Wissensquellen sind die Informationen, auf deren Grundlage ein AI Agent – Advanced eigene Antworten auf die Fragen von Kunden generiert. Wenn Sie Ihrem AI Agent also Wissensquellen hinzufügen, kann dieser Ihren Kunden helfen, auch ohne dass Sie für jede Antwort ein Skript erstellen müssen.
In diesem Beitrag werden folgende Themen behandelt:
Verwandte Beiträge:
Überblick über Wissensquellen
Sie können verschiedene Arten von Wissensquellen in einen AI Agent – Advanced importieren:
- Help Center: Webbasierte Help Center von Zendesk, Salesforce oder Freshdesk.
- Confluence: Confluence-Websites oder -Bereiche, in denen Ihre Organisation Inhalte speichert.
-
CSV-Dateien: Dateien im CSV-Format mit Beitragsinformationen.
Der Import von CSV-Dateien ist eine gute Lösung zum Importieren von Wissensdatenbanken, die nicht nativ unterstützt werden oder die durch Single-Sign-On (SSO) geschützt sind.
-
Mit einem Webcrawler importierte Inhalte: Informationen von einer oder mehreren Webseiten.
Am besten eignet sich der Webcrawler für den Import von Informationen aus einer Wissensdatenbank, einer FAQ-Seite oder einer Seite mit Produktbeschreibungen. Für E-Commerce-Webshops ist er weniger gut geeignet. Für den Import von E-Commerce-Seiten empfiehlt Zendesk, eine Integration zu erstellen, die in der Lage ist, relevante Produktinformationen abzurufen, und diese Informationen in einem Dialog oder einem generativen Ablauf hinzuzufügen.
Sie können einem einzelnen AI Agent mehrere Wissensquellen hinzufügen und beispielsweise Beiträge aus mehreren Zendesk Help Centern und/oder CSV-Dateien importieren. Sie sollten aber darauf achten, insgesamt nicht allzu viele Wissensquellen zu verwenden. Eine zu große Anzahl von Wissensquellen kann unter Umständen die Genauigkeit beeinträchtigen und die Latenz erhöhen.
Es ist wichtig zu wissen, dass Ihr AI Agent die Live-Daten eines Help Centers, einer Datei oder einer Website nicht selbst durchsucht. Vielmehr werden die Informationen einmalig oder in regelmäßigen Zeitabständen in den AI Agent importiert und die Antworten des AI Agent anhand dieser importierten Informationen generiert.
Importieren einer Wissensquelle
Client-Administratoren können die folgenden Wissensquellen für einen AI Agent importieren:
Importieren eines Zendesk Help Centers
Client-Administratoren können ein Zendesk Help Center importieren.
So importieren Sie ein Zendesk Help Center
- Wählen Sie auf der Seite „AI Agents – Advanced“ den gewünschten AI Agent aus.
- Klicken Sie in der Seitenleiste auf Inhalt und dann auf Wissen.
- Klicken Sie in der Registerkarte „Wissensquellen“ auf Quelle hinzufügen.
Das Fenster „Quelle hinzufügen“ wird geöffnet.
- Wählen Sie unter Typ die Option Zendesk aus.
- Geben Sie unter Help-Center-URL Ihre Subdomäne ein, einschließlich Help-Center-Gebietsschema (zum Beispielhttps://IhreSubdomäne.zendesk.com/hc/de).
Wenn Sie kein Gebietsschema angeben, wird das Standardgebietsschema des Help Centers hochgeladen.
- Geben Sie im Feld Quellenname einen Namen für Ihre Quelle ein.
Dieser Name wird für Berichte in AI Agents – Advanced verwendet.
- Geben Sie unter Importhäufigkeit an, in welchen Zeitabständen der Help-Center-Inhalt erneut importiert werden soll:
- Täglich: Der Inhalt wird einmal pro Tag (außer an Sonntagen und am 15. des Monats) neu importiert. Diese Einstellung wird nur empfohlen, wenn Ihre Wissensquelle besonders häufig aktualisiert wird.
- Wöchentlich: Der Inhalt wird einmal pro Woche am Sonntag neu importiert.
- Monatlich: Der Inhalt wird am 15. jedes Monats neu importiert.
-
Nie: Der Inhalt wird nach dem ersten Import nicht neu importiert.
Der genaue Zeitpunkt des Neuimports ist nicht garantiert. Der Neuimport wird am geplanten Tag verarbeitet, aber nicht unbedingt immer zur selben Zeit bereitgestellt.
Ein regelmäßiger Neuimport sorgt dafür, dass der AI Agent immer auf dem neuesten Stand ist. Für die meisten Organisationen reicht ein wöchentlicher oder monatlicher Neuimport aus. Denken Sie daran, dass Sie die Inhalte jederzeit von Hand neu importieren können, wenn zwischenzeitliche Änderungen berücksichtigt werden müssen.

- Wenn Sie eingeschränkte Beiträge importieren möchten:
- Aktivieren Sie die Option Private Beiträge importieren.
- Geben Sie im Feld E-Mail die E-Mail-Adresse eines Benutzers mit Zugriffsberechtigungen für die eingeschränkten Inhalte ein.
Dabei handelt es sich normalerweise um die E-Mail-Adresse eines Wissensadministrators.
- Geben Sie in das Feld API-Zugriffstoken ein für diesen Zweck generiertes API-Token ein.
- Klicken Sie auf Importieren.
Importieren eines Salesforce Help Centers
Client-Administratoren können ein Salesforce Help Center importieren.
So importieren Sie ein Salesforce Help Center
- Wählen Sie auf der Seite „AI Agents – Advanced“ den gewünschten AI Agent aus.
- Klicken Sie in der Seitenleiste auf Inhalt und dann auf Wissen.
- Klicken Sie in der Registerkarte „Wissensquellen“ auf Quelle hinzufügen.
Das Fenster „Quelle hinzufügen“ wird geöffnet.
- Wählen Sie unter Typ die Option Salesforce aus.
- Klicken Sie auf Bei Salesforce anmelden.
- Melden Sie sich bei Ihrer Salesforce-Umgebung an.
- Geben Sie im Feld Help-Center-URL den vollständigen URL-Pfad zu Ihrem Salesforce Help Center ein.
- Geben Sie im Feld Quellenname einen Namen für Ihre Quelle ein.
Dieser Name wird für Berichte in AI Agents – Advanced verwendet.
- Geben Sie unter Importhäufigkeit an, in welchen Zeitabständen der Help-Center-Inhalt erneut importiert werden soll:
- Täglich: Der Inhalt wird einmal pro Tag (außer an Sonntagen und am 15. des Monats) neu importiert. Diese Einstellung wird nur empfohlen, wenn Ihre Wissensquelle besonders häufig aktualisiert wird.
- Wöchentlich: Der Inhalt wird einmal pro Woche am Sonntag neu importiert.
- Monatlich: Der Inhalt wird am 15. jedes Monats neu importiert.
-
Nie: Der Inhalt wird nach dem ersten Import nicht neu importiert.
Der genaue Zeitpunkt des Neuimports ist nicht garantiert. Der Neuimport wird am geplanten Tag verarbeitet, aber nicht unbedingt immer zur selben Zeit bereitgestellt.
Ein regelmäßiger Neuimport sorgt dafür, dass der AI Agent immer auf dem neuesten Stand ist. Für die meisten Organisationen reicht ein wöchentlicher oder monatlicher Neuimport aus. Denken Sie daran, dass Sie die Inhalte jederzeit von Hand neu importieren können, wenn zwischenzeitliche Änderungen berücksichtigt werden müssen.
- Klicken Sie auf Importieren.
Importieren eines Freshdesk Help Centers
Client-Administratoren können ein Freshdesk Help Center importieren.
So importieren Sie ein Freshdesk Help Center
- Wählen Sie auf der Seite „AI Agents – Advanced“ den gewünschten AI Agent aus.
- Klicken Sie in der Seitenleiste auf Inhalt und dann auf Wissen.
- Klicken Sie in der Registerkarte „Wissensquellen“ auf Quelle hinzufügen.
Das Fenster „Quelle hinzufügen“ wird geöffnet.
- Wählen Sie unter Typ die Option Freshdesk aus.
- Geben Sie in das Feld Help-Center-URL den vollständigen URL-Pfad zu Ihrem Freshdesk Help Center ein.
Sie können wahlweise Ihr gesamtes Help Center oder nur einen bestimmten Bereich Ihres Help Centers hinzufügen.
- Geben Sie im Feld Quellenname einen Namen für Ihre Quelle ein.
Dieser Name wird für Berichte in AI Agents – Advanced verwendet.
- Geben Sie unter Importhäufigkeit an, in welchen Zeitabständen der Help-Center-Inhalt erneut importiert werden soll:
- Täglich: Der Inhalt wird einmal pro Tag (außer an Sonntagen und am 15. des Monats) neu importiert. Diese Einstellung wird nur empfohlen, wenn Ihre Wissensquelle besonders häufig aktualisiert wird.
- Wöchentlich: Der Inhalt wird einmal pro Woche am Sonntag neu importiert.
- Monatlich: Der Inhalt wird am 15. jedes Monats neu importiert.
-
Nie: Der Inhalt wird nach dem ersten Import nicht neu importiert.
Der genaue Zeitpunkt des Neuimports ist nicht garantiert. Der Neuimport wird am geplanten Tag verarbeitet, aber nicht unbedingt immer zur selben Zeit bereitgestellt.
Ein regelmäßiger Neuimport sorgt dafür, dass der AI Agent immer auf dem neuesten Stand ist. Für die meisten Organisationen reicht ein wöchentlicher oder monatlicher Neuimport aus. Denken Sie daran, dass Sie die Inhalte jederzeit von Hand neu importieren können, wenn zwischenzeitliche Änderungen berücksichtigt werden müssen.
- Geben Sie im Feld API-Zugriffstoken ein für diesen Zweck in Freshdesk generiertes API-Token ein.
- Klicken Sie auf Importieren.
Importieren einer Confluence-Website oder eines Confluence-Bereichs
Client-Administratoren können eine Confluence-Website oder einen Confluence-Bereich importieren.
Confluence-Verbindungen werden in Wissen erstellt und verwaltet. Bevor Sie eine Confluence-Website oder einen Confluence-Bereich mit einem AI Agent – Advanced verbinden können, müssen Sie in Wissen eine Confluence-Verbindung erstellen.
Anders als bei anderen Wissensquellen für AI Agents – Advanced können Sie bei Confluence-Inhalten kein Intervall für den Neuimport festlegen. Confluence-Verbindungen werden automatisch alle 24 Stunden synchronisiert. Sie können die Inhalte bei Bedarf aber jederzeit manuell neu synchronisieren.
So importieren Sie eine Confluence-Website oder einen Confluence-Bereich
- Wählen Sie auf der Seite „AI Agents – Advanced“ den gewünschten AI Agent aus.
- Klicken Sie in der Seitenleiste auf Inhalt und dann auf Wissen.
- Klicken Sie in der Registerkarte „Wissensquellen“ auf Quelle hinzufügen.
Das Fenster „Quelle hinzufügen“ wird geöffnet.
- Wählen Sie unter Typ die Option Confluence aus.
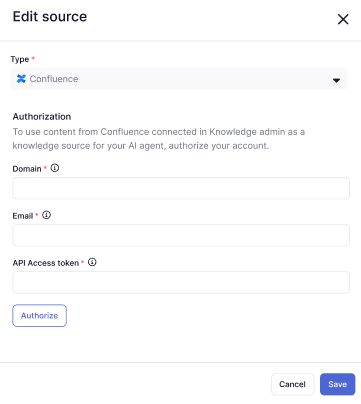
- Geben Sie unter Domäne die URL Ihrer Zendesk-Subdomäne ein (z. B.
https://yoursubdomain.zendesk.com). - Geben Sie unter E-Mail die E-Mail-Adresse eines Zendesk-Administrators ein.
- Geben Sie im Feld „API-Zugriffstoken“ ein für diesen Zweck generiertes API-Token ein.
- Klicken Sie auf Autorisieren.
- Wählen Sie eine Confluence-Website oder einen Confluence-Bereich aus, die bzw. der bereits mit Ihrem Zendesk-Konto verbunden ist, oder erstellen Sie eine neue Confluence-Verbindung.
Sie können mehrere AI Agents auswählen.
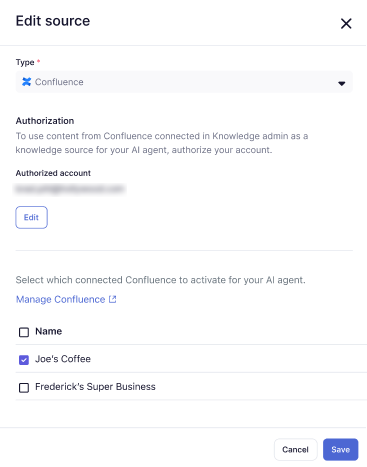
- Klicken Sie auf Speichern.
Die Confluence-Website oder der Confluence-Bereich wird zur Liste Ihrer Wissensquellen hinzugefügt.
Importieren einer CSV-Datei
Client-Administratoren können eine CSV-Datei als Wissensquelle importieren.
So importieren Sie eine CSV-Datei
- Wählen Sie auf der Seite „AI Agents – Advanced“ den gewünschten AI Agent aus.
- Klicken Sie in der Seitenleiste auf Inhalt und dann auf Wissen.
- Klicken Sie in der Registerkarte „Wissensquellen“ auf Quelle hinzufügen.
Das Fenster „Quelle hinzufügen“ wird geöffnet.
- Wählen Sie unter Typ die Option Datei (CSV) aus.
- Klicken Sie auf CSV-Datei für Wissensquelle auswählen.
- Wählen Sie die CSV-Datei aus, die Sie importieren möchten.
Achten Sie darauf, dass Ihre Datei wie im Abschnitt Formatierungsanforderungen für die CSV-Datei formatiert ist.
- Geben Sie im Feld Quellenname einen Namen für Ihre Quelle ein.
Dieser Name wird für Berichte in AI Agents – Advanced verwendet.
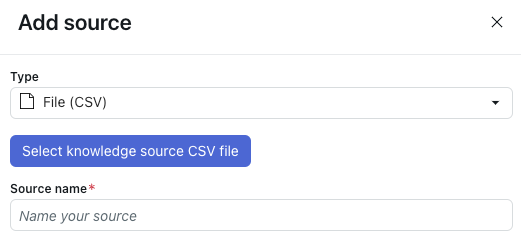
- Klicken Sie auf Importieren.
Formatierungsanforderungen für die CSV-Datei
Die CSV-Datei, die Sie als Wissensquelle hochladen, muss für jeden zu importierenden Beitrag eine eigene Zeile enthalten. Die Datei muss die folgenden Spalten aufweisen:
- title: Titel des Beitrags.
-
content: Der vollständige Inhalt des Beitrags.
- HTML-Tags werden unterstützt, sodass es nicht notwendig ist, diese aus dem Inhalt zu entfernen. Tatsächlich können diese Tags hilfreich sein, da sie die Beiträge strukturieren und dem AI Agent die Identifizierung der einzelnen Abschnitte erleichtern.
- Die Zellen können auch Markdown enthalten. Dieses muss aber gültig sein, da ihr Inhalt sonst nicht importiert wird. Außerdem muss das Markdown so geschrieben sein, dass die Zelle keine einzelne Zeile mit mehr als 2.000 Zeichen enthält, da sonst der Import ohne Warnung fehlschlägt.
Darüber hinaus können Sie die folgenden optionalen Spalten hinzufügen:
- labels: Eine Liste durch Leerzeichen getrennter Label-Namen. Sie kann beliebige Werte enthalten, nach denen Sie Inhalte kategorisieren möchten.
- locale: Dient zum Organisieren von Beiträgen nach Sprache oder Markt. Im Prinzip können Sie beliebige Werte eingeben, es wird aber empfohlen, die Standardnotation für Gebietsschemata zu verwenden.
- article_url: Die externe Webadresse, unter der der Beitrag zu finden ist. Dieser Wert wird für die Quellenzuordnung im Widget und für Berichte in AI Agents – Advanced verwendet.
Darüber hinaus sieht das Dateiformat Folgendes vor:
- Kommas (,) als Spaltentrennzeichen und doppelte Anführungszeichen (") als Textbegrenzungszeichen.
- Die erste Zeile ist als Spaltenüberschrift definiert.
- Es sind nur ASCII-Zeichen zulässig. Wenn die CSV-Datei Nicht-ASCII-Zeichen enthält, schlägt der Importvorgang fehl.
Am Ende dieses Beitrags können Sie eine Vorlage herunterladen.
Importieren von Inhalten mit einem Webcrawler
Client-Administratoren können Website-Inhalte mit einem Webcrawler importieren.
Weitere Informationen zum Importieren von Inhalten mit einem Webcrawler finden Sie unter Best Practices für das Importieren von Inhalten für AI Agents – Advanced mit einem Webcrawler und Beheben von Problemen mit Webcrawler-Importen für AI Agents – Advanced.
So importieren Sie von einem Webcrawler durchsuchte Inhalte
- Wählen Sie auf der Seite „AI Agents – Advanced“ den gewünschten AI Agent aus.
- Klicken Sie in der Seitenleiste auf Inhalt und dann auf Wissen.
- Klicken Sie in der Registerkarte „Wissensquellen“ auf Quelle hinzufügen.
Das Fenster „Quelle hinzufügen“ wird geöffnet.
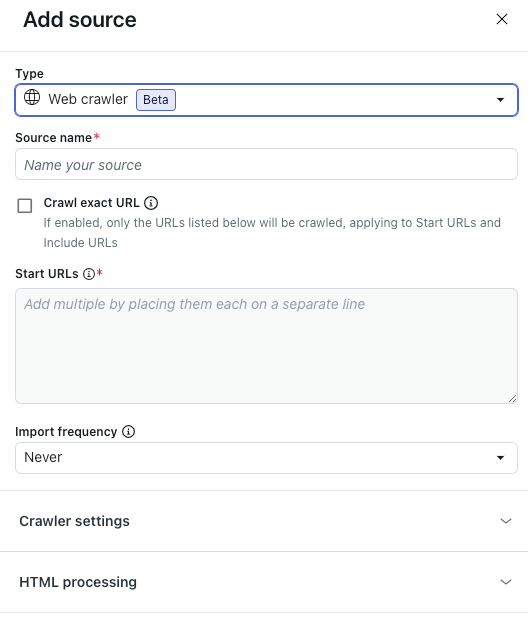
- Wählen Sie unter Typ die Option Webcrawler aus.
- Geben Sie im Feld Quellenname einen Namen für Ihre Quelle ein.
Dieser Name wird für Berichte in AI Agents – Advanced verwendet.
- Wählen Sie Exakte URL crawlen, wenn der Webcrawler nur Informationen von den im Feld „Start-URLs“ aufgeführten Webseiten importieren und deren Unterseiten ignorieren soll.
Wenn diese Option nicht ausgewählt ist, verwendet der Webcrawler für alle URLs im Feld „Start-URLs“ die maximale Crawling-Tiefe von 15 Unterseiten.
- Geben Sie im Feld Start-URLs die URLs der Seiten ein, auf denen der Webcrawler einsteigen soll.
Fügen Sie nach jeder URL einen Zeilenumbruch ein.
- Geben Sie unter Importhäufigkeit an, in welchen Zeitabständen die vom Webcrawler erfassten Inhalte erneut importiert werden sollen:
- Täglich: Der Inhalt wird einmal pro Tag (außer an Sonntagen und am 15. des Monats) neu importiert. Diese Einstellung wird nur empfohlen, wenn Ihre Wissensquelle besonders häufig aktualisiert wird.
- Wöchentlich: Der Inhalt wird einmal pro Woche am Sonntag neu importiert.
- Monatlich: Der Inhalt wird am 15. jedes Monats neu importiert.
-
Nie: Der Inhalt wird nach dem ersten Import nicht neu importiert.
Der genaue Zeitpunkt des Neuimports ist nicht garantiert. Der Neuimport wird am geplanten Tag verarbeitet, aber nicht unbedingt immer zur selben Zeit bereitgestellt.
Ein regelmäßiger Neuimport sorgt dafür, dass der AI Agent immer auf dem neuesten Stand ist. Für die meisten Organisationen reicht ein wöchentlicher oder monatlicher Neuimport aus. Denken Sie daran, dass Sie die Inhalte jederzeit von Hand neu importieren können, wenn zwischenzeitliche Änderungen berücksichtigt werden müssen.
- (Optional) Erweitern Sie den Bereich Crawler settings (Crawler-Einstellungen), um erweiterte Crawler-Einstellungen zu konfigurieren.
Weitere Informationen finden Sie unter Konfigurieren erweiterter Crawler-Einstellungen.
Hinweis: Diese Einstellungen werden nur für Organisationen mit komplexen technischen Anforderungen empfohlen und sind für viele Unternehmen nicht relevant. - (Optional) Erweitern Sie den Bereich HTML processing (HTML-Verarbeitung), um erweiterte HTML-Einstellungen zu konfigurieren.
Weitere Informationen finden Sie unter Konfigurieren erweiterter HTML-Einstellungen.
Hinweis: Diese Einstellungen werden nur für Organisationen mit komplexen technischen Anforderungen empfohlen und sind für viele Unternehmen nicht relevant. - Klicken Sie auf Importieren.
Konfigurieren erweiterter Crawler-Einstellungen
-
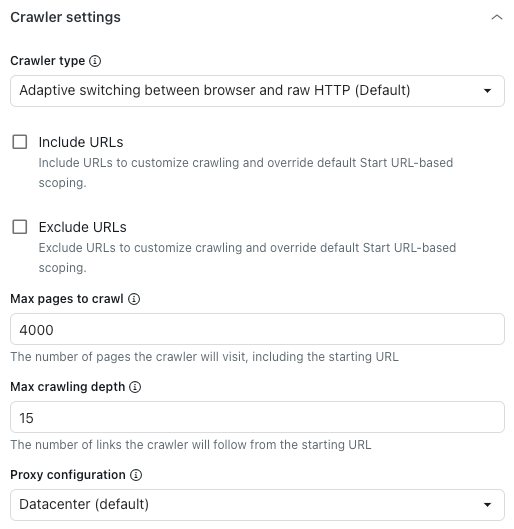
Wählen Sie in den erweiterten Crawler-Einstellungen unter Crawler type (Crawler-Typ) eine der folgenden Optionen aus:
- Adaptive switching between browser and raw HTTP (Default): Schnell, stellt vorhandene JavaScript-Inhalte dar.
- Headless browser (Firefox + Playwright): Zuverlässig, stellt JavaScript-Inhalte dar, vermeidet Blockierungen am besten, kann aber langsam sein.
- Raw HTTP client (Cheerio): Am schnellsten, stellt aber keine JavaScript-Inhalte dar.
- Raw with JavaScript: Crawlt den Inhalt der Seite mit JavaScript.
- Wählen Sie URLs einschließen oder URLs ausschließen, um den oben im Feld „Start-URLs“ festgelegten Crawling-Bereich anzupassen.
Geben Sie die URLs, die Sie ein- bzw. ausschließen möchten, in die entsprechenden Felder ein. Fügen Sie nach jeder URL einen Zeilenumbruch ein.
Diese Einstellungen betreffen nur die beim Crawlen von Unterseiten gefundenen Links. Wenn Sie eine Seite crawlen möchten, müssen Sie deren URL im Feld „Start-URLs“ angeben.Angenommen, die URL-Struktur ist wie in diesem Beispiel inkonsistent:
- Start-URL:
https://support.example.com/en/support/home - Beitrags-URL:
https://support.example.com/en/support/solutions/articles/…
-
https://support.example.com/en/support/**
Dies bewirkt, dass der Webcrawler alle Beiträge durchsucht, auch wenn deren Pfad von der Start-URL abweicht.
Ein weiteres Beispiel: Die folgende Website ist sehr umfangreich und enthält irrelevante Seiten (z. B. die Seite „careers“ mit Stellenangeboten).- Start-URL:
https://www.example.com/en
https://www.example.com/en/careers/**
Tipp: Wenn Sie mehr Funktionen benötigen, als reiner Text bietet, können Sie Globs verwenden. Diese ermöglichen die Verwendung von Sonderzeichen, mit denen sich dynamische URLs für den Webcrawler erstellen lassen. Hier einige Beispiele:-
https://support.example.com/**lässt den Crawler auf alle URLs zugreifen, die mit https://support.example.com/ beginnen. -
https://{store,docs}.example.com/**lässt den Crawler auf alle URLs zugreifen, die mit https://store.example.com/ oder https://docs.example.com/ beginnen. -
https://example.com/**/*\?*foo=*ermöglicht dem Crawler den Zugriff auf alle URLs, die den Query-Parameter „foo“ mit einem beliebigen Wert enthalten.
- Start-URL:
- Geben Sie unter Maximal zu crawlende Seiten an, wie viele Seiten der Crawler maximal erfassen soll.
Hierzu zählen auch die Start-URL, Paginierungsseiten, Seiten ohne Inhalt usw. Sobald dieses Limit erreicht ist, wird der Crawler automatisch gestoppt.
- Geben Sie unter Maximale Crawling-Tiefe an, wie vielen Links der Webcrawler von der Start-URL aus maximal folgen soll.
Die Start-URL hat eine Tiefe von 0. Seiten, die direkt auf der Start-URL-Seite verlinkt sind, haben eine Tiefe von 1 usw. Verwenden Sie diese Einstellung, um zu verhindern, dass der Crawler versehentlich zu weit läuft.
- Wählen Sie unter Proxy-Konfiguration eine der folgenden Optionen aus:
- Rechenzentrum (Standard): Schnellste Methode zum Daten-Scraping.
-
Stationär: Weniger Leistung, aber weniger wahrscheinlich blockiert. Das ist optimal, wenn der Standard-Proxy blockiert ist oder Sie von einem bestimmten Land aus crawlen möchten.
Konfigurieren erweiterter HTML-Einstellungen
-
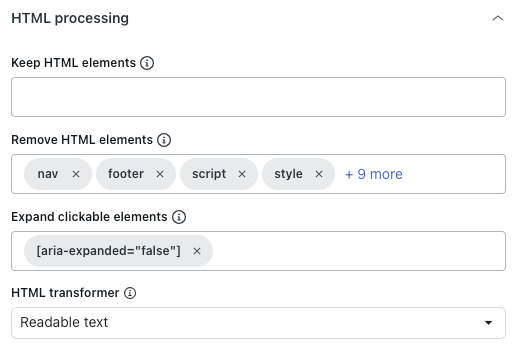
Geben Sie im Bereich „HTML processing“ (HTML-Verarbeitung) unter Keep HTML elements (HTML-Elemente beibehalten) einen CSS-Selektor ein, um nur bestimmte HTML-Elemente beizubehalten.
Alle übrigen Inhalte werden entfernt, sodass Sie sich ganz auf die relevanten Informationen konzentrieren können.
- Geben Sie unter Remove HTML elements (HTML-Elemente entfernen) an, welche HTML-Elemente vor der Konvertierung in Text bzw. Markdown oder vor dem Speichern als HTML entfernt werden sollen.
Diese Funktion dient dazu, unerwünschte Inhalte auszuschließen.
- Geben Sie unter Expand clickable elements (Anklickbare Elemente erweitern) einen gültigen CSS-Selektor ein, der den DOM-Elementen entspricht, die angeklickt werden sollen.
Diese Funktion ermöglicht das Erweitern reduzierter Abschnitte, deren Textinhalt erfasst werden soll.
- Wählen Sie unter HTML-Transformer einen der folgenden Werte aus, um anzugeben, wie der HTML-Code von überflüssigen Inhalten wie Navigations- oder Popup-Elementen bereinigt werden soll, damit nur wichtige Inhalte erhalten bleiben:
- Extractus: (Nicht empfohlen) Verwendet die Extractus-Bibliothek.
- Keine: Entfernt nur die oben mit der Option „Remove HTML elements“ (HTML-Elemente entfernen) festgelegten HTML-Elemente.
- Lesbarer Text: Verwendet die Readability-Bibliothek von Mozilla, um den eigentlichen Inhalt des Beitrags zu extrahieren und Navigationselemente, Kopfzeilen, Fußzeilen und andere unwesentliche Elemente zu entfernen. Am besten geeignet für Blogs und Websites mit vielen Beiträgen.
-
Readable text if possible (Lesbarer Text falls möglich): Verwendet die Readability-Bibliothek von Mozilla, um den eigentlichen Inhalt zu extrahieren, greift aber auf den ursprünglichen HTML-Code zurück, wenn die Seite offenbar keinen Beitrag enthält. Diese Funktion ermöglicht die Verarbeitung von Websites mit verschiedenartigen Inhalten (z. B. Beiträgen und Produktseiten), da bei Seiten, die keine Beiträge enthalten, mehr Inhalte erhalten bleiben.
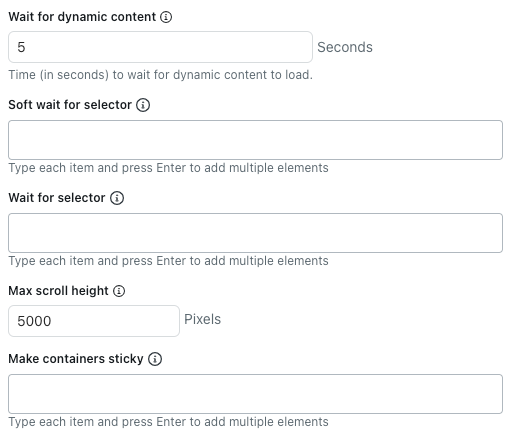
- Geben Sie unter Wait for dynamic content (Auf dynamische Inhalte warten) an, wie viele Sekunden der Crawler auf das Laden dynamischer Inhalte warten soll. Standardmäßig wartet er fünf Sekunden oder bis die Seite fertig geladen ist, je nachdem, was zuerst eintritt.
- Geben Sie unter Soft wait for selector (Ohne Anhalten auf Selektor warten) CSS-Selektoren für HTML-Elemente ein, die vollständig geladen sein sollten, bevor der Crawler mit dem Extrahieren der Inhalte beginnt.
Der Crawler durchsucht eine Seite auch dann, wenn eines der angegebenen Elemente nicht vorhanden ist.
Fügen Sie nach jedem CSS-Selektor einen Zeilenumbruch ein.
- Geben Sie unter Wait for selector (Auf Selektor warten) CSS-Selektoren für HTML-Elemente ein, die vollständig geladen sein müssen, bevor der Crawler mit dem Extrahieren der Inhalte beginnt.
Wenn eines der angegebenen Elemente fehlt, durchsucht der Crawler die Seite nicht.
Fügen Sie nach jedem CSS-Selektor einen Zeilenumbruch ein.
- Geben Sie unter Max scroll height (Maximale Scrollhöhe) an, wie viele Pixel der Crawler maximal scrollen soll.
Der Crawler scrollt die Seite, um weitere Inhalte zu laden, bis das Netzwerk inaktiv wird oder die eingestellte Scrollhöhe erreicht ist. Setzen Sie den Wert auf 0, um das Scrollen vollständig zu deaktivieren.
Für den Raw HTTP Client wird diese Einstellung nicht verwendet, da dieser kein JavaScript ausführt und keine dynamischen Inhalte lädt.
- Geben Sie unter Make containers sticky (Container-Elemente beibehalten) CSS-Selektoren für HTML-Elemente ein, deren untergeordnete Inhalte beibehalten werden sollten, auch wenn sie ausgeblendet sind.
Fügen Sie nach jedem CSS-Selektor einen Zeilenumbruch ein.
Das ist hilfreich, wenn Sie die Option „Expand clickable elements“ (Anklickbare Elemente erweitern) auf Seiten verwenden, die verborgene Inhalte vollständig von der Seite entfernt.