Riepilogo: ◀ ▼
Puoi configurare più web crawler per indicizzare i contenuti dei siti web esterni per la ricerca nel centro assistenza , filtrando i risultati in base all’origine. I crawler usano mappe del sito o URL specifici per raccogliere contenuti pubblici, incluse le pagine con rendering JavaScript. Si aggiornano periodicamente, garantendo la visualizzazione di contenuti esterni pertinenti nei risultati di ricerca. Puoi controllare quali siti o pagine sottoporre a scansione, aiutando a espandere le risorse ricercabili senza il coinvolgimento degli sviluppatori.
Il web crawler ti consente di eseguire la scansione e l’indicizzazione di contenuti esterni da usare ovunque utilizzi contenuti esterni nel tuo account Zendesk senza risorse per gli sviluppatori. Puoi configurare più crawler per eseguire la scansione e indicizzare contenuti diversi nello stesso sito web o in siti web diversi. Puoi anche eseguire la scansione di un elenco di URL specifici senza dover eseguire la scansione di un intero sito.
Quando gli utenti eseguono una ricerca nel centro assistenza, i contenuti esterni pertinenti individuati dal crawler vengono classificati e presentati nella pagina dei risultati della ricerca, dove gli utenti possono filtrare i risultati e fare clic sui link per visualizzare i contenuti esterni in un'altra scheda del browser.
Informazioni sul web crawler
Puoi creare fino a 20 web crawler per eseguire la scansione e indicizzare contenuti esterni nello stesso sito web o in siti web diversi. I contenuti dei siti web sottoposti a scansione e le pagine all’interno dei siti web sono disponibili ovunque usi contenuti esterni nel tuo account Zendesk. I siti esterni in cui eseguire la ricerca devono avere una mappa del sito che elenca le pagine per il web crawler. Inoltre, le pagine in cui effettuare la ricerca devono essere pubbliche (ossia accessibili senza autenticazione).
- Scansionare l’intero sito, il crawler individua automaticamente la mappa del sito associata all’URL iniziale o alla mappa del sito specificata, quindi la usa per eseguire la scansione di tutte le pagine del sito.
- Limitare la scansione a singole pagine, puoi specificare fino a cinque URL di cui eseguire la scansione. L’opzione Limita la scansione a questi URL viene selezionata automaticamente se inserisci più di un URL. Tuttavia, se inserisci un solo URL iniziale, puoi comunque selezionare manualmente questa opzione per limitare la scansione a una singola pagina. Se inserisci una mappa del sito, questa opzione viene deselezionata e disabilitata, in quanto il crawler deve eseguire la scansione di tutte le pagine della mappa del sito.
Quando crei un nuovo crawler, il nome che assegni al crawler verrà usato per creare il valore di origine. I valori di origine vengono usati come filtri nella ricerca nel centro assistenza. Se vuoi cambiare il nome in un secondo momento, puoi sempre modificare o assegnare un nome di origine diverso. Consulta Gestione dei web crawler.
Dopo la configurazione, i crawler vengono eseguiti periodicamente, visitando le pagine della mappa del sito e importando contenuti da tali origini negli indici di ricerca del centro assistenza. Se una mappa del sito non è disponibile, i crawler seguiranno i link nella pagina di livello superiore per visitare le pagine secondarie e importarne i contenuti. Il crawler continua in questo modo, visitando ogni pagina collegata e quindi seguendo i link alla pagina successiva nella gerarchia del sito. Questa operazione continua fino a quando il crawler non ha eseguito la scansione di tutti i contenuti collegati a quattro livelli o dell’intero sito, a seconda dell’evento che si verifica per primo. Il crawler segue solo i link che rimandano a pagine all'interno del dominio del sito; non vengono visitate pagine esterne.
I web crawler indicizzano i contenuti che si trovano nell’origine della pagina caricata inizialmente, anche se sono nascosti da un elemento dell’interfaccia utente, come un pannello accordion. I web crawler possono anche usare la scansione adattiva per acquisire contenuti che richiedono JavaScript per il rendering. Prima di elaborare ogni sezione di un sito web, il crawler campiona automaticamente un numero limitato di pagine e confronta i risultati tra un recupero standard e un rendering completo del browser. Se il rendering del browser acquisisce una quantità notevolmente maggiore di contenuti, il crawler passa alla modalità browser per quella sezione del sito. Ciò significa che è possibile eseguire la scansione di parti diverse dello stesso sito web in modalità diverse. Ad esempio, una sezione di un blog statico potrebbe usare il recupero standard, mentre una sezione di app dinamica usa il rendering del browser. Questo processo viene eseguito automaticamente senza alcuna configurazione.
Inoltre, i web crawler non scansionano i link nelle pagine che visitano; visitano solo le pagine della mappa del sito che sono stati configurati per utilizzare. Se il crawler non riesce a raccogliere informazioni da un sito web durante una scansione pianificata regolarmente (ad esempio, se il sito web è inattivo o se ci sono problemi di rete), il centro assistenza conserverà i risultati della scansione precedente, che continueranno a essere ricercabili nel centro assistenza.
Configurazione di un web crawler
- Il web crawler non funziona con i siti web che usano la codifica di compressione dei file gzip. Non vedrai i risultati delle ricerche in questi siti.
- Un ritardo di crawl non verrà rispettato dal web crawler se impostato sui record robots.txt del sito esterno.
- Il tag changefreq non influisce in alcun modo sul web crawler.
Per configurare il web crawler
-
In Amministratore Knowledge, fai clic su Impostazioni (
 ) nella barra laterale.
) nella barra laterale.
- Fai clic su Impostazioni di ricerca.
- In Crawler, fai clic su Gestisci.
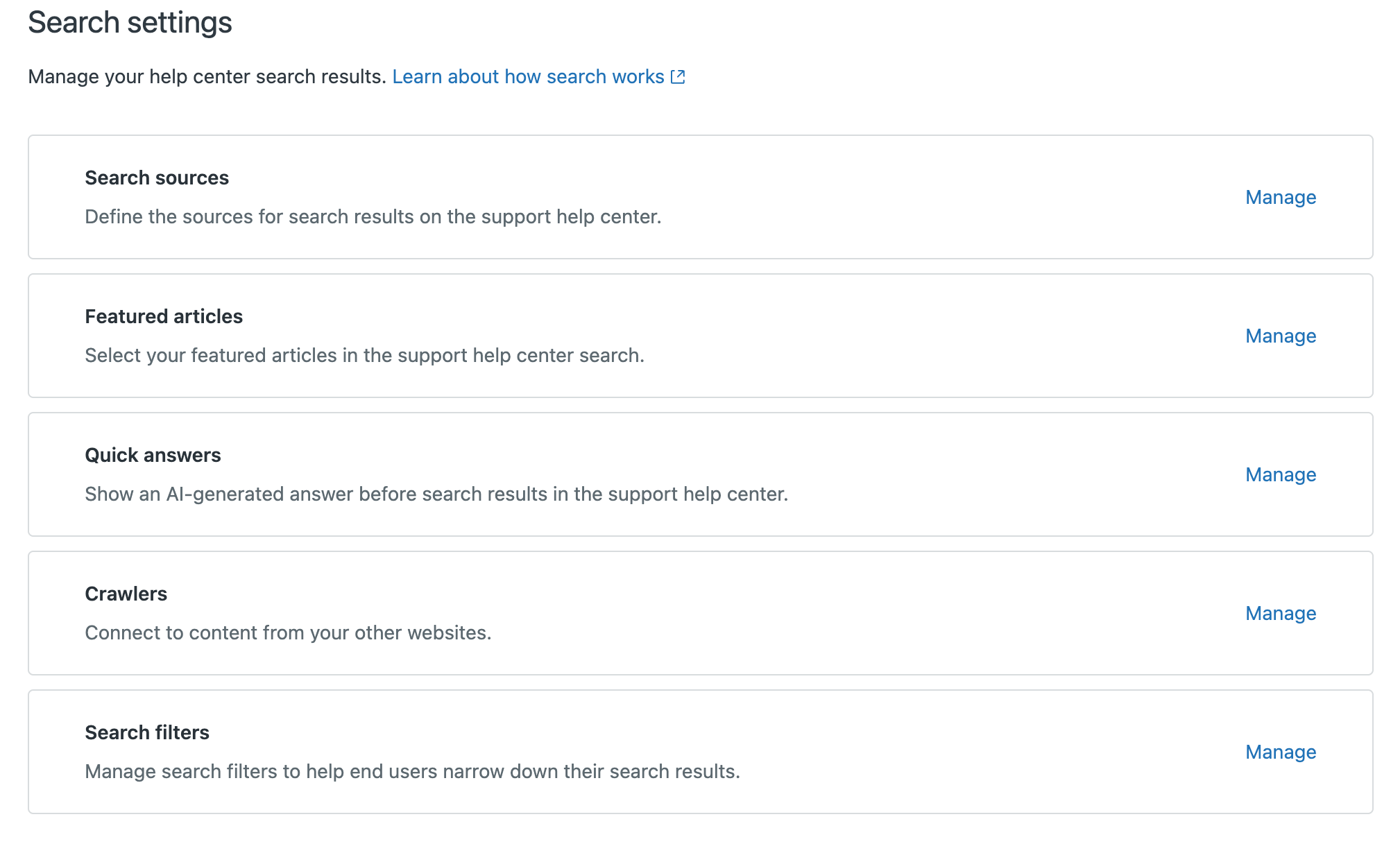
- Fai clic su Aggiungi crawler.

- Fai clic su Continua.
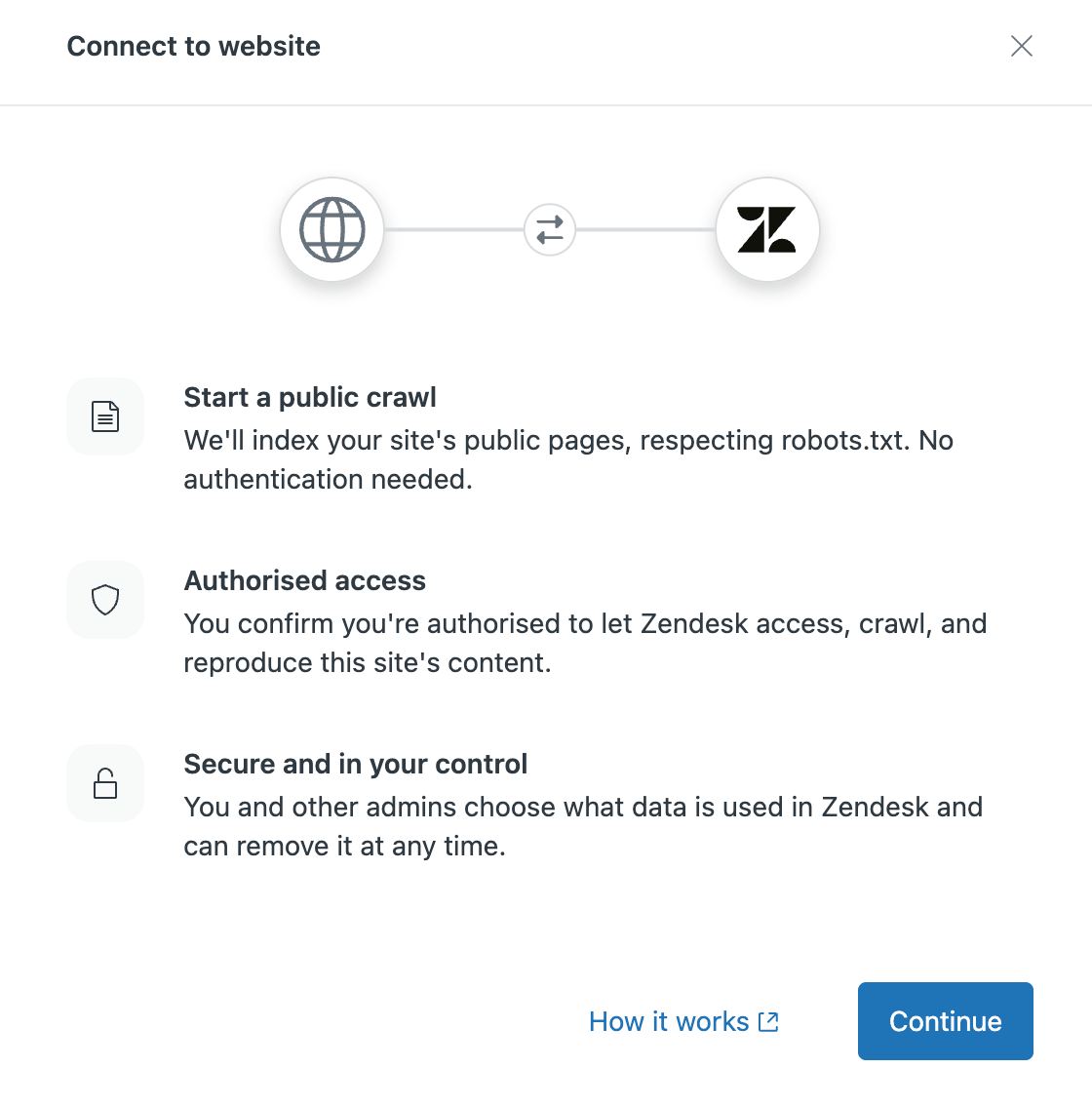
- In Sincronizza contenuto da un sito web, inserisci quanto segue:
- Nome del crawler da assegnare al crawler. Questo nome identifica il tuo web crawler nell’elenco di gestione dei crawler e viene usato per creare il valore dell’origine di ricerca usato come filtro nella ricerca del centro assistenza.
-
URL iniziale del sito o delle pagine di cui eseguire la scansione. Se vuoi:
- Scansiona un intero sito web, quindi inserisci il dominio principale (ad esempio, zendesk.com) o il percorso della mappa del sito (ad esempio, zendesk.com/sitemap.xml)
-
Limita la scansione a singole pagine, inserisci il valore del dominio/della pagina in questo campo (ad esempio, test.com/faq.htm). Fai clic su + Aggiungi un altro per aggiungere fino a cinque URL.
Quando selezioni questa opzione, il crawler eseguirà la scansione e indicizzerà solo gli URL iniziali specificati durante la configurazione.
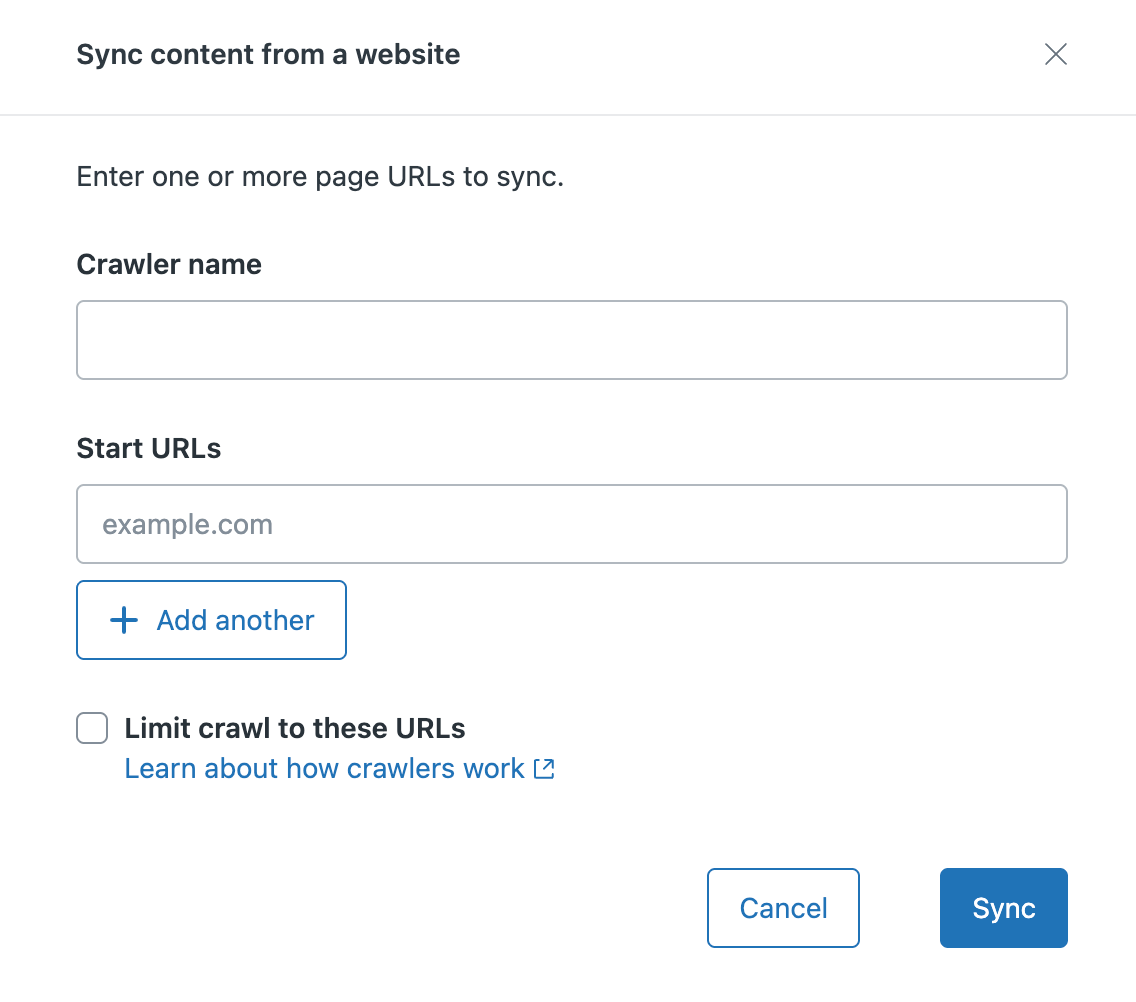
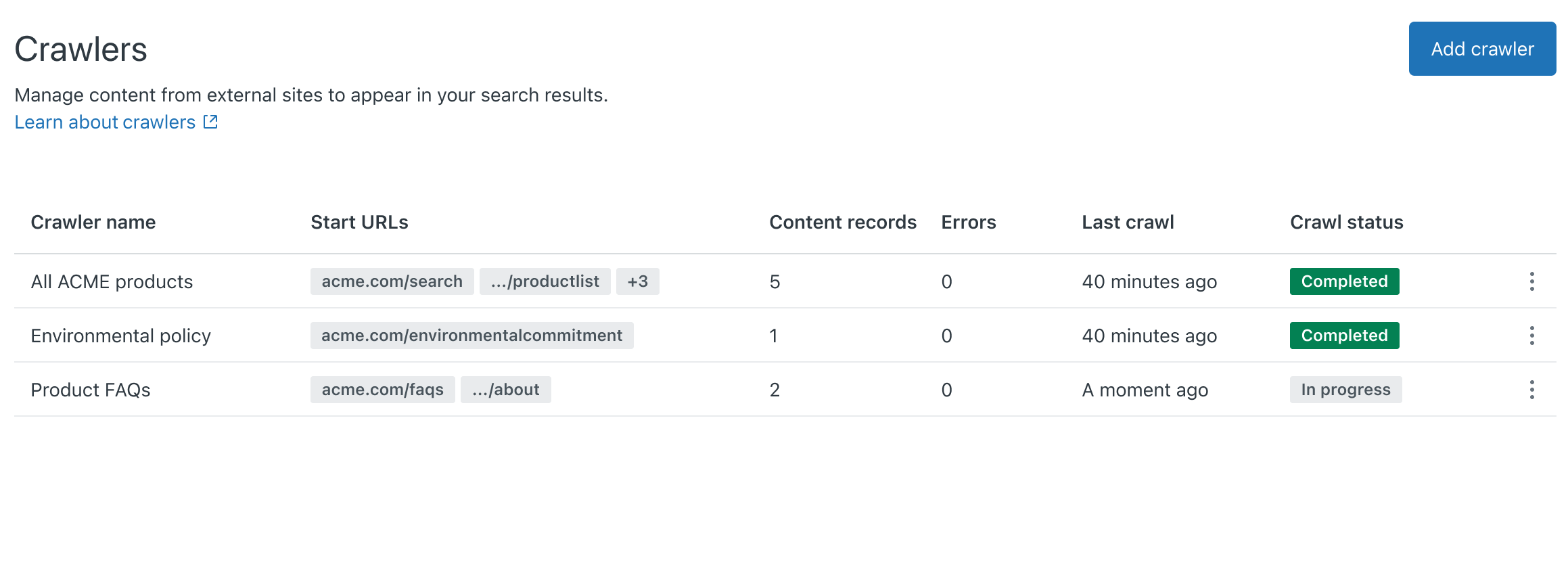
- Fai clic su Sincronizza. Il web crawler viene aggiunto alla pagina Crawler. Entro 24 ore, il crawler recupererà e analizzerà la mappa del sito specificata. Una volta completata l’elaborazione della mappa del sito, il crawler inizia a eseguire la scansione delle pagine e a indicizzarne il contenuto. Se il crawler non riesce, il proprietario del crawler riceverà una notifica email con suggerimenti per risolvere il problema. Il crawler riproverà periodicamente.Nota: Zendesk/External-Content è lo user agent per il web crawler. Per evitare errori del crawler dovuti al blocco delle richieste da parte del firewall, inserisci Zendesk/External-Content alla whitelist (o all’elenco consentiti).
- Ricerca nel centro assistenza, devi selezionare i contenuti da includere ed escludere nei risultati di ricerca del centro assistenza. Consulta Come includere contenuti esterni nei risultati di ricerca del centro assistenza.
- Sezione Knowledge del Pannello del contesto per gli agenti, consulta Configurazione di Knowledge nel Pannello del contesto.
Avvertenza sulla traduzione: questo articolo è stato tradotto usando un software di traduzione automatizzata per fornire una comprensione di base del contenuto. È stato fatto tutto il possibile per fornire una traduzione accurata, tuttavia Zendesk non garantisce l'accuratezza della traduzione.
Per qualsiasi dubbio sull'accuratezza delle informazioni contenute nell'articolo tradotto, fai riferimento alla versione inglese dell'articolo come versione ufficiale.