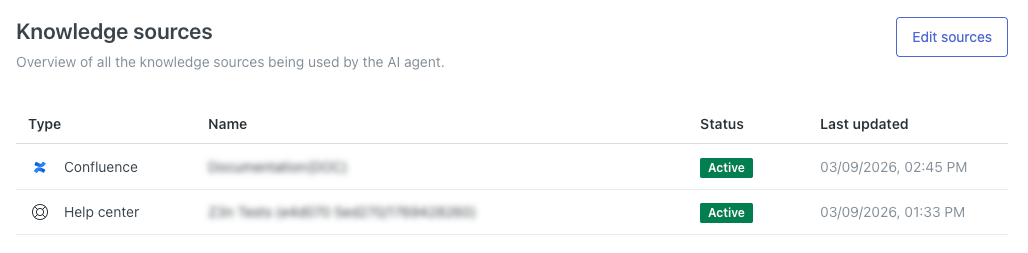
As fontes de conhecimento são as informações que seu agente de IA usa para criar respostas geradas por IA para as dúvidas de clientes. A inclusão de fontes de conhecimento em seu agente de IA permite que ele gere respostas para ajudar os clientes sem que você precise escrever cada resposta.
Este artigo contém os seguintes tópicos:
- Sobre fontes de conhecimento
- Conexão de uma central de ajuda do Zendesk a um agente de IA
- Conexão de uma fonte de conhecimento externa a um agente de IA
- Desconexão de uma fonte de conhecimento
- Importação de uma fonte de conhecimento (legado)
- Visualização de todas as fontes de conhecimento conectadas
Artigo relacionado:
Sobre fontes de conhecimento
É possível conectar os seguintes tipos de fontes de conhecimento a um agente de IA:
- Centrais de ajuda do Zendesk: a central de ajuda associada à sua conta Zendesk (ou a uma marca específica, caso tenha configurado várias marcas).
- Fontes de conhecimento externas: conteúdo de fontes externas, que é importado para sua conta Zendesk por meio de um rastreador da web ou um conector de conhecimento.
Você pode adicionar várias fontes de conhecimento a um único agente de IA. Por exemplo, você pode conectar várias centrais de ajuda do Zendesk, várias fontes externas ou uma combinação de ambas. No entanto, recomendamos que você tenha um limite razoável de fontes de conhecimento. O excesso de fontes pode, em alguns casos, resultar em menor precisão e maior latência.
Quando um agente de IA pesquisa em uma central de ajuda conectada, essa pesquisa do conteúdo é realizada em tempo real. No entanto, quando um agente de IA pesquisa uma fonte de conhecimento externa conectada, ele pesquisa as informações que estavam disponíveis na última sincronização, que geralmente ocorre a cada 24 horas.
Quando você usa conteúdo restrito da central de ajuda, as respostas do agente de IA respeitam as permissões de visualização do artigo. Isso significa que:
- Se o cliente for autenticado, o agente de IA pode usar artigos restritos relevantes para gerar respostas.
- Se o cliente não for autenticado, o agente de IA pode usar somente artigos públicos para gerar respostas.
Para obter mais informações, consulte Uso de conteúdo restrito da central de ajuda em respostas do agente de IA.
Conexão de uma central de ajuda do Zendesk a um agente de IA
Você pode conectar uma central de ajuda do Zendesk a um agente de IA para que o agente possa usar o conteúdo da central de ajuda para gerar respostas às perguntas dos clientes.
Sua central de ajuda precisa ser ativada antes que você possa conectá-la a um agente de IA.
Como conectar uma central de ajuda do Zendesk
- No espaço de trabalho dos agentes de IA, selecione o agente de IA com o qual deseja trabalhar.
- Clique em
 Conteúdo na barra lateral e selecione Fontes de conhecimento.
Conteúdo na barra lateral e selecione Fontes de conhecimento. - Clique em Editar origens.
Uma caixa de diálogo de fontes de conhecimento é exibida.
- No campo na parte superior, selecione Central de ajuda.
- Na lista, selecione a central de ajuda do Zendesk à qual você deseja conectar o agente de IA.
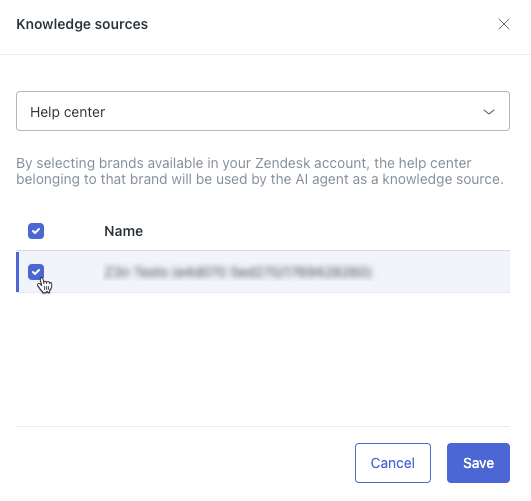 Dica: se você não encontrar a central de ajuda, verifique se ela está ativada.
Dica: se você não encontrar a central de ajuda, verifique se ela está ativada. - Clique em Salvar.
Sua central de ajuda aparece na lista de fontes de conhecimento.
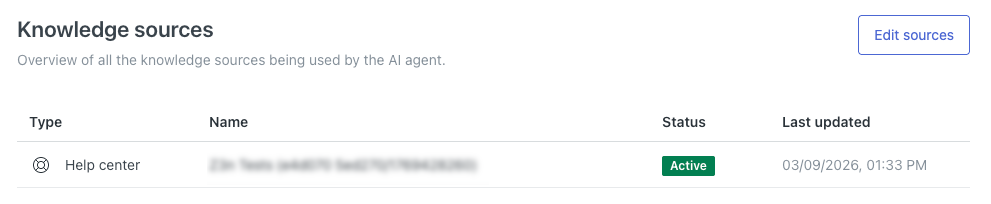
Conexão de uma fonte de conhecimento externa a um agente de IA
É possível conectar uma fonte de conhecimento externa a um agente de IA para que ele use as informações dessa fonte ao gerar respostas para perguntas dos clientes.
Como conectar uma fonte de conhecimento externa
- Caso ainda não tenha feito essa etapa, conecte uma fonte de conhecimento externa à sua conta Zendesk.
- No espaço de trabalho dos agentes de IA, selecione o agente de IA com o qual deseja trabalhar.
- Clique em Conteúdo na barra lateral e selecione Fontes de conhecimento.
- Clique em Editar origens.
Uma caixa de diálogo de fontes de conhecimento é exibida.
- No campo na parte superior, selecione Conteúdo externo.
- Na lista, expanda o tipo de fonte de conhecimento externa, se necessário, e selecione a fonte que deseja conectar ao agente de IA.
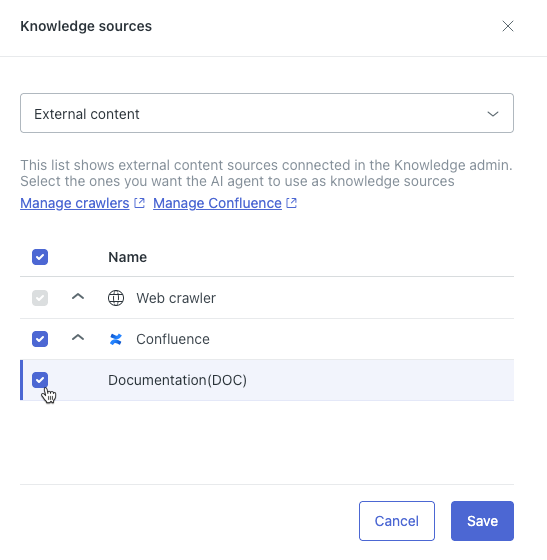
- Clique em Salvar.
Sua fonte de conhecimento externa aparece na lista de fontes de conhecimento.
Desconexão de uma fonte de conhecimento
Você pode desconectar uma fonte de conhecimento de um agente de IA para evitar que ele use as informações dessa fonte ao gerar as respostas para perguntas dos clientes.
Como desconectar uma fonte de conhecimento
- No espaço de trabalho dos agentes de IA, selecione o agente de IA com o qual deseja trabalhar.
- Clique em Conteúdo na barra lateral e selecione Fontes de conhecimento.
- Clique em Editar origens.
Uma caixa de diálogo de fontes de conhecimento é exibida.
- No campo na parte superior, selecione Central de ajuda ou Conteúdo externo.
Na lista, desmarque a fonte de conhecimento que você quer desconectar.
- Clique em Salvar.
A fonte de conhecimento desconectada é removida da lista de fontes de conhecimento.
Importação de uma fonte de conhecimento (legado)
Os administradores do cliente podem importar os seguintes tipos de fontes de conhecimento para um agente de IA:
Importação de uma central de ajuda do Zendesk (legado)
Os administradores do cliente podem importar uma central de ajuda do Zendesk.
Como importar uma central de ajuda do Zendesk
- No espaço de trabalho dos agentes de IA, selecione o agente de IA com o qual deseja trabalhar.
- Clique em Conteúdo na barra lateral e selecione Fontes de conhecimento.
- Clique em Adicionar fonte.
O painel Adicionar fonte é aberto.
- Em Tipo, selecione Zendesk.
- Em URL da central de ajuda, insira seu subdomínio, incluindo a localidade da central de ajuda (por exemplo, https://seusubdominio.zendesk.com/hc/en-us).
Se você não fornece uma localidade, a localidade padrão da central de ajuda é carregada.
- Em Nome da fonte, insira um nome para sua fonte.
Este nome é usado nos relatórios do painel de relatórios dos agentes de IA.
- Em Frequência de importação, selecione com que frequência o conteúdo da central de ajuda deve ser reimportado.
- Diariamente: o conteúdo é reimportado todos os dias, exceto aos domingos e no 15º dia do mês. Não recomendado a menos que sua fonte de conhecimento seja atualizada com muita frequência.
- Semanalmente: o conteúdo é reimportado a cada semana aos domingos.
- Mensalmente: o conteúdo é reimportado no 15º dia de cada mês.
-
Nunca: o conteúdo é importado uma vez e não será mais reimportado.
O tempo exato da reimportação não é garantido. A reimportação é processada ao longo do dia em que está programada, mas pode não estar pronta sempre no mesmo horário.
A reimportação recorrente mantém o agente de IA atualizado. Para a maioria das organizações, o ritmo semanal ou mensal é suficiente. Lembre-se de que sempre é possível reimportar manualmente, caso seja preciso refletir novas alterações fora da reimportação programada.

- Se a central de ajuda exigir que os usuários entrem, ou se você quiser importar artigos restritos por outros motivos:
- Ative a opção Importar artigos privados.
- Em E-mail, insira o endereço de e-mail de um usuário autorizado a acessar o conteúdo restrito.
Normalmente, esse é o endereço de e-mail de um administrador do Conhecimento.
- Em Token de acesso à API, insira um token de API que você gerou para essa finalidade.
- Clique em Importar.
Importação de uma central de ajuda do Salesforce (legado)
Os administradores do cliente podem importar uma central de ajuda do Salesforce.
Como importar uma central de ajuda do Salesforce
- No espaço de trabalho dos agentes de IA, selecione o agente de IA com o qual deseja trabalhar.
- Clique em Conteúdo na barra lateral e selecione Fontes de conhecimento.
- Clique em Adicionar fonte.
O painel Adicionar fonte é aberto.
- Em Tipo, selecione Salesforce.
- Clique em Entrar no Salesforce.
- Entre em seu ambiente do Salesforce.
- Na URL da central de ajuda, insira a URL completa da sua central de ajuda do Salesforce.
- Em Nome da fonte, insira um nome para sua fonte.
Este nome é usado nos relatórios do painel de relatórios dos agentes de IA.
- Em Frequência de importação, selecione com que frequência o conteúdo da central de ajuda deve ser reimportado.
- Diariamente: o conteúdo é reimportado todos os dias, exceto aos domingos e no 15º dia do mês. Não recomendado a menos que sua fonte de conhecimento seja atualizada com muita frequência.
- Semanalmente: o conteúdo é reimportado a cada semana aos domingos.
- Mensalmente: o conteúdo é reimportado no 15º dia de cada mês.
-
Nunca: o conteúdo é importado uma vez e não será mais reimportado.
O tempo exato da reimportação não é garantido. A reimportação é processada ao longo do dia em que está programada, mas pode não estar pronta sempre no mesmo horário.
A reimportação recorrente mantém o agente de IA atualizado. Para a maioria das organizações, o ritmo semanal ou mensal é suficiente. Lembre-se de que sempre é possível reimportar manualmente, caso seja preciso refletir novas alterações fora da reimportação programada.
- Clique em Importar.
Importação de uma central de ajuda do Freshdesk (legado)
Os administradores do cliente podem importar uma central de ajuda do Freshdesk.
Como importar uma central de ajuda do Freshdesk
- No espaço de trabalho dos agentes de IA, selecione o agente de IA com o qual deseja trabalhar.
- Clique em Conteúdo na barra lateral e selecione Fontes de conhecimento.
- Clique em Adicionar fonte.
O painel Adicionar fonte é aberto.
- Em Tipo, selecione Freshdesk.
- Na URL da central de ajuda, insira a URL completa da sua central de ajuda do Freshdesk.
Você também pode adicionar a sua central de ajuda inteira ou apenas uma seção dela.
- Em Nome da fonte, insira um nome para sua fonte.
Este nome é usado nos relatórios do painel de relatórios dos agentes de IA.
- Em Frequência de importação, selecione com que frequência o conteúdo da central de ajuda deve ser reimportado.
- Diariamente: o conteúdo é reimportado todos os dias, exceto aos domingos e no 15º dia do mês. Não recomendado a menos que sua fonte de conhecimento seja atualizada com muita frequência.
- Semanalmente: o conteúdo é reimportado a cada semana aos domingos.
- Mensalmente: o conteúdo é reimportado no 15º dia de cada mês.
-
Nunca: o conteúdo é importado uma vez e não será mais reimportado.
O tempo exato da reimportação não é garantido. A reimportação é processada ao longo do dia em que está programada, mas pode não estar pronta sempre no mesmo horário.
A reimportação recorrente mantém o agente de IA atualizado. Para a maioria das organizações, o ritmo semanal ou mensal é suficiente. Lembre-se de que sempre é possível reimportar manualmente, caso seja preciso refletir novas alterações fora da reimportação programada.
- Em Token de acesso à API, insira um token de API que você gerou no Freshdesk para essa finalidade.
- Clique em Importar.
Importação de um website ou espaço do Confluence (legado)
Os administradores do cliente podem importar um site ou espaço do Confluence.
As conexões do Confluence são criadas e gerenciadas no Conhecimento. Você precisa criar uma conexão com o Confluence no Conhecimento para poder conectar um website ou espaço do Confluence ao seu agente de IA.
Diferentemente de outras fontes de conhecimento para agentes de IA, não é possível especificar uma frequência de reimportação para o conteúdo do Confluence. As conexões do Confluence são sincronizadas automaticamente a cada 24 horas, mas você pode ressincronizar o conteúdo manualmente, se necessário.
Como importar um site ou espaço do Confluence
- No espaço de trabalho dos agentes de IA, selecione o agente de IA com o qual deseja trabalhar.
- Clique em Conteúdo na barra lateral e selecione Fontes de conhecimento.
- Clique em Adicionar fonte.
O painel Adicionar fonte é aberto.
- Em Tipo, selecione Confluence.
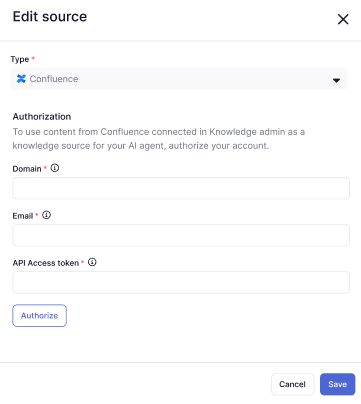
- Em Domínio, insira a URL do seu subdomínio do Zendesk (por exemplo,
https://yoursubdomain.zendesk.com). - Em E-mail, insira o endereço de e-mail de um administrador do Zendesk.
- Em Token de acesso à API, insira um token de API que você gerou para essa finalidade.
- Clique em Autorizar.
- Selecione um site ou espaço do Confluence que já esteja conectado à sua conta do Zendesk ou crie uma nova conexão com o Confluence.
Você pode selecionar mais de um.
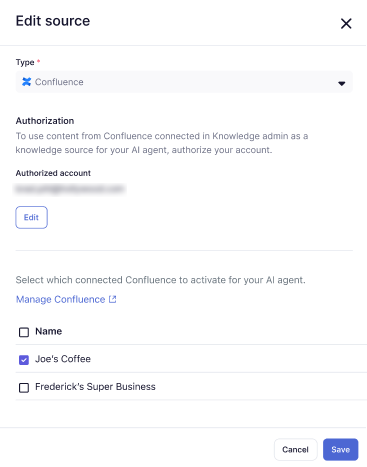
- Clique em Salvar.
O site ou espaço do Confluence que você selecionou foi adicionado à sua lista de fontes de conhecimento.
Importação de um arquivo CSV (legado)
Os administradores do cliente podem importar um arquivo CSV como fonte de conhecimento.
Como importar um arquivo CSV
- No espaço de trabalho dos agentes de IA, selecione o agente de IA com o qual deseja trabalhar.
- Clique em Conteúdo na barra lateral e selecione Fontes de conhecimento.
- Clique em Adicionar fonte.
O painel Adicionar fonte é aberto.
- Em Tipo, selecione Arquivo (CSV).
- Clique em Selecionar arquivo CSV da fonte de conhecimento.
- Selecione o arquivo CSV que você quer importar.
Consulte Formatação necessária para o arquivo CSV para garantir que o arquivo esteja devidamente formatado.
- Em Nome da fonte, insira um nome para sua fonte.
Este nome é usado nos relatórios do painel de relatórios dos agentes de IA.
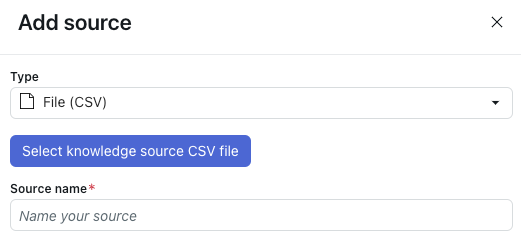
- Clique em Importar.
Formatação necessária para o arquivo CSV
O arquivo CSV carregado como fonte de conhecimento deve ter uma linha para cada artigo que você quer importar. Ele deve incluir as seguintes colunas:
- title: O título do artigo.
-
content: o conteúdo completo do artigo.
- O conteúdo pode conter tags HTML, então não há necessidade de removê-las. Na verdade, as tags podem ajudar, pois dão estrutura aos artigos, e essa estrutura ajuda o agente de IA a entender as seções do artigo.
- O conteúdo também pode conter Markdown, mas ele deverá ser válido, caso contrário, o conteúdo da célula em questão não será importado. Além disso, se o Markdown tiver sido escrito de maneira que a célula seja uma única linha de mais de 2.000 caracteres, a importação dela falhará sem que seja exibido qualquer aviso.
Você também pode incluir as seguintes colunas opcionais:
- labels: uma lista com o nome dos rótulos separados por um espaço. Os valores podem ser o que você quiser usar para categorizar o conteúdo.
- locale: usado para organizar os artigos por idioma ou mercado. Embora, tecnicamente, os valores possam ser qualquer coisa, é recomendável seguir a notação de localidade padrão (por exemplo, en-US ou pt-BR).
- article_url: o endereço da web externo onde o artigo pode ser encontrado. Ele é usado na atribuição da fonte no widget e na geração de relatórios dentro do painel de relatórios dos agentes de IA.
O formato do arquivo também deve usar:
- Vírgulas (,) como separador de coluna e aspas duplas (") como caractere de delimitação da cadeia de caracteres.
- A primeira linha para os cabeçalhos das colunas.
- Somente caracteres ASCII. Arquivos CSV não podem ser importados se tiverem caracteres fora do padrão ASCII.
É possível baixar um modelo no final deste artigo.
Importação de conteúdo com um rastreador da web (legado)
Os administradores do cliente podem importar conteúdo do website usando um rastreador da web.
Para obter mais informações sobre importações de rastreadores da web, consulte Práticas recomendadas para uso de um rastreador da web na importação de conteúdo para agentes de IA e Solução de problemas com importações de rastreadores da web para agentes de IA.
Como importar conteúdo com rastreador da web
- No espaço de trabalho dos agentes de IA, selecione o agente de IA com o qual deseja trabalhar.
- Clique em Conteúdo na barra lateral e selecione Fontes de conhecimento.
- Clique em Adicionar fonte.
O painel Adicionar fonte é aberto.
- Em Tipo, selecione Rastreador da web.
- Em Nome da fonte, insira um nome para sua fonte.
Este nome é usado nos relatórios do painel de relatórios dos agentes de IA.
- Selecione Rastrear URL exata se quiser que o rastreador da web importe informações apenas de páginas da web listadas no campo URLs iniciais, sem incluir subpáginas.
Quando essa opção não é selecionada, o rastreador da web aplica uma profundidade de rastreamento máxima de 15 subpáginas para quaisquer URLs listadas nas URLs iniciais.
- Em URLs iniciais, insira as URLs pelas quais você quer que o rastreador da web passe.
Liste cada URL em uma linha separada.
- Em Frequência de importação, selecione com que frequência o conteúdo rastreado deve ser reimportado.
- Diariamente: o conteúdo é reimportado todos os dias, exceto aos domingos e no 15º dia do mês. Não recomendado a menos que sua fonte de conhecimento seja atualizada com muita frequência.
- Semanalmente: o conteúdo é reimportado a cada semana aos domingos.
- Mensalmente: o conteúdo é reimportado no 15º dia de cada mês.
-
Nunca: o conteúdo é importado uma vez e não será mais reimportado.
O tempo exato da reimportação não é garantido. A reimportação é processada ao longo do dia em que está programada, mas pode não estar pronta sempre no mesmo horário.
A reimportação recorrente mantém o agente de IA atualizado. Para a maioria das organizações, o ritmo semanal ou mensal é suficiente. Lembre-se de que sempre é possível reimportar manualmente, caso seja preciso refletir novas alterações fora da reimportação programada.
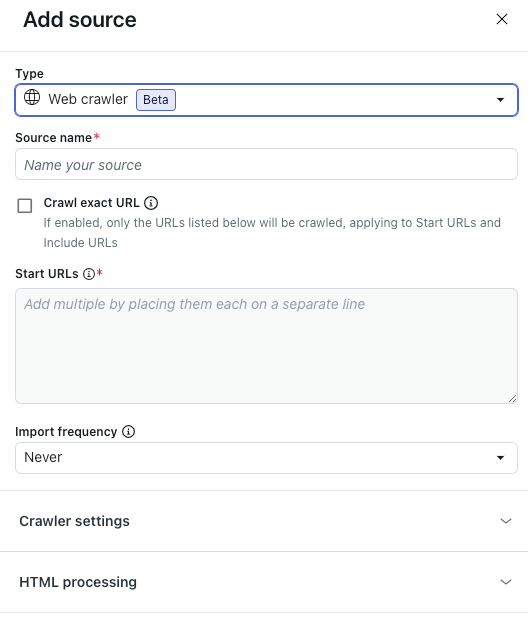
- (Opcional) Expanda Configurações do rastreador para ajustar as configurações avançadas do rastreador.
Consulte Ajuste das configurações avançadas do rastreador para saber mais.
Observação: essas configurações são recomendadas apenas para organizações com requisitos técnicos complexos. Muitas organizações não precisam dessas configurações. - (Opcional) Expanda Processamento de HTML para ajustar as configurações avançadas de HTML.
Consulte Ajuste das configurações avançadas de HTML para saber mais.
Observação: essas configurações são recomendadas apenas para organizações com requisitos técnicos complexos. Muitas organizações não precisam dessas configurações. - Clique em Importar.
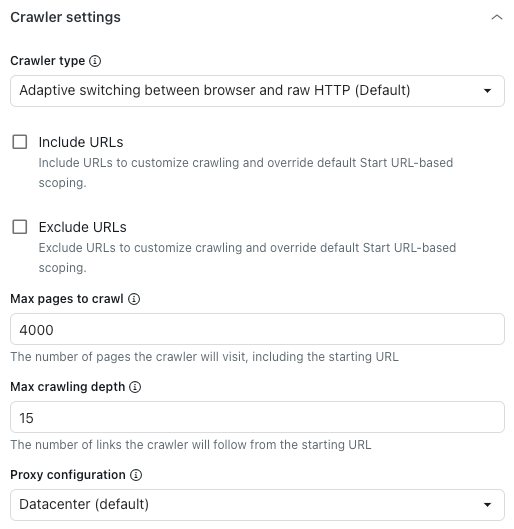
Ajuste das configurações avançadas do rastreador
-
No cabeçalho Configurações do rastreador, em Tipo de rastreador, selecione uma das seguintes opções:
- Alternância adaptável entre navegador e HTTP bruto (padrão): acelera e renderiza conteúdo em JavaScript, se presente.
- Navegador sem interface do usuário (Firefox + Playwright): confiável, renderiza conteúdo em JavaScript, é melhor para evitar bloqueios, mas pode ser lento.
- Cliente HTTP bruto (Cheerio): mais rápido, mas não renderiza conteúdo em JavaScript.
- Bruto com JavaScript: rastreia a página como se estivesse usando JavaScript.
- Selecione Incluir URLs ou Excluir URLs para personalizar o conjunto do escopo do rastreador no campo URLs iniciais indicado.
No campo abaixo de cada configuração, insira as URLs que você quer incluir ou excluir. Insira cada URL em sua própria linha.
Essas configurações afetam apenas os links encontrados durante o rastreamento das subpáginas. Se você quer rastrear uma página, especifique a URL dela no campo URLs iniciais.Se a estrutura da URL for inconsistente, como no exemplo a seguir:
- URL inicial:
https://support.example.com/en/support/home - URL do artigo:
https://support.example.com/en/support/solutions/articles/…
-
https://support.example.com/en/support/**
Assim, o rastreador da web incluirá todos os artigos, mesmo que o caminho deles seja diferente da URL inicial.
Como outro exemplo, a página a seguir é muito ampla e inclui páginas irrelevantes (por exemplo, a página de carreiras):- URL inicial:
https://www.example.com/en
https://www.example.com/en/careers/**
Dica: mais poderosos do que o texto sem formatação, os globs são padrões que permitem usar caracteres especiais para criar URLs dinâmicas para serem pesquisadas pelo rastreador da web. Aqui estão alguns exemplos:-
https://support.example.com/**permite que o rastreador acesse todas as URLs que começam com https://support.example.com/. -
https://{store,docs}.example.com/**permite que o rastreador acesse todas as URLs que começam com https://store.example.com/ ou https://docs.example.com/. -
https://example.com/**/*\?*foo=*permite que o rastreador acesse todas as URLs que contêm parâmetros de consulta foo com qualquer valor.
- URL inicial:
- Em Máximo de páginas a serem rastreadas, insira o número máximo de páginas pelas quais o rastreador da web passará, incluindo a URL inicial.
Isso inclui a URL inicial, as páginas de paginação, as páginas sem conteúdo, entre outras. O rastreador da web será interrompido automaticamente após atingir esse limite.
- Em Profundidade máxima de rastreamento, insira o número máximo de links que o rastreador da web seguirá a partir da URL inicial.
A URL inicial tem uma profundidade de 0. As páginas vinculadas diretamente da URL inicial têm profundidade 1 e assim por diante. Use essa configuração para evitar a fuga acidental do rastreador da web.
- Em Configuração de proxy, selecione uma das seguintes opções:
- Datacenter (padrão): método mais rápido para coletar dados.
-
Residencial: desempenho reduzido, mas menor probabilidade de bloqueio. Ideal para quando o proxy padrão está bloqueado ou quando você precisa rastrear de um país específico.
Ajuste das configurações avançadas de HTML
-
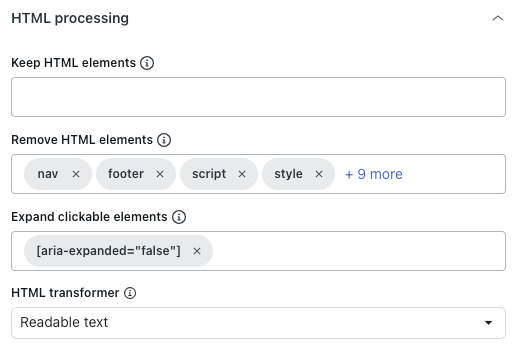
No cabeçalho Processamento de HTML, em Manter elementos HTML, insira um seletor de CSS para manter somente os elementos HTML especificados.
Todos os outros conteúdos serão removidos, ajudando você a se concentrar apenas nas informações relevantes.
- Em Remover elementos HTML, escolha quais elementos HTML remover antes de converter em texto, Markdown ou salvar como HTML.
Isso ajuda a excluir conteúdo indesejado.
- Em Expandir elementos clicáveis, insira um seletor de CSS válido que corresponda aos elementos DOM que serão clicados.
Isso é útil para expandir seções recolhidas, a fim de capturar seu conteúdo de texto.
- Em Transformador de HTML, selecione um dos seguintes valores para definir como limpar o HTML, mantendo apenas o conteúdo importante e removendo conteúdo desnecessário (como navegação ou pop-ups):
- Extractus: (não recomendado) usa a biblioteca Extractus.
- Nenhum: remove apenas os elementos HTML especificados na opção anterior Remover elementos HTML.
- Texto legível: usa a biblioteca de legibilidade do Mozilla para extrair o principal conteúdo do artigo, removendo navegação, cabeçalhos, rodapés e outros elementos não essenciais. Funciona melhor com blogs e sites ricos em artigos.
-
Texto legível, se possível: usa a biblioteca de legibilidade do Mozilla para extrair o conteúdo principal, mas reverte para o HTML original se a página não parecer um artigo. Isso é útil para sites com tipos de conteúdo mistos, como artigos ou páginas de produtos, já que preserva mais o conteúdo criado em páginas que não são artigos.
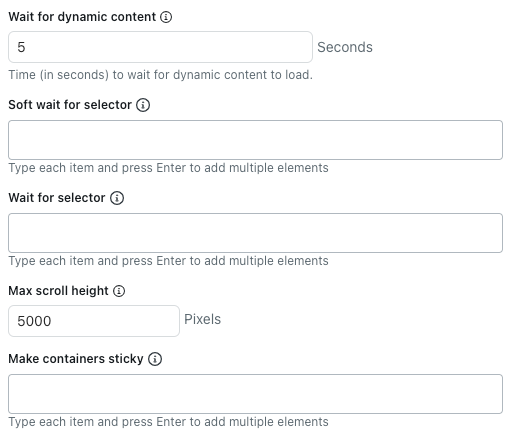
- Em Aguarde o conteúdo dinâmico, insira o número de segundos que o rastreador deve esperar para que o conteúdo dinâmico seja carregado. Por padrão, ele aguarda cinco segundos ou até que a página termine de carregar, o que ocorrer primeiro.
- Em Aguardar o seletor suavemente, insira os seletores de CSS para os elementos HTML que o rastreador deve esperar carregar antes de extrair conteúdo.
Se o elemento selecionado não estiver presente, o rastreador ainda rastreará a página.
Liste cada seletor de CSS em uma linha separada.
- Em Aguardar pelo seletor, insira os seletores de CSS para os elementos HTML que o rastreador deve esperar carregar antes de extrair conteúdo.
Se o elemento selecionado não estiver presente, o rastreador não rastreará a página.
Liste cada seletor de CSS em uma linha separada.
- Em Altura máxima de rolagem, insira o número máximo de pixels que o rastreador deve percorrer.
O rastreador rolará a página para carregar mais conteúdo até que a rede fique ociosa ou essa altura de rolagem seja atingida. Defina como 0 para desativar completamente a rolagem.
Essa configuração não se aplica ao uso do cliente HTTP bruto, pois ele não executa JavaScript nem carrega conteúdo dinâmico.
- Em Fixar contêineres, insira um seletor de CSS para os elementos HTML nos quais o conteúdo filho deve ser mantido, mesmo que esteja oculto.
Liste cada seletor de CSS em uma linha separada.
Isso é útil ao usar a opção Expandir elementos clicáveis em páginas que removem totalmente o conteúdo oculto da página.
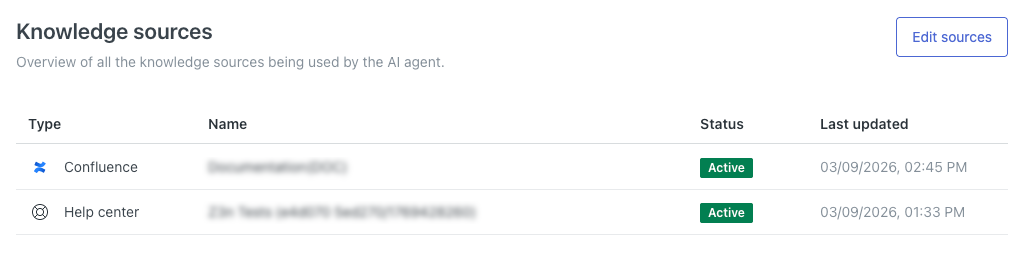
Visualização de todas as fontes de conhecimento conectadas
Nas configurações do seu agente de IA, você pode visualizar todas as origens de conteúdo às quais ele está conectado atualmente. O agente de IA usará essas origens para gerar respostas às perguntas dos clientes.
Como visualizar todas as origens de conteúdo conectadas
- No espaço de trabalho dos agentes de IA, selecione o agente de IA com o qual deseja trabalhar.
-
Clique em Conteúdo na barra lateral e selecione Fontes de conhecimento.
Esta página mostra uma lista de todas as fontes de conhecimento atualmente conectadas ao agente de IA.