エンティティは、特定の意味を持つ情報の断片を保持します。高度なAIエージェントは、情報をエンティティとして認識し、特定の方法で処理します。AIエージェントにエンティティを追加するには、プリセットエンティティを使用するか、独自のカスタムエンティティを作成します。
エンティティについて
エンティティは、メールアドレスのように、あらかじめ定義されたパターンを持つカスタマーのメッセージ内の情報を表します。この例では、email はプリセットのエンティティです。この情報は会話セッションに添付され、AIエージェントが後で使用できるようになります。
- 個人を特定できる情報(PII)のサニタイズ
- 会話フローで使用できるように、注文番号などの情報を収集および検証する
- カスタマーメッセージ内の製品固有の説明を理解し、識別する
エンティティを追加すると、チャット内のカスタマーメッセージで、エンティティのパターンに一致する情報を識別して処理することができます。たとえば、メールアドレスを<EMAIL>というプレースホルダでマスクしたり、エスカレーションの前にサニタイズを行う目的で、検証情報やセキュリティ情報の提供を求めることができます。エンティティを使用して、カスタマーが入力した情報がフォーマットに従っているか、リストの一部であるかを検証できます。
このデータは、フロー内で後から参照することができます。たとえば、ユーザーからメールアドレスを収集し、後で条件ブロックやカスタマーメッセージで使用できるように会話データに保存します。その後、その情報を使用してアクションを適用できます。
エンティティのリストは、優先度が最も高く、機密性が最も低いものが先頭にくるように編成することをお勧めします。
WhatsAppなど、カスタマーがボタンが使用できないチャネルでシナリオを表す番号を使う場合には、各シナリオ番号に対するタイプミスや表記揺れも考慮した、多言語対応のエンティティリストを作成できます。この場合は、機密性の高い情報から順にリストを並べるようにしてください。
数字によるエンティティ認識をシナリオで使用している場合、他のエンティティや目的の予測と混同されないよう注意が必要です。たとえば、「少々お待ちください」のように、目的として認識されることを期待している表現がある場合は、まずそうした具体的な目的を先にチェックし、その後で数字の確認を行うようにしてください。この順序を誤ると、ユーザーが「one sec(少々お待ちください)」と言った場合に、「1」という数字として処理されてしまい、本来の「待機」という目的ではなく、シナリオ1が誤ってトリガされてしまう可能性があります。
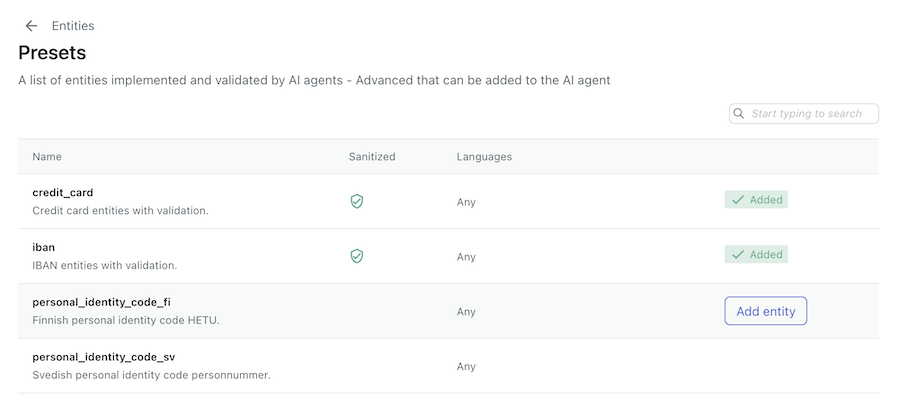
プリセットのエンティティを追加する
- 国際銀行口座番号(IBAN)
- メールアドレス
- クレジットカード
- 米国の社会保障番号(SSN)
- 各国の個人識別コード
プリセットのエンティティを追加するには
- AIエージェント - Advancedで、操作する高度なAIエージェントを選択します。
-
サイドバーで「コンテンツ」をクリックし、「エンティティ」を選択します。
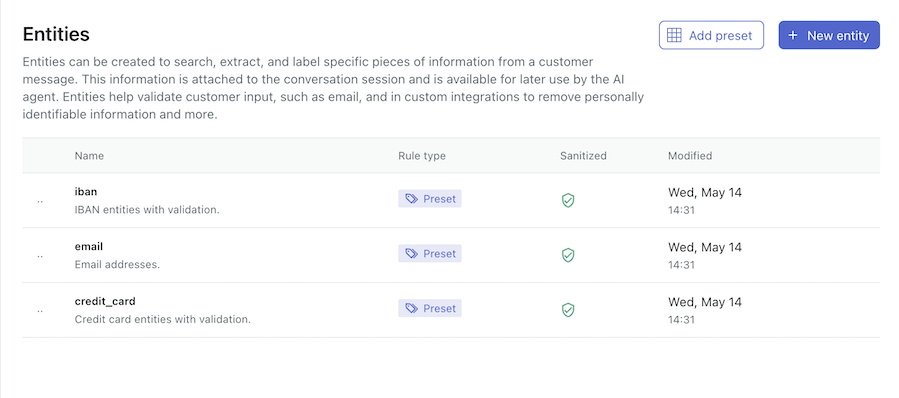
- 「プリセットを追加」をクリックします。
- 追加したいプリセットにカーソルを合わせ、「エンティティを追加」をクリックします。
- 「エンティティ」ページに戻り、右上隅にあるオプションメニュー(
 )をクリックし、「エンティティを並べ替える」を選択してエンティティの順序を変更します。
)をクリックし、「エンティティを並べ替える」を選択してエンティティの順序を変更します。
カスタムエンティティを作成する
カスタムエンティティを作成することで、独自のルールを持つエンティティを構築することができます。
カスタムエンティティを作成するには
- AIエージェント - Advancedで、操作する高度なAIエージェントを選択します。
- サイドバーで「コンテンツ」をクリックし、「エンティティ」を選択します。
- 「新しいエンティティ」を選択します。
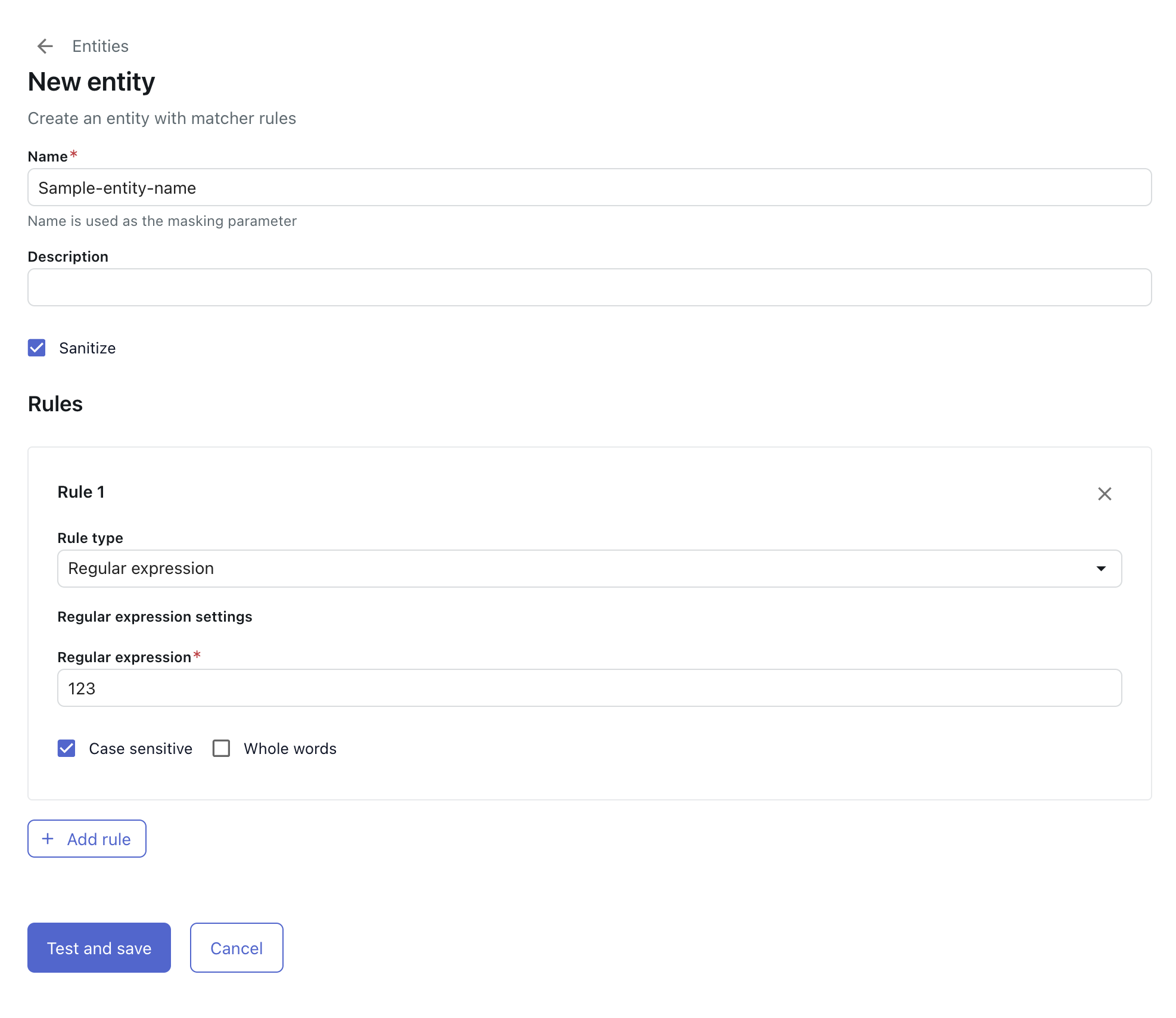
- カスタムエンティティの「名前」を入力し、オプションで「説明」を入力します。
名前にはスペースを使用できません。使用できるのは、英数字、アンダースコア(_)、およびハイフン(-)のみです。
- 検出されたカスタム情報をプレースホルダに置き換えてPIIを保護したい場合は、「サニタイズ」をクリックします。
- 「ルールタイプ」を選択し、ルールを作成します。
ルールタイプには以下のオプションがあります。
- 正規表現:RegExとも呼ばれ、繰り返しパターンの一部として表示されるテキスト文字列です。識別したい情報に対して、想定されるすべてのパターン、形式、長さをカバーするようにしてください。詳しくは「高度なAIエージェントの正規表現コレクションのリファレンス」を参照してください。
- 表現のリスト:検索対象となる単語のリストです(例:Berlin、Helsinki、Paris、Rome)。単語の一部を検出するように設定すると、「playing」の中の「play」のように、ある単語を別の単語の一部として識別できます。また、表現が単語全体を表す場合は、その単語全体として認識されます。「am」、「are」、「is」、「was」、「were」、「been」などのように形が異なっていても、補題化(lemmatization)という処理によって、どれも同じ原形の「be動詞」として扱われます。
-
同義語リスト:CSVファイルで提供される単語の組み合わせのリスト。たとえば、製品のタイプや製品の色などです。これは他のルールと混在させることはできません。次の例のようなファイル形式を使用します。
item1, "item1-synonym1, item1-synonym2, item1-synonym3, item1-synonym4" item2, "item2-synonym1, item2-synonym2, item2-synonym3, item2-synonym4" item3, "item3-synonym1, item3-synonym2, item3-synonym3, item3-synonym4"
- エンティティで大文字と小文字を区別する場合は、「大文字と小文字の区別あり」を選択します。
- 表現のリストで、表現が単語全体を表す場合は、「単語全体」を選択します。
- 必要に応じて、「ルールを追加」をクリックして、追加のルールを作成します。
- 「テストして保存」をクリックします。
「検証ルール」ウィンドウが開きます。
- サンプルテキストを入力し、「テスト」をクリックして、エンティティが予想どおりに動作していることを確認します。
- 「保存」をクリックします。