Puoi usare un web crawler per importare contenuti nel tuo agenti AI avanzata . Ciò offre al tuo agenti AI la possibilità di creare risposte generate AI alle domande dei clienti sulla base delle informazioni in siti web esterni.
Questo articolo ti aiuta a risolvere i problemi che potresti riscontrare quando usi un web crawler per importare contenuti per un agenti AI avanzata.
Questo articolo include i seguenti argomenti:
- Scansione non riuscita perché scaduta
- Nella scansione mancano pagine
- La scansione include pagine non necessarie
- La scansione include le pagine giuste ma i contenuti sbagliati
Articoli correlati:
Scansione non riuscita perché scaduta
Se una scansione web non riesce dopo diverse ore, in genere è causato da un timeout. Per impostazione predefinita, le scansioni sono limitate a cinque ore. Se l’errore si è verificato cinque ore dopo l’inizio dell’importazione, è probabile che si tratti di un timeout.
In questo caso, ecco alcuni passaggi che puoi provare:
- Se il sito web non si basa su JavaScript, imposta Tipo di crawler su Client HTTP non elaborato (Cheerio), un crawler molto più veloce, e riprova.
- Se sai che il sito include contenuti che non ti servono, consulta le linee guida in La scansione include pagine non necessarie.
- Suddividi la scansione in due o più scansioni separate (usando le impostazioni Includi URL o Escludi URL ), ciascuna delle quali analizza solo parti del sito web.
Nella scansione mancano pagine
Se nella scansione mancano interi URL o articoli, aumenta l’ambito della scansione usando URL di inizio e Includi URL. Se sei sicuro che le impostazioni siano corrette ma ti mancano ancora degli articoli, controlla il numero di pagine scansionate nel riepilogo dell’importazione. Se si tratta del numero massimo di pagine predefinite da scansionare (4.000), prova ad aumentare questa impostazione.
La scansione include pagine non necessarie
Se la scansione include più pagine o articoli del necessario (ad esempio, contenuti ripetitivi o non applicabili, come pagine in inglese quando è necessario solo lo spagnolo o contenuti che l’ agenti AI non ha bisogno di rispondere alle domande dei clienti), usa l’impostazione Escludi URL .
Una cosa da evitare è l’esclusione accidentale di alcune sottopagine. Gli URL di inizio definiscono il punto di inizio del crawler. Seguirà quindi tutti i link da quella pagina e dalle pagine successive, fino alla profondità massima di scansionespecificata. Tuttavia, se escludi le pagine, le pagine collegate solo da pagine escluse non verranno mai sottoposte a scansione a meno che non siano specificate separatamente come URL iniziali.
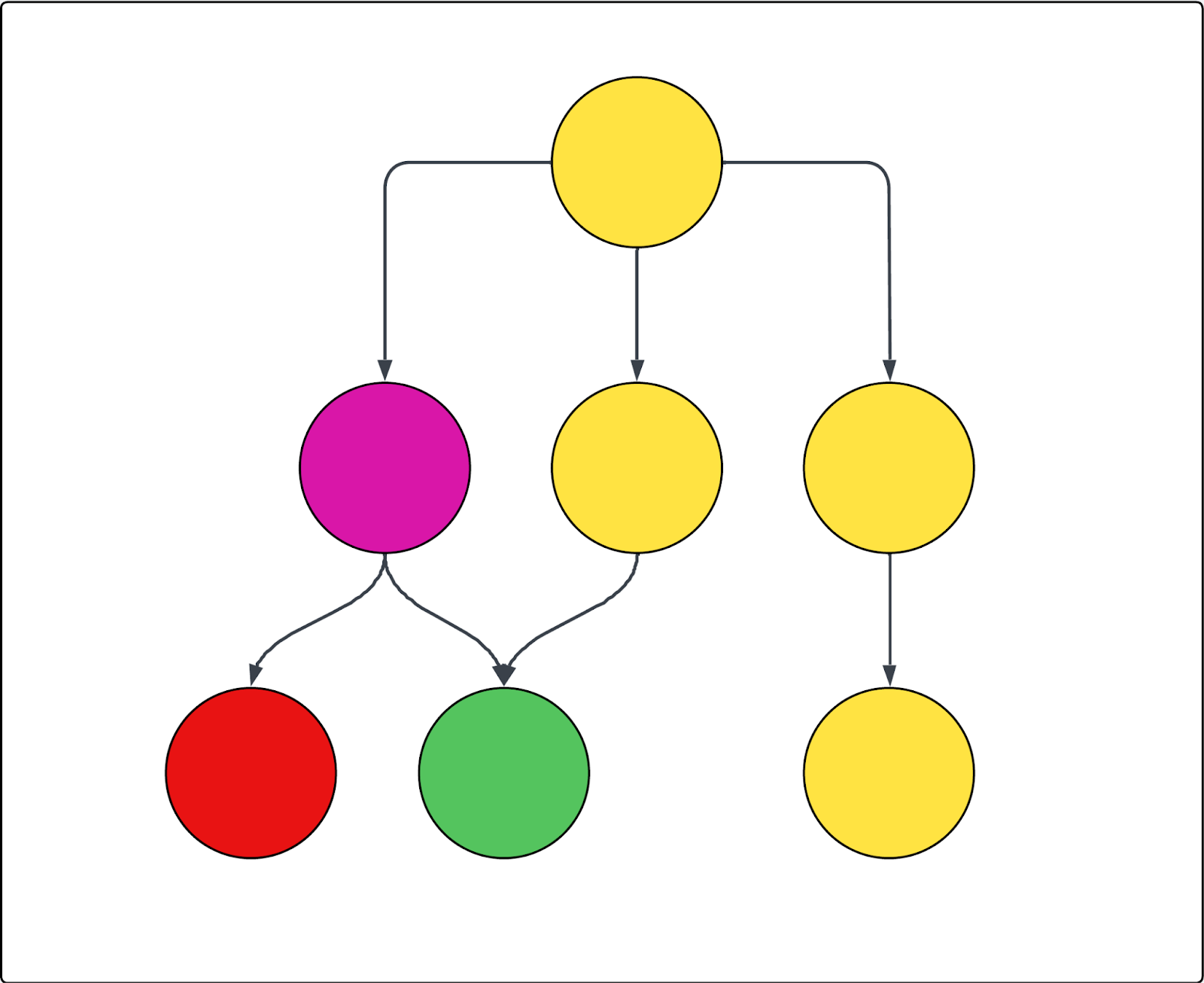
Vedi il diagramma seguente come esempio. Ogni cerchio rappresenta una pagina e ogni freccia rappresenta un link da quella pagina. Se la scansione inizia dalla pagina principale (come in, è l’unico URL di inizio) e la pagina viola è esclusa, vale quanto segue:
- Impossibile scansionare la pagina rossa.
- Tutte le pagine gialle vengono sottoposte a scansione.
- Anche la pagina verde verrà sottoposta a scansione, anche se è collegata alla pagina viola esclusa, perché è anche collegata a una delle pagine gialle incluse.
La scansione include le pagine giuste ma i contenuti sbagliati
Se la scansione restituisce le pagine corrette, ma il contenuto errato all'interno di tali pagine, le impostazioni avanzate del crawler includono strumenti per trovare e includere o escludere tali contenuti. Devi trovare il selettore CSS corretto per l’elemento da includere o escludere e inserirlo nell’impostazione corretta. A tale scopo, è utile capire cos’è un selettore CSS e come trovarlo.
Questa sezione include i seguenti argomenti:
Informazioni e ricerca dei selettori CSS
Questa sezione presenta i selettori CSS e guida alla ricerca di quello corretto. Se hai già familiarità con queste informazioni, passa alle sezioni di risoluzione dei problemi seguenti.
Questa sezione include i seguenti argomenti:
Informazioni sui selettori CSS
I selettori CSS sono modelli usati per selezionare e scegliere come target elementi HTML specifici in una pagina web. Consentono di trovare ed estrarre esattamente i dati di cui hai bisogno da pagine web complesse.
Nella scansione e nello scraping del web, i selettori CSS aiutano a estrarre i dati individuando le parti esatte della struttura di una pagina, come <div>, <span>o elementi con determinate classi e ID. Ad esempio, il selettore .product-title sceglie come target tutti gli elementi con la classe "product-title". Il cancelletto (#) viene usato per selezionare gli elementi in base al loro ID univoco. Ad esempio, #main-header seleziona l’elemento con id="main-header".
Ricerca di un selettore CSS
Innanzitutto, devi trovare il selettore CSS che vuoi usare. Le istruzioni seguenti presuppongono che tu stia usando il browser web Chrome. Tuttavia, i passaggi sono probabilmente simili per altri browser.
Per trovare un selettore CSS
- Individua il testo o l’elemento selezionabile nella pagina web a cui vuoi rivolgerti.
-
Fai clic con il pulsante destro del mouse direttamente sull’elemento e seleziona Ispeziona.
Si apre il pannello Chrome DevTools e la parte di codice corrispondente viene evidenziata.
-
Nel pannello DevTools, fai clic con il pulsante destro del mouse sul codice evidenziato e seleziona Copia > Copia selettore.
Ora il selettore CSS è stato copiato negli appunti.
Verifica di un selettore CSS
Dopo aver trovato il selettore CSS, è consigliabile verificarlo.
Per verificare il selettore CSS
-
Con DevTools ancora aperto, premi Ctrl+F (su Windows o Linux) o Cmd+F (su Mac).
Questa operazione attiva una barra di ricerca all’interno della scheda Elementi del pannello DevTools.
- Incolla il selettore CSS appena copiato in questa casella di ricerca.
- Verifica che gli elementi evidenziati nel codice HTML e nella pagina stessa (spesso con un contorno colorato) corrispondano a quanto previsto.
Se viene evidenziato solo l’elemento desiderato, il selettore è accurato. Se sono evidenziati troppi elementi o sono sbagliati, prova con un elemento principale o modifica la selezione.
Facoltativamente, puoi testare diversi selettori. A volte, i selettori più brevi o più specifici funzionano meglio. Puoi fare clic sugli elementi principali o secondari nell’HTML per visualizzarne le classi o gli ID CSS e provare a copiare anche quei selettori.
Le due sezioni successive illustrano come usare questi selettori per scegliere come target i contenuti di cui si esegue o non si desidera eseguire la scansione.
La scansione sta saltando il contenuto della pagina
Se la scansione contiene le pagine giuste, ma mancano dei contenuti in tali pagine, le seguenti impostazioni avanzate del crawler possono aiutarti:
- Trasformatore HTML Il crawler inizialmente estrae tutto il codice HTML da una pagina, quindi applica un trasformatore HTML per rimuovere i contenuti estranei. A volte il trasformatore può spingersi troppo oltre e rimuovere i contenuti che vuoi effettivamente conservare. Pertanto, la prima cosa da provare quando mancano dei contenuti è impostare questa impostazione su Nessuno in modo che nessun contenuto venga rimosso, quindi controllare il riepilogo dell’importazione.
- Mantieni elementi HTML Mantieni solo elementi HTML specifici fornendo uno o più selettori CSS. Tutti gli altri contenuti vengono ignorati, consentendoti di concentrarti sulle informazioni pertinenti.
-
Espandi elementi selezionabili Usa questa opzione per acquisire i contenuti dietro le fisarmoniche e i menu a discesa. L’impostazione predefinita copre le pagine web che seguono le pratiche di sviluppo web standard e definiscono i menu a discesa come
aria=false. Ciò significa che, se il crawler rileva un elemento di questo tipo, verrà aperto. Inserisci un selettore CSS per qualsiasi elemento su cui fare clic, come pulsanti o link che espandono il contenuto nascosto. Questo aiuta il crawler a catturare tutto il testo. Assicurati che il selettore sia valido. - Rendi permanenti i contenitori Se il contenuto espandibile si chiude quando si fa clic su un altro elemento, puoi usare questa impostazione per assicurarti che tali elementi rimangano aperti dopo aver fatto clic su di essi. Quindi, di nuovo, inserisci un selettore CSS per qualsiasi elemento su cui fare clic e rimani aperto anche dopo aver fatto clic su altri elementi, come pulsanti o link che espandono il contenuto nascosto.
-
Attendi selettore e Attesa graduale per selettore: Se la pagina ha contenuto dinamico che appare solo dopo un certo periodo di tempo, il crawler potrebbe non vederlo, a meno che non venga invitato ad attendere. Esistono due modi per indicare al crawler di attendere con un selettore CSS.
- L’impostazione Attendi contenuto dinamico determina il tempo di attesa del crawler. Se il selettore non viene trovato prima del limite di tempo, viene considerata una richiesta non riuscita e riprova un paio di volte.
- Il selettore Attesa temporanea per il tempo di attesa del crawler, ma garantisce anche che il crawler continui a eseguire la ricerca per indicizzazione della pagina se il selettore non viene trovato, impedendo errori.
- Queste impostazioni non funzionano con il tipo di crawler client HTTP non elaborato (Cheerio) perché non riceve alcun contenuto JavaScript.
- Altezza massima di scorrimento: Alcune pagine sono così lunghe che il crawler si arrende prima della fine. Se i contenuti mancano al di sotto di un certo punto, puoi usare questa impostazione per forzare lo scorrimento del crawler di un numero specifico di pixel.
La scansione restituisce troppi contenuti della pagina o disordinati
Se la scansione contiene le pagine giuste, ma in quelle pagine sono presenti contenuti extra o non necessari (ad esempio, testo di marketing, navigazione, intestazioni o piè di pagina o persino cookie) che sospetti interferiscano con le risposte dell’agente AI , usa il seguente crawler avanzato impostazioni per escludere quel contenuto:
- Mantieni elementi HTML Mantieni solo elementi HTML specifici fornendo uno o più selettori CSS. Tutti gli altri contenuti vengono ignorati, consentendoti di concentrarti sulle informazioni pertinenti. Per molti centri assistenza, questo è l’approccio più semplice per garantire che il contenuto degli articoli principali sia mirato, evitando navigazione, articoli correlati e banner e intestazioni non necessari.
- Rimuovi elementi HTML Usa i selettori CSS per specificare quali elementi HTML rimuovere dalla scansione. Questo è il modo più preciso ed efficace per escludere contenuti noti specifici.
Avvertenza sulla traduzione: questo articolo è stato tradotto usando un software di traduzione automatizzata per fornire una comprensione di base del contenuto. È stato fatto tutto il possibile per fornire una traduzione accurata, tuttavia Zendesk non garantisce l'accuratezza della traduzione.
Per qualsiasi dubbio sull'accuratezza delle informazioni contenute nell'articolo tradotto, fai riferimento alla versione inglese dell'articolo come versione ufficiale.