Résumé ◀▼
Vous pouvez configurer plusieurs crawlers Web pour indexer le contenu des sites Web externes pour la recherche de votre centre d’aide, en filtrant les résultats par source. Les crawlers utilisent des plans de site ou des URL spécifiques pour collecter du contenu public, notamment les pages générées par JavaScript. Ils effectuent des mises à jour rationnelles, pour garantir que le contenu externe pertinent s’affiche dans les résultats de recherche. C’est vous qui décidez quels sites ou quelles pages explorer, ce qui contribue au développement des ressources explorables sans intervention d’un développeur.
Le crawler Web vous permet d’explorer et d’indexer le contenu externe à utiliser là où vous utilisez du contenu externe dans votre compte Zendesk sans ressources pour les développeurs. Vous pouvez configurer plusieurs crawlers pour explorer et indexer différents contenus dans un ou plusieurs sites Web. Vous pouvez aussi explorer une liste d’URL spécifique, sans explorer la totalité du site.
Quand un utilisateur effectue une recherche dans votre centre d’aide, le contenu externe pertinent découvert par le crawler est classé et présenté à la page des résultats de recherche. Sur cette page, l’utilisateur peut filtrer les résultats et cliquer sur les liens pour consulter le lien du contenu externe dans un autre onglet du navigateur.
À propos du crawler Web
Vous pouvez créer un maximum de 20 crawlers Web pour explorer et indexer du contenu externe dans un ou plusieurs sites Web. Le contenu des sites Web explorés et des pages de ces sites est disponible là où vous utilisez du contenu externe dans votre compte Zendesk. Les sites externes que vous voulez explorer doivent avoir un plan du site qui répertorie les pages pour le crawler Web. En outre, les pages que vous voulez explorer doivent être publiques (non authentifiées).
- Explorer la totalité du site Web, le crawler localise automatiquement le plan du site associé à l’URL de départ ou le plan du site que vous spécifiez, puis l’utilise pour explorer toutes les pages du site.
- Limiter l’exploration à certaines pages individuelles, vous pouvez spécifier jusqu’à cinq URL que vous voulez explorer. L’option Limiter l’exploration à ces URL est automatiquement sélectionnée si vous saisissez plus d’une URL. Cependant, si vous ne saisissez qu’une URL de départ, vous pouvez malgré tout sélectionner cette option manuellement pour limiter l’exploration à une seule page. Si vous saisissez un plan du site, cette option est désélectionnée et désactivée, car le crawler doit explorer toutes les pages du plan du site.
Quand vous créez un nouveau crawler, le nom que vous affectez au crawler sera utilisé pour créer la valeur Source. Les valeurs Source sont utilisées comme filtres dans la recherche de votre centre d’aide. Si vous voulez modifier le nom plus tard, vous pouvez toujours modifier ou affecter un autre nom de source. Consultez Gestion des crawlers Web.
Une fois configurés, les crawlers sont programmés pour s’exécuter à intervalles réguliers : ils visitent les pages du plan du site et ingèrent le contenu de ces sources dans les index de recherche du centre d’aide. S’il n’y a pas de plan du site disponible, les crawlers suivent les liens de la page principale pour explorer les pages secondaires et ingérer leur contenu. Le crawler continue de cette manière, en consultant chaque page liée, puis en suivant les liens vers la page suivante dans la hiérarchie du site, jusqu’à ce que le crawler ait exploré la totalité du contenu lié sur quatre niveaux ou la totalité du site, selon la première de ces éventualités. Le crawler suit uniquement les liens qui dirigent vers des pages au sein du domaine du site et n’explore pas les pages externes.
Les crawlers Web indexent le contenu qui se trouve dans la page source au chargement initial de la page, même s’il est masqué par un élément de l’interface, comme un accordéon. Les crawlers peuvent également recourir à l’exploration adaptative pour extraire le contenu dont l’affichage nécessite l’exécution de JavaScript. Avant de traiter chaque section d’un site Web, le crawler prélève automatiquement un petit échantillon de pages et compare les résultats obtenus par une requête standard et un rendu complet dans le navigateur. Si le rendu du navigateur capture nettement plus de contenu, le crawler passe en mode navigateur pour cette partie du site. Cela signifie que différentes parties d’un même site Web peuvent être explorées selon différents modes. Par exemple, une section de blog statique peut recourir à une récupération standard, tandis qu’une section d’application dynamique utilise le rendu par le navigateur. Ce processus se déroule automatiquement, sans nécessiter aucune configuration.
En outre, les crawlers Web n’explorent pas les liens qui se trouvent sur les pages qu’ils visitent, ils visitent uniquement les pages du plan du site qu’ils sont configurés pour utiliser. Si le crawler n’arrive pas à recueillir d’information à partir d’un site Web pendant une exploration planifiée (si le site Web est indisponible ou s’il y a des problèmes de réseau, par exemple), le centre d’aide conserve les résultats de l’exploration précédente, dans lesquels il sera toujours possible d’effectuer des recherches dans le centre d’aide.
Configuration d’un crawler Web
- Le crawler Web ne fonctionne pas avec les sites Web qui utilisent le code de compression de fichiers gzip. Vous ne verrez pas de résultats de recherche provenant de ces sites.
- Le crawler Web ne respectera pas de délai de recherche (crawl-delay) s’il est défini pour les enregistrements robots.txt d’un site externe.
- Le marqueur changefreq n’affecte aucunement le crawler Web.
Pour configurer le crawler Web
-
Dans Administrateur de Connaissances, cliquez sur Paramètres (
 ) dans la barre latérale.
) dans la barre latérale.
- Cliquez sur Paramètres de recherche.
- Sous Crawlers, cliquez sur Gérer.
- Cliquez sur Ajouter un crawler.

- Cliquez sur Continuer.
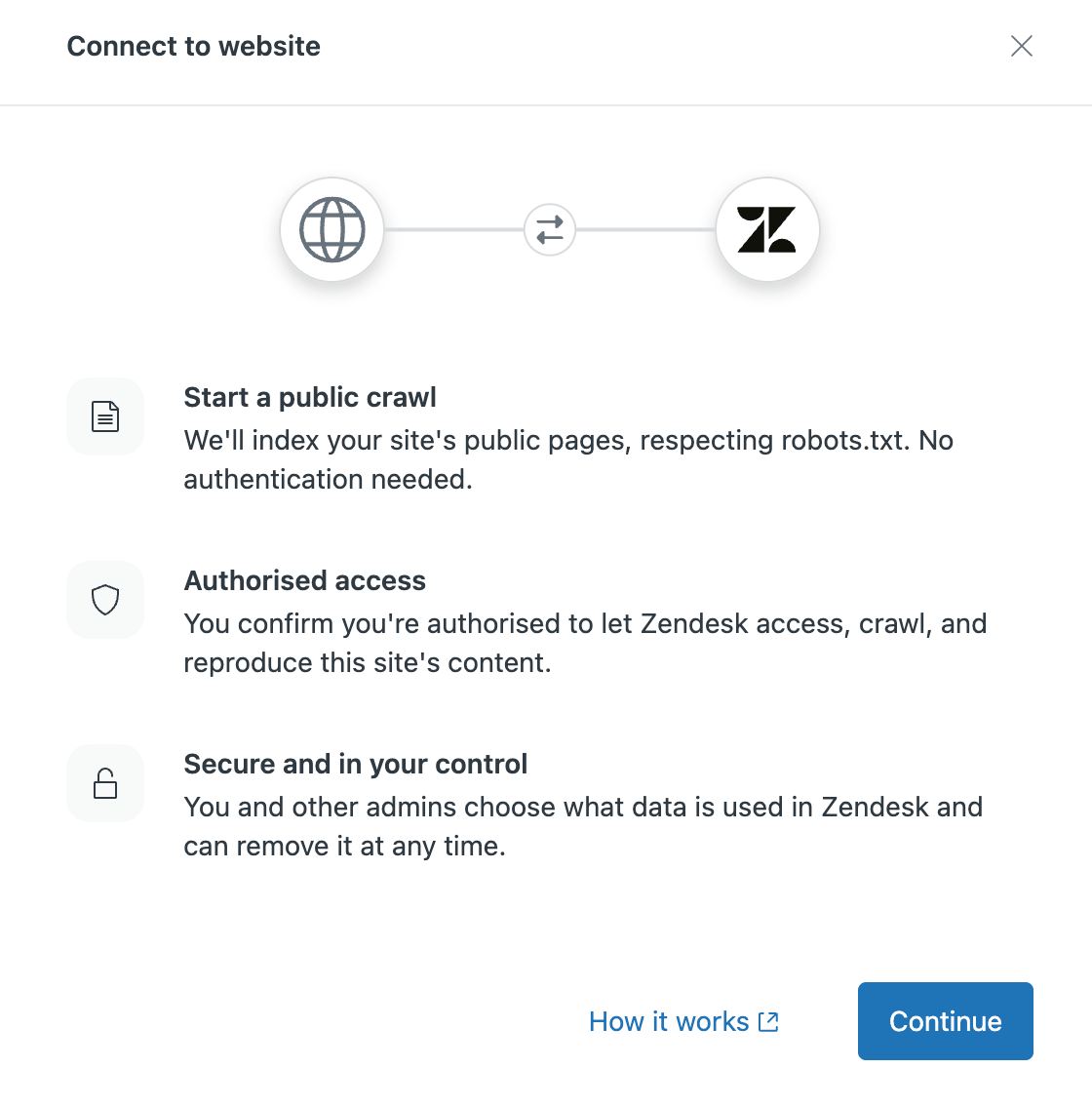
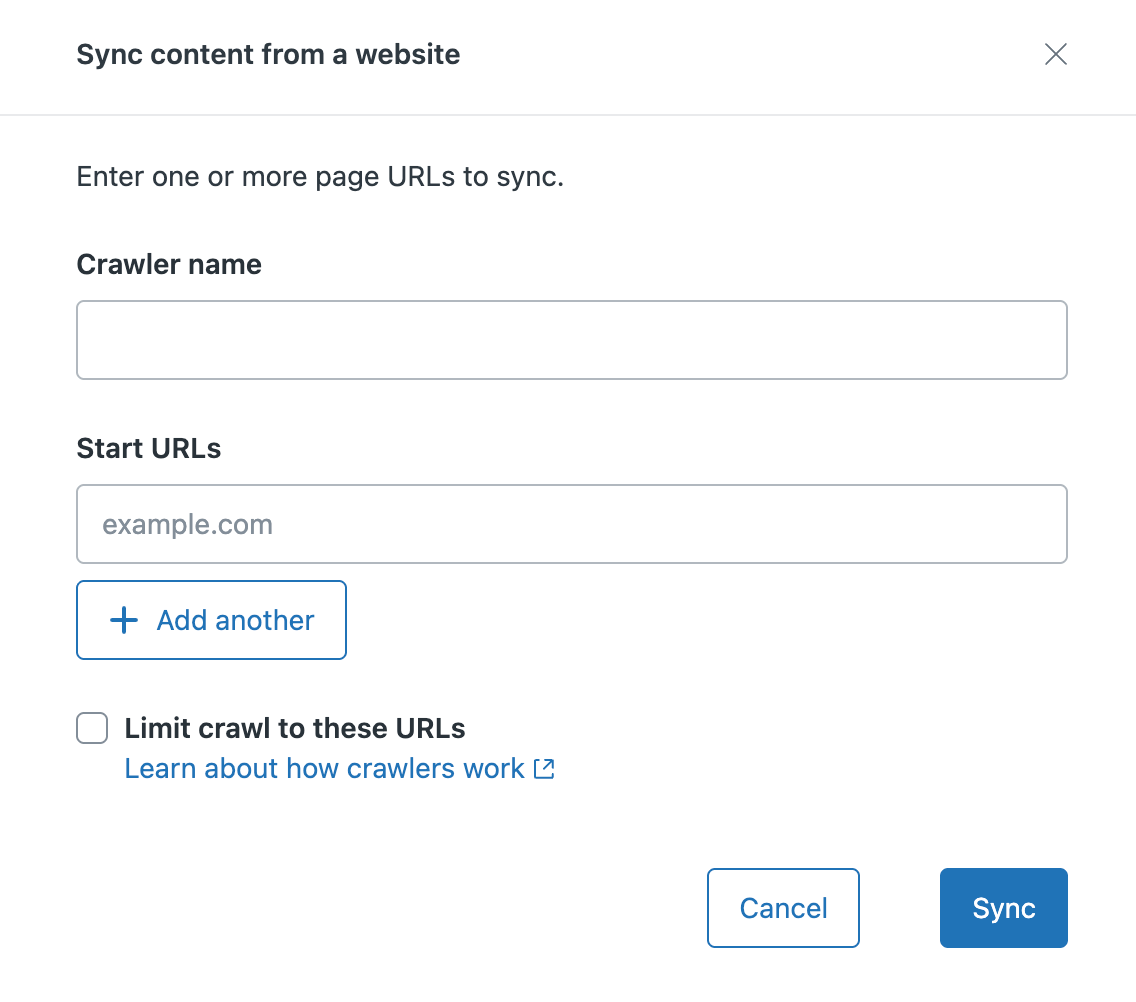
- Dans Synchronisation du contenu d’un site Web, saisissez ce qui suit :
- Le nom que vous souhaitez affecter au crawler. Ce nom identifie votre crawler Web ou la liste de gestion des crawlers, et est utilisé pour créer la valeur de la source de recherche utilisée comme filtre dans la recherche de votre centre d’aide.
-
Les URL de départ pour le site ou les pages que vous voulez explorer. Plusieurs cas :
- Explorez la totalité d’un site Web, puis saisissez le domaine principal (par exemple, zendesk.com) ou le chemin du plan du site (par exemple, zendesk.com/sitemap.xml)
-
Limitez l’exploration à certaines pages individuelles, saisissez la valeur du domaine/de la page dans ce champ (par exemple, test.com/faq.htm). Cliquez sur + Ajouter une autre pour ajouter jusqu’à cinq URL.
Quand vous sélectionnez cette option, le crawler explore et indexe uniquement les URL de départ spécifiées pendant la configuration.
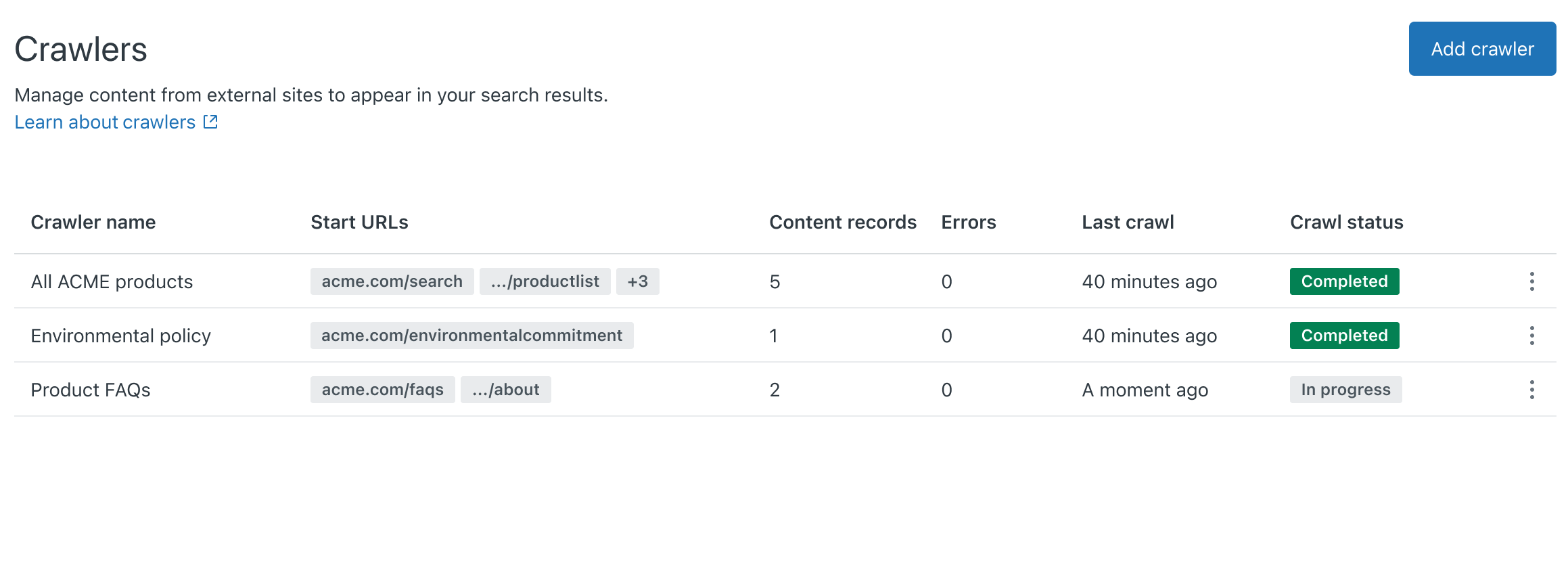
- Cliquez sur Synchroniser. Le crawler Web est ajouté à la page des crawlers. Dans un délai de 24 heures, le crawler récupérera et analysera le plan du site spécifié. Une fois le traitement du plan du site réussi, le crawler commence à explorer les pages et à indexer leur contenu. Si le crawler échoue, le propriétaire du crawler recevra une notification par e-mail avec des conseils de dépannage pour l’aider à résoudre le problème. Le crawler réessaiera à intervalles réguliers.Remarque – Zendesk/External-Content est l’agent utilisateur pour le crawler Web. Pour éviter qu’un crawler n’échoue à cause d’un pare-feu bloquant les demandes, ajoutez Zendesk/External-Content à votre liste autorisée.
- La recherche du centre d’aide : vous devez sélectionner le contenu à inclure et à exclure des résultats de recherche de votre centre d’aide. Consultez Inclusion du contenu externe dans les résultats de recherche de votre centre d’aide.
- La section Connaissances du volet contextuel pour les agents : consultez Configuration de la section Connaissances.