Você pode usar um rastreador da web para importar conteúdo a ser usado pelo agente de IA. Isso proporciona ao agente de IA a capacidade de se basear em informações de sites externos para criar respostas geradas por IA para perguntas dos clientes.
Este artigo ajuda você a resolver problemas que possa encontrar durante ou uso de um rastreador da web para importar conteúdo a ser utilizado por um agente de IA e contém os seguintes tópicos:
O rastreador apresentou falha devido ao tempo limite
Quando um rastreador da web apresenta falha após várias horas, em geral ela é causada pelo limite de tempo. Os rastreadores são limitados a cinco horas por padrão. Se a falha ocorreu cinco horas depois do início da importação, a causa provável é o tempo limite.
Se isso acontecer, tente estas etapas de resolução:
- Se o site não depende de JavaScript, defina o tipo de rastreador como Cliente HTTP bruto (Cheerio), que é um rastreador muito mais rápido, e tente novamente.
- Caso você saiba que o site inclui conteúdo que não é necessário, consulte O rastreador inclui páginas desnecessárias.
- Divida o rastreador em dois ou mais rastreadores separados (usando as configurações Incluir URLs ou Excluir URLs) para cada qual extrair apenas partes do site.
O rastreador está ignorando páginas
Se o rastreador estiver ignorando URLs ou artigos inteiros, aumente o escopo dele usando URLs iniciais e Incluir URLs. Caso você tenha certeza de que as configurações estão corretas, mas ainda assim faltarem artigos, verifique o número de páginas rastreadas no resumo de importação. Se esse número estiver próximo do padrão de máximo de páginas a serem rastreadas (4.000), tente aumentar essa configuração.
O rastreador inclui páginas desnecessárias
Se o rastreador inclui mais páginas ou artigos do que o necessário (por exemplo, conteúdo repetitivo ou inaplicável, como páginas em inglês quando você só precisa de português ou conteúdo não necessário para o agente de IA responder a perguntas dos clientes), use a configuração Excluir URLs.
Tome cuidado para evitar a exclusão acidental de determinadas subpáginas. As URLs iniciais definem onde o rastreador começa. Em seguida, ele segue todos os links daquela página e das páginas subsequentes até a Profundidade máxima de rastreamento especificada. No entanto, se você excluir páginas, as páginas vinculadas apenas de páginas excluídas nunca serão rastreadas, a menos que sejam especificadas separadamente como URLs iniciais.
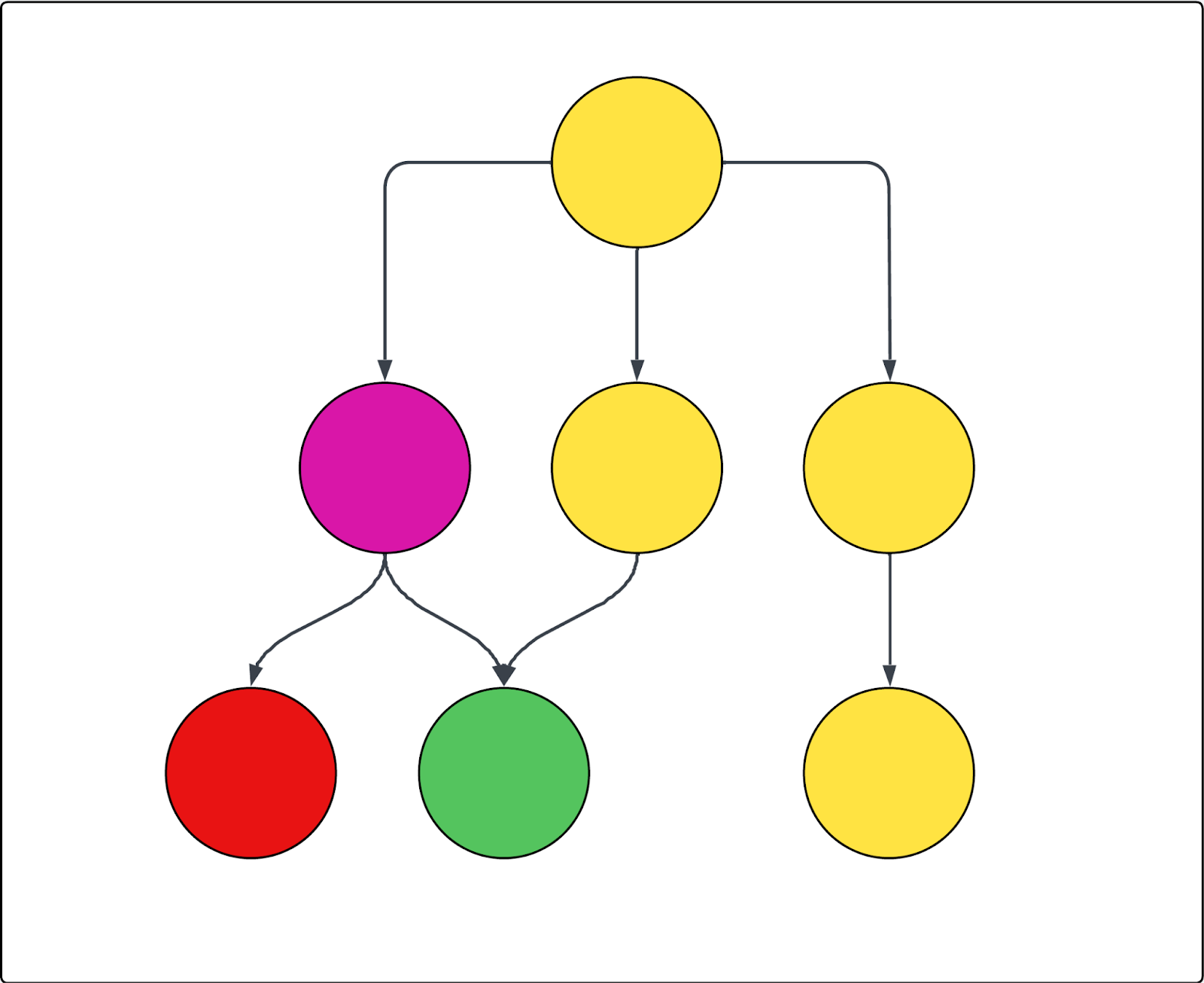
Veja um exemplo no diagrama abaixo. Cada círculo representa uma página, e cada seta representa um link naquela página. Se o rastreador inicia na página superior (como quando ela é a única URL inicial) e a página roxa é excluída, os seguintes itens são verdadeiros:
- A página vermelha não pode ser rastreada
- Todas as páginas amarelas são rastreadas
- A página verde também é rastreada, mesmo que esteja vinculada na página roxa excluída, porque ela também está vinculada em uma das páginas amarelas incluídas.
O rastreador inclui as páginas corretas, porém o conteúdo errado
Se o rastreador retorna as páginas corretas, porém o conteúdo errado dentro dessas páginas, as configurações avançadas do navegador incluem ferramentas para encontrar e incluir ou excluir esse conteúdo. Você precisa encontrar o seletor de CSS correto para o elemento que você quer incluir o excluir e depois inseri-lo na configuração apropriada. Para fazer isso, é útil compreender o que é um seletor de CSS e como encontrá-lo.
Esta seção contém os tópicos a seguir:
Noções básicas e localização de seletores de CSS
Esta sessão apresenta os seletores de CSS e orienta você sobre como encontrar o seletor correto. Se você já estiver familiarizado com essas informações, pule para as seções de solução de problemas abaixo.
Esta seção contém os tópicos a seguir:
Sobre seletores de CSS
Os seletores de CSS são padrões usados para selecionar e mirar elementos de HTML específicos em uma página da web. Eles facilitam a localização e extraem das de páginas da web complexas exatamente os dados de que você precisa.
Em ações de rastreamento e extração na web, os seletores de CSS ajudam a extrair dados indicando as partes exatas da estrutura de uma página, como <div>, <span> ou elementos com determinadas classes e IDs. Por exemplo, o seletor .product-title mira todos os elementos com a classe "product-title". O sinal de cerquilha (#) é usado para selecionar elementos por seu ID único. Por exemplo, #main-header seleciona o elemento com id="main-header".
Localização de um seletor de CSS
Primeiro você precisa encontrar o seletor de CSS que quer usar. As instruções a seguir pressupõem que você esteja usando o navegador Chrome. No entanto, as etapas são semelhantes nos demais navegadores.
Como localizar um seletor CSS:
- Localize o texto ou item clicável na página da web que você quer segmentar
-
Dê um clique com o botão direito no elemento e selecione Inspectar.
O painel Chrome DevTools é aberto e o código correspondente aparece em destaque.
-
No painel DevTools, clique com o botão direito no código destacado e selecione Copiar > Copiar seletor.
O seletor de CSS é copiado para a área de transferência.
Verificação de um seletor de CSS
Depois de encontrar o seletor de CSS, é uma boa ideia verificá-lo.
Para verificar o seletor de CSS:
-
Com o DevTools ainda aberto, pressione Ctrl+F (Windows ou Linux) ou Cmd+F (Mac).
Essa ação ativa uma barra de pesquisa dentro da aba Elementos do painel DevTools.
- Cole o seletor de CSS recém-copiado nesta caixa de pesquisa
- Verifique se os elementos destacados no HTML e na própria página (em geral com um contorno colorido) correspondem ao esperado
Se o único elemento destacado é o que você queria, o seletor está preciso. Se houver elementos destacados demais ou incorretos, tente um elemento pai ou ajuste a seleção.
Você também tem a opção de testar seletores diferentes. Às vezes, seletores mais curtos ou específicos funcionam melhor. Você pode clicar em elementos pais ou filhos no HTML para ver as classes CSS ou IDs deles e tentar copiar esses seletores também.
As duas seções a seguir mostram como usar esses seletores para segmentar o conteúdo que você quer ou não rastrear.
O rastreador está ignorando o conteúdo das páginas
Se o rastreador tem as páginas corretas, mas está ignorando algum conteúdo delas, estas configurações avançadas de rastreador podem ajudar:
- Transformador de HTML: o rastreador inicialmente extrai todo o HTML de uma página e depois aplica um transformador de HTML para remover o conteúdo desnecessário. Algumas vezes, o transformador pode ir longe demais e remover conteúdo que você quer manter. Portanto, a primeira coisa a tentar quando falta conteúdo é ativar essa configuração como Nenhum para que nenhum conteúdo seja removido e depois verificar o resumo de importação
- Manter elementos HTML: mantenha apenas elementos HTML específicos fornecendo um ou mais seletores de CSS. Todo o restante do conteúdo é ignorado, ajudando você a se concentrar nas informações relevantes
-
Expandir elementos clicáveis: use essa opção para capturar o conteúdo acessado por meio de menus dos tipos acordeão e suspenso. A configuração padrão se destina a abranger páginas da web que seguem a prática padrão de desenvolvimento para web e definem menus suspensos como
aria=false. Ou seja, se encontrado pelo rastreador, esse elemento será aberto com um clique. Insira um seletor de CSS para qualquer elemento que deve ser clicado, como botões ou links que expandem um conteúdo oculto. Isso ajuda o rastreador a capturar todo o texto. Verifique se o seletor é válido - Fixar contêineres: se o conteúdo expansível fecha quando um elemento diferente é clicado, você pode usar essa configuração para garantir que tal elemento continue aberto depois de ser clicado. De novo, insira um seletor de CSS para qualquer elemento que deve ser clicado e depois permanecer aberto mesmo após outros elementos serem clicados, como botões ou links que expandem um conteúdo oculto
-
Aguardar pelo seletor e Aguardar o seletor suavemente: Se a página tem um conteúdo dinâmico que aparece apenas após um determinado tempo, ele pode ser ignorado, a menos que o rastreador seja direcionado para aguardar. Existem duas maneiras de dizer ao rastreador para aguardar com um seletor de CSS.
- A configuração Aguarde o conteúdo dinâmico determina quanto tempo o rastreador espera. Caso o seletor não seja encontrado antes do limite de tempo, considera-se que houve uma falha de solicitação e são feitas novas tentativas.
- A opção Aguardar o seletor determina quanto tempo o rastreador espera, mas também assegura que ele continue a rastrear a página se o seletor não for encontrado, o que previne falhas.
- Essas configurações não funcionam com o tipo de rastreador de cliente HTTP bruto (Cheerio), pois ele não obtém conteúdo JavaScript.
- Altura máxima de rolagem: algumas páginas são tão longas que o rastreador desiste antes do final. Caso falte conteúdo abaixo de um determinado ponto, você pode usar essa configuração para forçar o rastreador a fazer a rolagem de um número específico de pixels.
O rastreador está retornando conteúdo excessivo ou confuso das páginas
Se o rastreador tem as páginas corretas, mas inclui conteúdo extra ou desnecessário nessas páginas (por exemplo, texto de marketing, navegação, cabeçalhos ou rodapés ou até mesmo cookies) que você suspeita que esteja interferindo nas respostas do agente de IA, use estas configurações avançadas do rastreador para excluir tal conteúdo:
- Manter elementos HTML: mantenha apenas elementos HTML específicos fornecendo um ou mais seletores de CSS. Todos o restante do conteúdo será ignorado, ajudando você a se concentrar nas informações relevantes. Em muitas centrais de ajuda, esta é a abordagem mais simples para garantir que o conteúdo principal do artigo seja direcionado e evitar conteúdo de navegação e artigos relacionados, além de banners e cabeçalhos desnecessários.
- Remover elementos HTML: use seletores de CSS para especificar quais elementos HTML devem ser removidos do rastreador. Esta é a maneira mais precisa e relevante de excluir conteúdo específico e conhecido
Artigos relacionados:
- Práticas recomendadas para uso de um rastreador da web na importação de conteúdo para agentes de IA
- Gerenciamento de fontes de conhecimento importadas para agentes de IA
Aviso sobre a tradução: este artigo foi traduzido por um software de tradução automática para oferecer a você uma compreensão básica do conteúdo. Medidas razoáveis foram tomadas para fornecer uma tradução precisa, no entanto, a Zendesk não garante a precisão da tradução.
Em caso de dúvidas relacionadas à precisão das informações contidas no artigo traduzido, consulte a versão oficial do artigo em inglês.