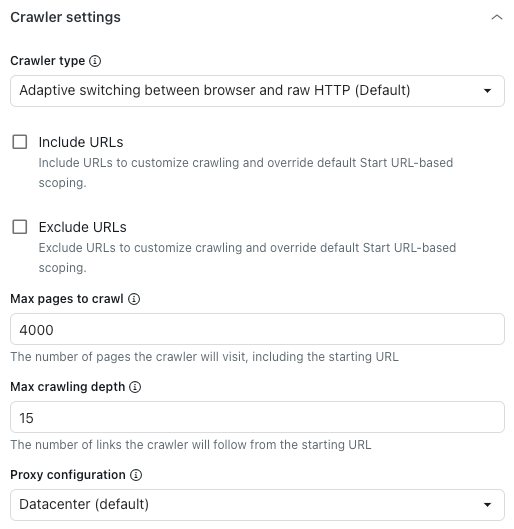
Bajo el encabezado Configuración del rastreador, en Tipo de rastreador, seleccione una de las siguientes opciones:
- Cambio adaptativo entre navegador y HTTP sin formato (predeterminado): es rápido y representa el contenido de JavaScript si existe.
- Navegador autónomo (Firefox + Playwright): es confiable y representa el contenido de JavaScript; es ideal para evitar bloqueos, pero puede ser lento.
- Cliente HTTP sin procesar (Cheerio): es la opción más rápida, pero no representa el contenido de JavaScript.
- Sin procesar con JavaScript: rastrea el contenido sin procesar de la página como si se estuviera usando JavaScript.
- Seleccione Incluir URL o Excluir URL para personalizar el alcance del rastreo configurado en el campo URL de inicio de arriba.
En el campo que se encuentra debajo de cada opción, ingrese los URL que desea incluir o excluir. Ingrese cada URL en su propia línea.
Estas opciones solo afectan los vínculos que se encuentran al rastrear las subpáginas. Si desea rastrear una página, asegúrese de especificar su URL en el campo URL de inicio.Por ejemplo, si la estructura del URL no coincide, como en el ejemplo que sigue:
- URL de inicio:
https://support.example.com/en/support/home - URL del artículo:
https://support.example.com/en/support/solutions/articles/…
-
https://support.example.com/en/support/**
De este modo, el rastreador web incluirá todos los artículos, aunque su ruta difiera de la del URL de inicio.
Otro ejemplo: el siguiente sitio web es muy amplio e incluye páginas irrelevantes (por ejemplo, la página de empleos):- URL de inicio:
https://www.example.com/en
https://www.example.com/en/careers/**
Sugerencia: Los globs —patrones que permiten usar caracteres especiales para crear URL dinámicos en los que el rastreados web pueda hacer búsquedas— ofrecen más funciones que el texto sin formato. Estos son algunos ejemplos:-
https://support.example.com/**permite que el rastreador acceda a todos los URL que comienzan con https://support.example.com/. -
https://{store,docs}.example.com/**permite que el rastreador acceda a todos los URL que comienzan con https://store.example.com/ o https://docs.example.com/. -
https://example.com/**/*\?*foo=*permite que el rastreador acceda a todos los URL que contienen parámetros de consulta foo con cualquier valor.
- URL de inicio:
- En Máximo de páginas para rastrear, ingrese el máximo número de páginas que rastreará el rastreador web, incluido el URL de inicio.
Esto incluye el URL de inicio, las páginas de paginación, las páginas sin contenido y mucho más. El rastreador web se detendrá automáticamente después de alcanzar este límite.
- En Profundidad máxima de rastreo, ingrese el número máximo de vínculos que seguirá el rastreador web desde el URL de inicio.
El URL de inicio tiene una profundidad de 0. Las páginas vinculadas directamente desde el URL de inicio tienen una profundidad de 1, y así sucesivamente. Utilice esta opción para evitar que el rastreador web se descontrole accidentalmente.
- En Configuración de proxy, seleccione una de estas opciones:
- Centro de datos (predeterminado): el método más rápido para extraer datos.
-
Residencial: tiene un rendimiento reducido, pero es menos probable que sea bloqueado. Es la opción ideal para cuando el proxy predeterminado está bloqueado o cuando hay que hacer rastreos desde un país especifico.
Configurar las opciones avanzadas de HTML
-
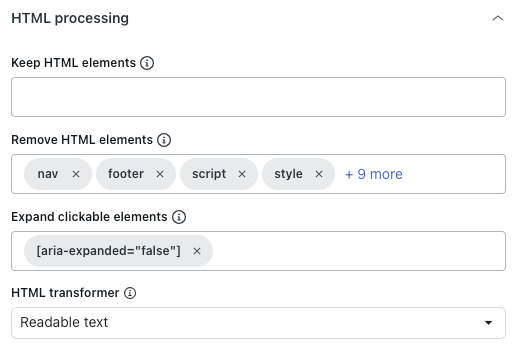
Bajo el encabezado Procesamiento de HTML, en Conservar elementos HTML, ingrese un selector de CSS para mantener solo los elementos de HTML especificados.
El resto del contenido será eliminado, lo que le ayudará a enfocarse solo en la información relevante.
- En Eliminar elementos HTML, elija los elementos de HTML que desea eliminar antes de convertir el contenido a texto o Markdown, o de guardarlo como HTML.
Esto ayuda a excluir el contenido no deseado.
- En Expandir elementos en los que se puede hacer clic, ingrese un selector de CSS válido que coincida con los elementos DOM en los que se hará clic.
Esto es útil para ampliar las secciones contraídas y capturar su contenido de texto.
- En Transformador HTML, seleccione uno de los siguientes valores para definir cómo limpiar el HTML, eliminando el contenido innecesario (como la navegación y las ventanas emergentes) para guardar solo el importante:
- Extractus: (no se recomienda) utiliza la biblioteca Extractus.
- Ninguno: elimina solo los elementos de HTML que se especifican en la opción Eliminar elementos HTML de arriba.
- Texto legible: utiliza la biblioteca de legibilidad de Mozilla para extraer el contenido del artículo principal, y elimina la navegación, los encabezados, los pies de página y otros elementos no esenciales. Funciona mejor en blogs y sitios web con muchos artículos.
-
Texto legible si es posible: usa la biblioteca de legibilidad de Mozilla para extraer el contenido principal, pero recurre al HTML original si la página no parece un artículo. Esto es útil para los sitios web que tienen tipos de contenido mixtos, como artículos o páginas de producto, ya que conserva más contenido en las páginas sin artículos.
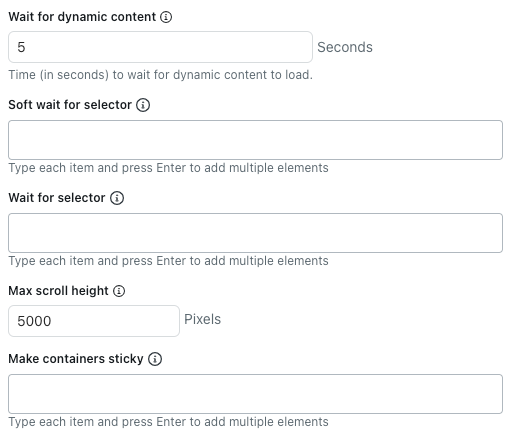
- En Esperar contenido dinámico, especifique el número de segundos que el rastreador debe esperar para que se cargue el contenido dinámico. De manera predeterminada, espera cinco segundos o hasta que la página termine de cargarse (lo que ocurra primero).
- En Espera temporal para selector, ingrese los selectores de CSS para elementos de HTML que deberán cargarse antes de que el rastreador extraiga contenido.
Si el elemento seleccionado no está presente, el rastreador seguirá rastreando esa página.
Ponga cada selector de CSS en una línea separada.
- En Esperar selector, ingrese los selectores de CSS para elementos de HTML que el rastreador debe esperar que se carguen antes de extraer contenido.
Si el elemento seleccionado no está presente, el rastreador no rastrea esa página.
Ponga cada selector de CSS en una línea separada.
- En Altura máxima de desplazamiento, especifique el número máximo de píxeles que debe recorrer el rastreador.
El rastreador se desplaza por la página para cargar más contenido hasta que la red esté inactiva o se alcance esta altura de desplazamiento. Establezca el valor en 0 para desactivar el desplazamiento por completo.
Esta configuración no se aplica cuando se usa el cliente HTTP sin procesar, porque no ejecuta JavaScript ni carga contenido dinámico.
- En Hacer que los contenedores sean fijos, ingrese los selectores de CSS para elementos de HTML en los que el contenido secundario debe conservarse, aunque esté oculto.
Ponga cada selector de CSS en una línea separada.
Esto es útil cuando se usa la opción Expandir elementos en los que se puede hacer clic en las páginas que eliminan totalmente el contenido oculto de la página.
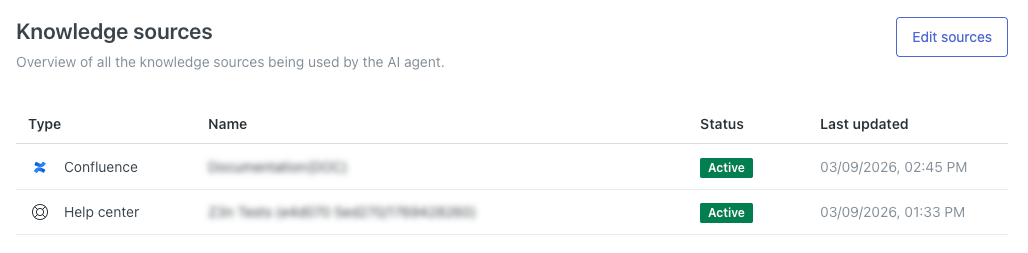
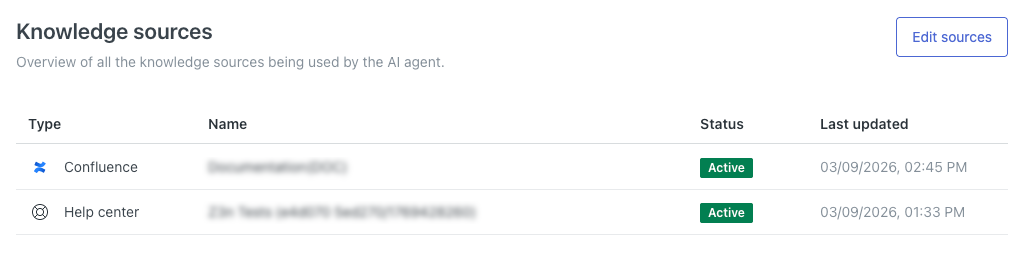
Ver todas las fuentes de conocimiento conectadas
En la configuración de su agente IA, puede ver todas las fuentes de contenido que están conectadas a él y que utilizará para responder a las preguntas de los clientes.
Para ver todas las fuentes de contenido conectadas
- En el espacio de trabajo de agentes IA, seleccione el agente IA con el que desee trabajar.
-
Haga clic en Contenido en la barra lateral y luego seleccione Fuentes de conocimiento.
Esta página muestra una lista de todas las fuentes de conocimiento que están conectadas al agente IA.