Le fonti di conoscenza sono le informazioni usate agenti AI avanzata per creare risposte generate AI alle domande dei clienti. L’aggiunta di fonti di conoscenza all’agente agenti AI consente di generare risposte per aiutare i clienti senza che tu debba scrivere uno script per ogni risposta.
Questo articolo include i seguenti argomenti:
Articoli correlati:
Informazioni sulle origini Knowledge
Puoi importare i seguenti tipi di origini Knowledge in un agenti AI avanzata :
- Centri assistenza: Centri assistenza basati sul web basati su Zendesk, Salesforce o Freshdesk.
- Confluenza: Siti o spazi Confluence usati dall’organizzazione per memorizzare i contenuti.
-
File CSV: File CSV formattati con informazioni sugli articoli.
L’importazione di file CSV è una buona soluzione per importare Knowledge base non supportate in modo nativo o protette da Single Sign-On (SSO).
-
Contenuti importati con un web crawler: Informazioni da una pagina web o da un insieme di pagine web.
Questa opzione è più adatta per importare informazioni da una Knowledge base, da domande frequenti o da una pagina di descrizione del prodotto. È meno adatto ai negozi web di e-commerce. Per le pagine di e-commerce, Zendesk consiglia di creare un’integrazione in grado di recuperare informazioni pertinenti sui prodotti e aggiungerle in una finestra di dialogo o in una procedura generativa.
Puoi aggiungere più origini Knowledge a un singolo agenti AI. Ad esempio, puoi importare articoli da più centri assistenza Zendesk, più file CSV o una combinazione di entrambi. Tuttavia, ti consigliamo di mantenere il numero complessivo di fonti di conoscenza entro un limite ragionevole. Avere molte origini può in alcuni casi ridurre la precisione e aumentare la latenza.
È importante comprendere che il tuo agenti AI non cerca dati in tempo reale in un centro assistenza, file o sito web. Al contrario, le informazioni vengono importate nell’agente agenti AI su base una tantum o ricorrente. L’ agenti AI usa queste informazioni importate durante la generazione delle risposte.
Importazione di un’origine Knowledge
Gli amministratori client possono importare i seguenti tipi di origini Knowledge per un agenti AI:
Importazione di un centro assistenza Zendesk
Gli amministratori client possono importare un centro assistenza Zendesk.
Per importare un centro assistenza Zendesk
- In agenti AI - Avanzati, seleziona l’ agenti AI avanzato con cui vuoi lavorare.
- Fai clic su Contenuto nella barra laterale, quindi seleziona Knowledge.
- Nella scheda Origini Knowledge, fai clic su Aggiungi origine.
Si apre il riquadro Aggiungi origine.
- In Tipo, seleziona Zendesk.
- In URL centro assistenza, inserisci il tuo sottodominio, con o senza le impostazioni locali centro assistenza :
- Aggiungi tutte le lingue del centro assistenza inserendo il tuo sottodominio (ad esempio, https://tuosottodominio.zendesk.com). Non includere /hc alla fine dell’URL.
- Aggiungi solo una lingua specifica del centro assistenza includendo anche le impostazioni locali alla fine dell’URL (ad esempio, https://yoursubdomain.zendesk.com/hc/en-us).
- In Nome origine, inserisci un nome per la tua origine.
Questo nome viene usato nei report in agenti AI - Avanzati.
- In Frequenza di importazione, seleziona la frequenza con cui reimportare i contenuti centro assistenza :
- Giornaliero: Il contenuto viene reimportato ogni giorno, escluse le domeniche e il 15 del mese. Non consigliato, a meno che la fonte di informazioni non venga aggiornata molto frequentemente.
- Settimanale: Il contenuto viene reimportato ogni settimana la domenica.
- Mensile: Il contenuto viene reimportato il 15 di ogni mese.
-
Mai: Il contenuto viene importato una sola volta e non viene mai reimportato.
La tempistica esatta di una reimportazione non è garantita. La reimportazione viene elaborata durante il giorno pianificato, ma potrebbe non essere sempre pronta in un momento coerente.
La reimportazione regolare mantiene aggiornato l’ agenti AI . Per la maggior parte delle organizzazioni, una cadenza settimanale o mensile va bene. Tieni presente che puoi sempre reimportare manualmente se le nuove modifiche devono essere applicate al di fuori della reimportazione pianificata.

- Se vuoi importare articoli con limitazioni:
- Attiva l’opzione Importa articoli privati .
- In Email, inserisci l’indirizzo email di un utente autorizzato ad accedere ai contenuti riservati.
Questo è in genere l’indirizzo email di un amministratore Knowledge.
- In Token di accesso API, inserisci un token API generato a questo scopo.
- Fai clic su Importa.
Importazione di un centro assistenza Salesforce
Gli amministratori client possono importare un centro assistenza Salesforce .
Per importare un centro assistenza Salesforce
- In agenti AI - Avanzati, seleziona l’ agenti AI avanzato con cui vuoi lavorare.
- Fai clic su Contenuto nella barra laterale, quindi seleziona Knowledge.
- Nella scheda Origini Knowledge, fai clic su Aggiungi origine.
Si apre il riquadro Aggiungi origine.
- In Tipo, seleziona Salesforce.
- Fai clic su Accedi a Salesforce.
- Accedi al tuo ambiente Salesforce .
- In URL centro assistenza, inserisci l’URL completo del centro assistenza Salesforce .
- In Nome origine, inserisci un nome per la tua origine.
Questo nome viene usato nei report in agenti AI - Avanzati.
- In Frequenza di importazione, seleziona la frequenza con cui reimportare i contenuti centro assistenza :
- Giornaliero: Il contenuto viene reimportato ogni giorno, escluse le domeniche e il 15 del mese. Non consigliato, a meno che la fonte di informazioni non venga aggiornata molto frequentemente.
- Settimanale: Il contenuto viene reimportato ogni settimana la domenica.
- Mensile: Il contenuto viene reimportato il 15 di ogni mese.
-
Mai: Il contenuto viene importato una sola volta e non viene mai reimportato.
La tempistica esatta di una reimportazione non è garantita. La reimportazione viene elaborata durante il giorno pianificato, ma potrebbe non essere sempre pronta in un momento coerente.
La reimportazione regolare mantiene aggiornato l’ agenti AI . Per la maggior parte delle organizzazioni, una cadenza settimanale o mensile va bene. Tieni presente che puoi sempre reimportare manualmente se le nuove modifiche devono essere applicate al di fuori della reimportazione pianificata.
- Fai clic su Importa.
Importazione di un centro assistenza Freshdesk
Gli amministratori client possono importare un centro assistenza Freshdesk.
Per importare un centro assistenza Freshdesk
- In agenti AI - Avanzati, seleziona l’ agenti AI avanzato con cui vuoi lavorare.
- Fai clic su Contenuto nella barra laterale, quindi seleziona Knowledge.
- Nella scheda Origini Knowledge, fai clic su Aggiungi origine.
Si apre il riquadro Aggiungi origine.
- In Tipo, seleziona Freshdesk.
- In URL centro assistenza, inserisci l’URL completo del centro assistenza Freshdesk.
Puoi aggiungere l’intero centro assistenza o solo una determinata sezione del centro assistenza.
- In Nome origine, inserisci un nome per la tua origine.
Questo nome viene usato nei report in agenti AI - Avanzati.
- In Frequenza di importazione, seleziona la frequenza con cui reimportare i contenuti centro assistenza :
- Giornaliero: Il contenuto viene reimportato ogni giorno, escluse le domeniche e il 15 del mese. Non consigliato, a meno che la fonte di informazioni non venga aggiornata molto frequentemente.
- Settimanale: Il contenuto viene reimportato ogni settimana la domenica.
- Mensile: Il contenuto viene reimportato il 15 di ogni mese.
-
Mai: Il contenuto viene importato una sola volta e non viene mai reimportato.
La tempistica esatta di una reimportazione non è garantita. La reimportazione viene elaborata durante il giorno pianificato, ma potrebbe non essere sempre pronta in un momento coerente.
La reimportazione regolare mantiene aggiornato l’ agenti AI . Per la maggior parte delle organizzazioni, una cadenza settimanale o mensile va bene. Tieni presente che puoi sempre reimportare manualmente se le nuove modifiche devono essere applicate al di fuori della reimportazione pianificata.
- In Token di accesso API, inserisci un token API generato in Freshdesk a tale scopo.
- Fai clic su Importa.
Importazione di un sito o di uno spazio Confluence
Gli amministratori client possono importare un sito o uno spazio Confluence.
Le connessioni Confluence vengono create e gestite in Knowledge. Prima di poter collegare un sito o uno spazio Confluence all’agente agenti AI avanzata, devi creare una connessione Confluence in Knowledge .
A differenza di altre origini Knowledge per gli agenti AI avanzati, non puoi specificare una frequenza di reimportazione per i contenuti di Confluence. Le connessioni Confluence si sincronizzano automaticamente ogni 24 ore, ma puoi sincronizzare di nuovo manualmente il contenuto, se necessario.
Per importare un sito o uno spazio Confluence
- In agenti AI - Avanzati, seleziona l’ agenti AI avanzato con cui vuoi lavorare.
- Fai clic su Contenuto nella barra laterale, quindi seleziona Knowledge.
- Nella scheda Origini Knowledge, fai clic su Aggiungi origine.
Si apre il riquadro Aggiungi origine.
- In Tipo, seleziona Confluence.
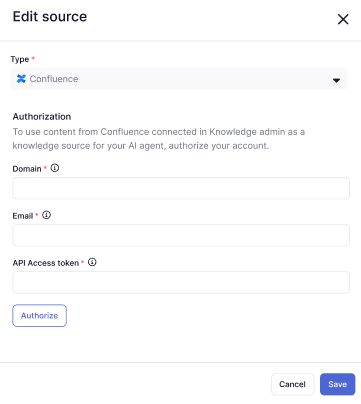
- In Dominio, inserisci l’URL del tuo sottodominio Zendesk (ad esempio,
https://yoursubdomain.zendesk.com). - In Email, inserisci l’indirizzo email di un amministratore Zendesk.
- In Token di accesso API, inserisci un token API generato a questo scopo.
- Fai clic su Autorizza.
- Seleziona un sito o uno spazio Confluence che è già stato collegato al tuo account Zendesk oppure crea una nuova connessione Confluence.
Puoi selezionarne più di uno.
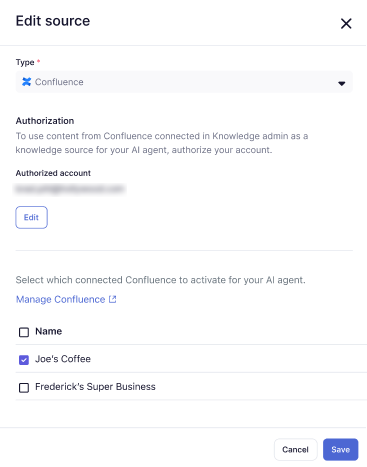
- Fai clic su Salva.
Il sito o lo spazio Confluence selezionato viene aggiunto all’elenco delle origini Knowledge.
Importazione di un file CSV
Gli amministratori client possono importare un file CSV come origine Knowledge.
Per importare un file CSV
- In agenti AI - Avanzati, seleziona l’ agenti AI avanzato con cui vuoi lavorare.
- Fai clic su Contenuto nella barra laterale, quindi seleziona Knowledge.
- Nella scheda Origini Knowledge, fai clic su Aggiungi origine.
Si apre il riquadro Aggiungi origine.
- In Tipo, seleziona File (CSV).
- Fai clic su Seleziona file CSV origine Knowledge.
- Seleziona il file CSV da importare.
Consulta Formattazione obbligatoria per il file CSV per garantire che il file sia formattato correttamente.
- In Nome origine, inserisci un nome per la tua origine.
Questo nome viene usato nei report in agenti AI - Avanzati.
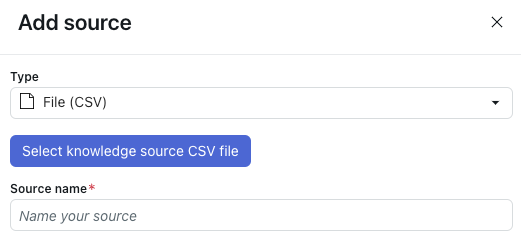
- Fai clic su Importa.
Formattazione obbligatoria per il file CSV
Il file CSV che carichi come origine Knowledge deve avere una riga per ogni articolo che vuoi importare. Il file deve includere le seguenti colonne:
- titolo: Il titolo dell’articolo.
-
contenuto: Il contenuto completo dell’articolo.
- Il contenuto può contenere tag HTML, quindi non è necessario rimuoverli. In effetti, i tag possono aiutare a strutturare gli articoli e tale struttura aiuta l’ agenti AI a comprendere le sezioni degli articoli.
- Il contenuto può contenere anche Markdown, ma il Markdown deve essere valido, altrimenti il contenuto di quella cella non verrà importato. Inoltre, se Markdown è stato scritto in modo tale che la cella sia composta da una singola riga di oltre 2.000 caratteri, l’importazione della cella non riesce senza mostrare alcun avviso.
Puoi anche includere le seguenti colonne facoltative:
- etichette: Un elenco di nomi di etichette separati da uno spazio. I valori possono essere qualsiasi elemento in base al quale classificare i contenuti.
- locale: Usato per organizzare gli articoli in base alla lingua o al mercato. Sebbene i valori possano essere tecnicamente qualsiasi, è consigliabile seguire la notazione delle impostazioni locali standard (ad esempio, en-US o fi-FI).
- article_url: L’indirizzo web esterno a cui è possibile trovare l’articolo. Viene usato nell’attribuzione dell’origine nel widget e nei report in agenti AI - Avanzati.
Il formato del file deve usare anche:
- Virgole (,) come separatore di colonna e virgolette (") come carattere di virgolette di stringa.
- La prima riga per le intestazioni di colonna.
- Solo caratteri ASCII. I file CSV non vengono importati se contengono caratteri non ASCII.
Puoi scaricare un modello in fondo a questo articolo.
Importazione di contenuti con un web crawler
Gli amministratori client possono importare i contenuti del sito web usando un web crawler.
Per ulteriori informazioni sulle importazioni di crawler web, consulta Prassi ottimali per l’uso di un crawler web per importare contenuti per agenti AI avanzati e Risoluzione dei problemi relativi alle importazioni di crawler web per agenti AI avanzati.
Per importare contenuti sottoposti a scansione web
- In agenti AI - Avanzati, seleziona l’ agenti AI avanzato con cui vuoi lavorare.
- Fai clic su Contenuto nella barra laterale, quindi seleziona Knowledge.
- Nella scheda Origini Knowledge, fai clic su Aggiungi origine.
Si apre il riquadro Aggiungi origine.
- In Tipo, seleziona Web crawler.
- In Nome origine, inserisci un nome per la tua origine.
Questo nome viene usato nei report in agenti AI - Avanzati.
- Seleziona Scansiona URL esatto se vuoi che il web crawler importi solo le informazioni dalle pagine web elencate nel campo URL iniziali, escluse le sottopagine.
Quando questa opzione non è selezionata, il web crawler applica una profondità di scansione massima di 15 sottopagine per tutti gli URL elencati in URL iniziali.
- In URL iniziali, inserisci gli URL che il web crawler deve utilizzare.
Elenca ciascun URL su una riga separata.
- In Frequenza di importazione, seleziona la frequenza con cui reimportare i contenuti sottoposti a scansione:
- Giornaliero: Il contenuto viene reimportato ogni giorno, escluse le domeniche e il 15 del mese. Non consigliato, a meno che la fonte di informazioni non venga aggiornata molto frequentemente.
- Settimanale: Il contenuto viene reimportato ogni settimana la domenica.
- Mensile: Il contenuto viene reimportato il 15 di ogni mese.
-
Mai: Il contenuto viene importato una sola volta e non viene mai reimportato.
La tempistica esatta di una reimportazione non è garantita. La reimportazione viene elaborata durante il giorno pianificato, ma potrebbe non essere sempre pronta in un momento coerente.
La reimportazione regolare mantiene aggiornato l’ agenti AI . Per la maggior parte delle organizzazioni, una cadenza settimanale o mensile va bene. Tieni presente che puoi sempre reimportare manualmente se le nuove modifiche devono essere applicate al di fuori della reimportazione pianificata.
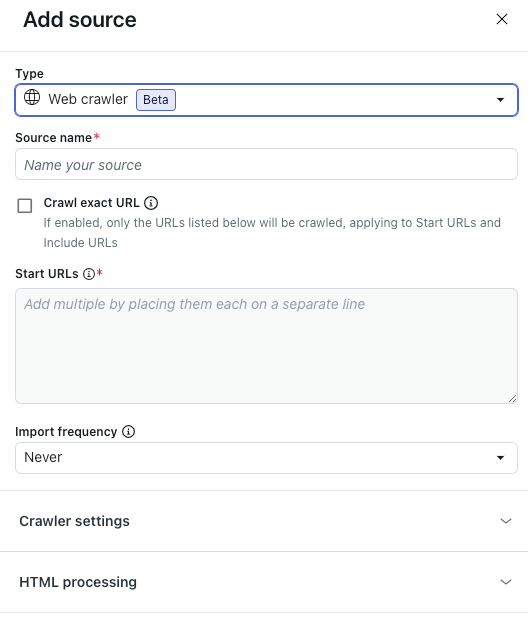
- (Facoltativo) Espandi Impostazioni crawler per configurare le impostazioni avanzate del crawler.
Per maggiori dettagli, consulta Configurazione delle impostazioni avanzate del crawler .
Nota: Queste impostazioni sono consigliate solo per le organizzazioni con requisiti tecnici complessi. Molte organizzazioni non hanno bisogno di queste impostazioni. - (Facoltativo) Espandi Elaborazione HTML per configurare le impostazioni HTML avanzate.
Per maggiori dettagli, consulta Configurazione delle impostazioni HTML avanzate .
Nota: Queste impostazioni sono consigliate solo per le organizzazioni con requisiti tecnici complessi. Molte organizzazioni non hanno bisogno di queste impostazioni. - Fai clic su Importa.
Configurazione delle impostazioni avanzate del crawler
-
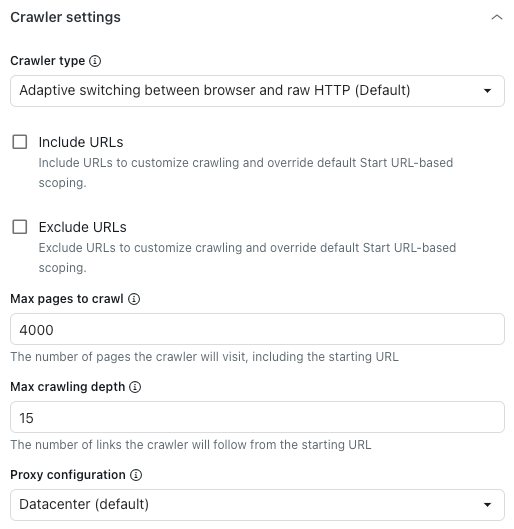
Sotto l’intestazione Impostazioni crawler, in Tipo crawler, seleziona una delle seguenti opzioni:
- Passaggio adattivo tra browser e HTTP non elaborato (predefinito): Veloce e rende il contenuto JavaScript, se presente.
- Browser headless (Firefox + Playwright): Affidabile, esegue il rendering dei contenuti JavaScript, il modo migliore per evitare il blocco, ma potrebbe essere lento.
- Client HTTP non elaborato (Cheerio): Il più veloce, ma non esegue il rendering del contenuto JavaScript.
- Raw con JavaScript: Scansiona la pagina come se stessi usando JavaScript.
- Seleziona Includi URL o Escludi URL per personalizzare l’ambito di scansione impostato nel campo URL iniziali qui sopra.
Nel campo sotto ogni impostazione, inserisci gli URL da includere o escludere. Inserisci ciascun URL in una riga separata.
Queste impostazioni influiscono solo sui link trovati durante la scansione delle pagine secondarie. Se vuoi eseguire la scansione di una pagina, assicurati di specificarne l’URL nel campo URL iniziali.Ad esempio, se la struttura dell'URL non è coerente, come nell'esempio seguente:
- URL iniziale:
https://support.example.com/en/support/home - URL articolo:
https://support.example.com/en/support/solutions/articles/…
-
https://support.example.com/en/support/**
In questo modo, il web crawler includerà tutti gli articoli, anche se il loro percorso è diverso dall’URL iniziale.
Come ulteriore esempio, la pagina seguente è molto ampia e include pagine non pertinenti (ad esempio, la pagina delle carriere):- URL iniziale:
https://www.example.com/en
https://www.example.com/en/careers/**
Suggerimento: Più potenti del testo normale, i glob sono pattern che ti consentono di usare caratteri speciali per creare URL dinamici per la ricerca del crawler web. Di seguito sono riportati alcuni esempi:-
https://support.example.com/**consente al crawler di accedere a tutti gli URL che iniziano con https:// assistenza.example.com/. -
https://{store,docs}.example.com/**consente al crawler di accedere a tutti gli URL che iniziano con https://store.example.com/ o https://docs.example.com/. -
https://example.com/**/*\?*foo=*consente al crawler di accedere a tutti gli URL che contengono parametri di query foo con qualsiasi valore.
- URL iniziale:
- In Numero massimo di pagine da sottoporre a scansione, inserisci il numero massimo di pagine che il crawler web dovrà affrontare, incluso l’URL iniziale.
Sono inclusi l’URL iniziale, le pagine di impaginazione, le pagine senza contenuto e altro ancora. Il web crawler si interromperà automaticamente al raggiungimento di questo limite.
- In Profondità massima di scansione, inserisci il numero massimo di link che il crawler web seguirà dall’URL iniziale.
L’URL iniziale ha una profondità di 0. Le pagine collegate direttamente dall’URL iniziale hanno una profondità di 1 e così via. Usa questa impostazione per evitare che il web crawler svanisca accidentalmente.
- In Configurazione proxy, seleziona una delle seguenti opzioni:
- Datacenter (predefinito): Il metodo più rapido per estrarre i dati.
-
Residenziale: Prestazioni ridotte, ma meno probabilità di essere bloccati. Ideale quando il proxy predefinito è bloccato o quando è necessario eseguire la scansione da un Paese specifico.
Configurazione delle impostazioni HTML avanzate
-
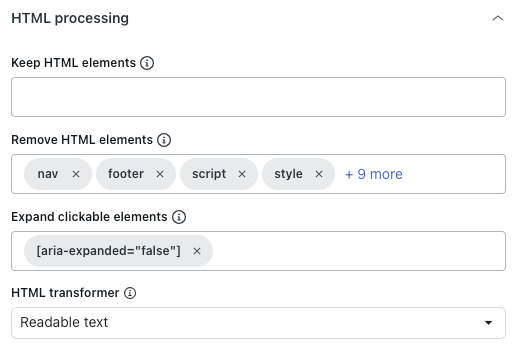
Sotto l’intestazione Elaborazione HTML, in Mantieni elementi HTML, inserisci un selettore CSS per mantenere solo gli elementi HTML specificati.
Tutti gli altri contenuti verranno rimossi, consentendoti di concentrarti solo sulle informazioni pertinenti.
- In Rimuovi elementi HTML, scegli gli elementi HTML da rimuovere prima di convertirli in testo, Markdown o salvarli come HTML.
Questo aiuta a escludere il contenuto indesiderato.
- In Espandi elementi selezionabili, inserisci un selettore CSS valido corrispondente agli elementi DOM su cui verrà fatto clic.
Ciò è utile per espandere le sezioni compresse al fine di acquisirne il contenuto di testo.
- In Trasformatore HTML, seleziona uno dei seguenti valori per definire come ripulire l’HTML in modo da mantenere solo i contenuti importanti e rimuovere i contenuti estranei (ad esempio, navigazione o popup):
- Estratto: (Non consigliato) Usa la libreria Extractus.
- Nessuno: Rimuove solo gli elementi HTML specificati nell’opzione Rimuovi elementi HTML qui sopra.
- Testo leggibile: Usa la libreria Readability di Mozilla per estrarre il contenuto principale degli articoli, rimuovendo navigazione, intestazioni, piè di pagina e altri elementi non essenziali. Funziona meglio per siti web e blog ricchi di articoli.
-
Testo leggibile, se possibile: Usa la libreria Readability di Mozilla per estrarre il contenuto principale, ma ricorre all’HTML originale se la pagina non sembra essere un articolo. Ciò è utile per i siti web con tipi di contenuti misti, come articoli o pagine di prodotti, in quanto conserva più contenuti nelle pagine non di articoli.
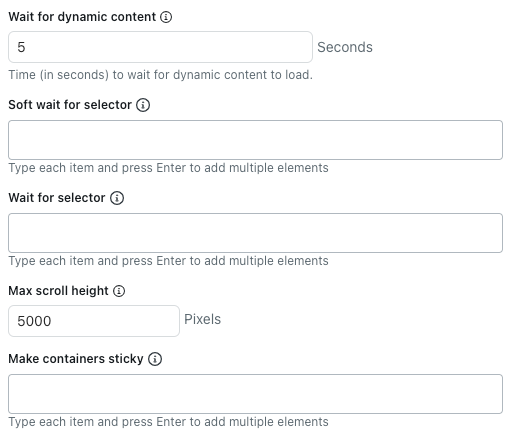
- In Attendi contenuto dinamico, inserisci il numero di secondi che il crawler deve attendere per il caricamento contenuto dinamico . Per impostazione predefinita, attende cinque secondi o fino al termine del caricamento della pagina, a seconda dell’evento che si verifica per primo.
- In Soft wait for selector, inserisci i selettori CSS per gli elementi HTML che il crawler deve attendere per caricare prima di estrarre il contenuto.
Se l’elemento selezionato non è presente, il crawler esegue comunque la scansione della pagina.
Elenca ciascun selettore CSS su una riga separata.
- In Attendi selettore, inserisci i selettori CSS per gli elementi HTML che il crawler deve attendere per caricare prima di estrarre il contenuto.
Se l’elemento selezionato non è presente, il crawler non esegue la scansione della pagina.
Elenca ciascun selettore CSS su una riga separata.
- In Max scroll height, inserisci il numero massimo di pixel che il crawler deve scorrere.
Il crawler scorre la pagina per caricare altro contenuto fino a quando la rete non è inattiva o viene raggiunta questa altezza di scorrimento. Impostalo su 0 per disabilitare completamente lo scorrimento.
Questa impostazione non si applica quando si usa il client HTTP non elaborato, in quanto non esegue JavaScript né carica contenuto dinamico.
- In Rendi persistenti i contenitori, inserisci i selettori CSS per gli elementi HTML in cui devono essere conservati i contenuti secondari, anche se sono nascosti.
Elenca ciascun selettore CSS su una riga separata.
Ciò è utile quando si usa l’opzione Espandi elementi selezionabili su pagine che rimuovono completamente i contenuti nascosti dalla pagina.
Avvertenza sulla traduzione: questo articolo è stato tradotto usando un software di traduzione automatizzata per fornire una comprensione di base del contenuto. È stato fatto tutto il possibile per fornire una traduzione accurata, tuttavia Zendesk non garantisce l'accuratezza della traduzione.
Per qualsiasi dubbio sull'accuratezza delle informazioni contenute nell'articolo tradotto, fai riferimento alla versione inglese dell'articolo come versione ufficiale.