Webクローラーを使用すると、開発リソースを使わずに外部コンテンツをクロールしてインデックス登録し、Zendeskアカウント内で外部コンテンツを利用できるあらゆる場所で使用できます。複数のクローラーを設定して、同じWebサイトまたは異なるWebサイトの異なるコンテンツをクロールおよびインデックス化することができます。特定のURLのリストをクロールすることも可能です。サイト全体をクロールする必要はありません。
ユーザーがヘルプセンターで検索を実行すると、クローラーが検出した関連性の高い外部コンテンツがランク付けされて検索結果ページに表示されます。ユーザーはこの検索結果をフィルター処理したり、リンクをクリックして外部コンテンツのリンクを別のブラウザータブに表示したりできます。
Webクローラーについて
1つ以上のクローラーを設定して、同じWebサイトまたは異なるWebサイトの外部コンテンツをクロールおよびインデックス化することができます。クロールした Web サイト(サイト内ページを含む)のコンテンツは、Zendeskアカウント内で外部コンテンツを使用するあらゆる場所で利用できます。クロールする外部サイトには、Webクローラー用のページをリストアップしたサイトマップが必要です。さらに、クロールするページは、パブリック(非認証)である必要があります。
- サイト全体をクロール:クローラーは、指定した開始URLまたはサイトマップに関連付けられたサイトマップを自動的に検出し、そのサイト内のすべてのページをクロールします。
- 個別のページのみをクロール:クロール対象として最大5つのURLを指定できます。複数のURLを入力すると、「クロールをこれらのURLに限定する」オプションが自動的に選択されます。なお、開始URLを1つだけ入力した場合でも、このオプションを手動で選択することで、クロールを単一ページに制限できます。サイトマップを入力した場合は、サイトマップ内のすべてのページをクロールする必要があるため、このオプションは選択解除され、無効になります。
新しいクローラーを作成すると、クローラーに設定した名前が「ソース」の値として使用されます。「ソース」の値は、ヘルプセンター検索でフィルターとして使用されます。後で名前を変更したい場合は、いつでも編集したり別のソース名を割り当てたりできます。詳しくは「Webクローラーの管理」を参照してください。
設定が完了すると、クローラーは定期的に実行されるようスケジュールされ、サイトマップ内のページにアクセスして、その内容を収集し、ヘルプセンターの検索インデックスに取り込みます。Webクローラーはページの初回読み込み時に、アコーディオンなどのUI要素で非表示になっている場合でも、ページソース内にあるコンテンツをインデックスに追加します。ただし、クローラーはJavaScriptを実行しないため、JavaScriptによって表示されるコンテンツや、初回読み込み後に動的にレンダリングされるその他のコンテンツはクロールされません。
Webクローラーはアクセスしたページ内のリンクをたどることはなく、指定されたサイトマップ内のページのみにアクセスします。定期的に実行されるクロール時に、たとえばWebサイトがダウンしていたりネットワークに問題があったりして、情報を取得できなかった場合でも、ヘルプセンターでは前回のクロール結果が保持され、引き続き検索に使用されます。
Webクローラーの設定
- Webクローラーは、gzipファイル圧縮エンコーディングを使用するWebサイトでは機能しません。これらのサイトからの検索結果は表示されません。
- 外部サイトのrobots.txtファイルで設定されたcrawl-delayは、Webクローラーによって無視されます。
- changefreqタグはWebクローラーには何の影響も与えません。
Webクローラーを設定するには
-
ナレッジベースの管理で、サイドバーにある設定アイコン(
 )をクリックします。
)をクリックします。
- 「検索設定」をクリックします。
- 「クローラー」の「管理」をクリックします。
- 「クローラーを追加」をクリックします。

- 「続行」をクリックします。
- 「Webサイトからコンテンツを同期する」で、以下を入力します。
- クローラー名:クローラーに設定する名前。この名前は、クローラー管理リストでWebクローラーを識別するために使用されます。また、ヘルプセンター検索でフィルターとして使用される検索ソースの値の作成にも使用されます。
-
開始URL:クロールするサイトまたはページのURL。次のいずれかを行います。
- Webサイト全体をクロールする場合:プライマリドメイン(例:zendesk.com)またはサイトマップのパス(例:zendesk.com/sitemap.xml)を入力します。
-
個別のページのみをクロールする場合:このフィールドにドメイン/ページ(例:test.com/faq.htm)を入力します。「+ さらに追加」をクリックして、最大5つのURLを追加できます。
このオプションを選択すると、クローラーは設定時に指定した開始URLのみをクロールし、検索インデックスに登録します。
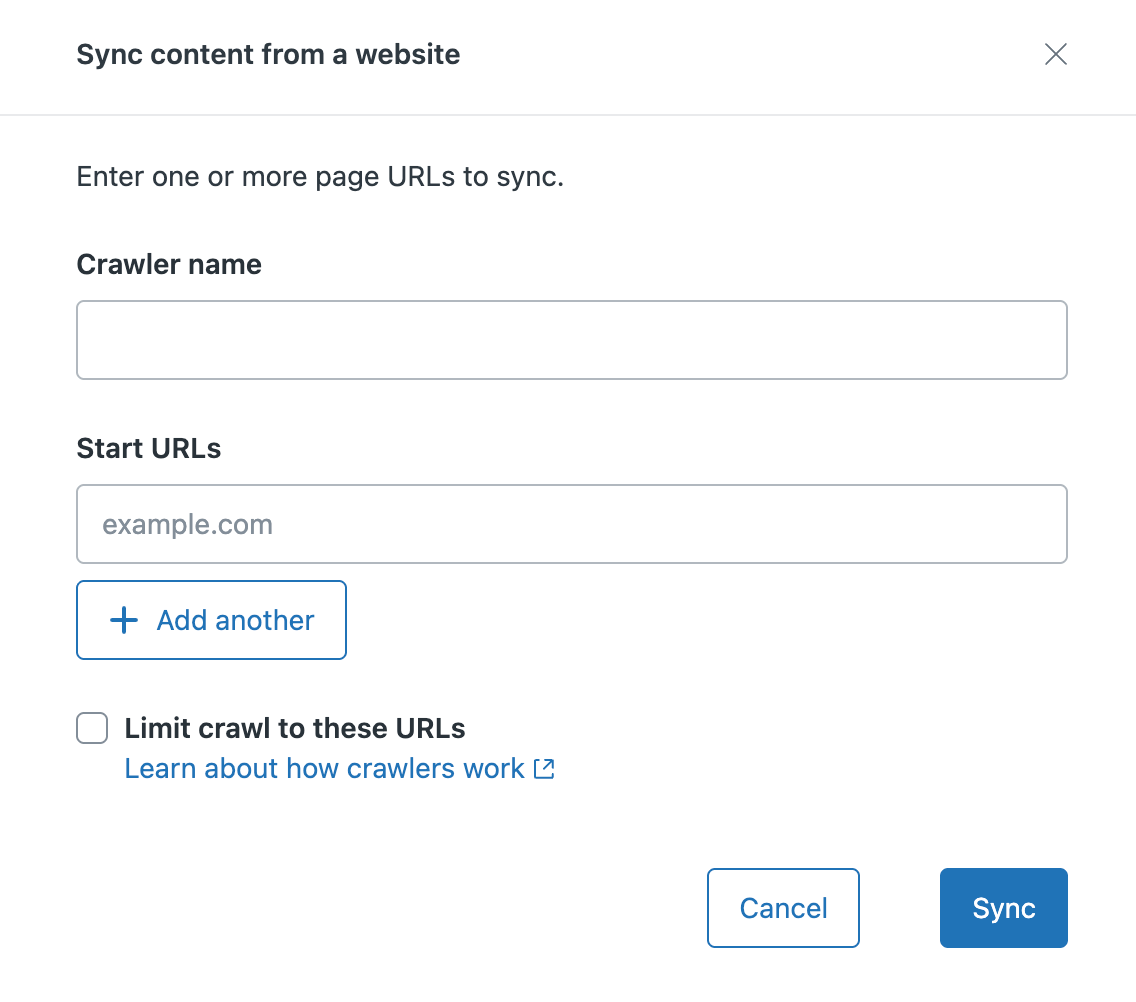
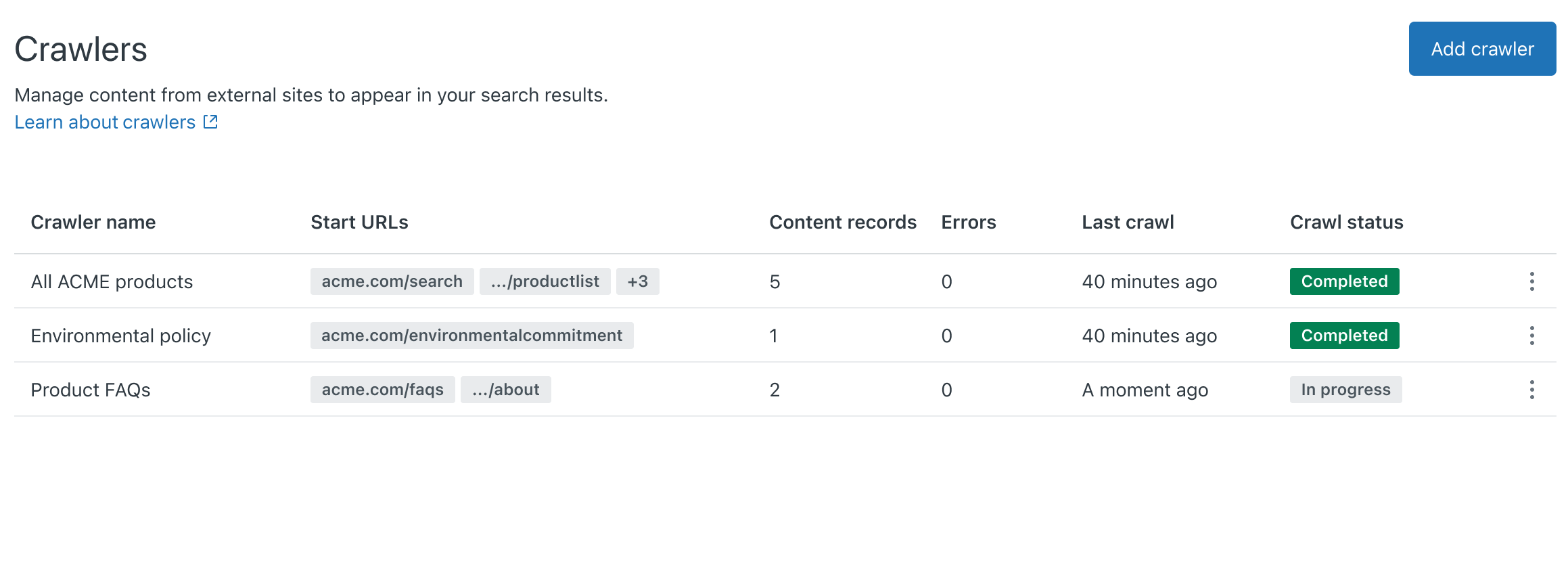
- 「同期」をクリックします。Webクローラーが「クローラー」ページに追加されます。24時間以内に、クローラーは指定されたサイトマップを取得して解析します。サイトマップの処理に成功すると、クローラーはページのクロールを開始し、コンテンツを検索インデックスに登録します。処理に失敗した場合、クローラーのオーナーに、問題解決に役立つヒントを含むメール通知が送信されます。クローラーは定期的に再試行します。メモ:Zendesk/External-Contentは、Webクローラーのユーザーエージェントです。ファイアウォールがリクエストをブロックすることでクローラーが失敗しないようにするには、Zendesk/External-Contentを許可リストに登録します。
- ヘルプセンター検索の場合は、ヘルプセンターの検索結果に含めるコンテンツと除外するコンテンツを選択する必要があります。詳しくは「ヘルプセンターの検索結果に外部コンテンツを含める方法」を参照してください。
- エージェント向けのコンテキストパネルのナレッジベースセクションについて詳しくは「コンテキストパネルのナレッジベースの設定」を参照してください。