Summary: ◀▼
You can set up multiple web crawlers to index external website content for your help center search, filtering results by source. Crawlers use sitemaps or specific URLs to gather public content, including JavaScript-rendered pages. They update periodically, ensuring relevant external content appears in search results. You control which sites or pages to crawl, helping expand searchable resources without developer involvement.
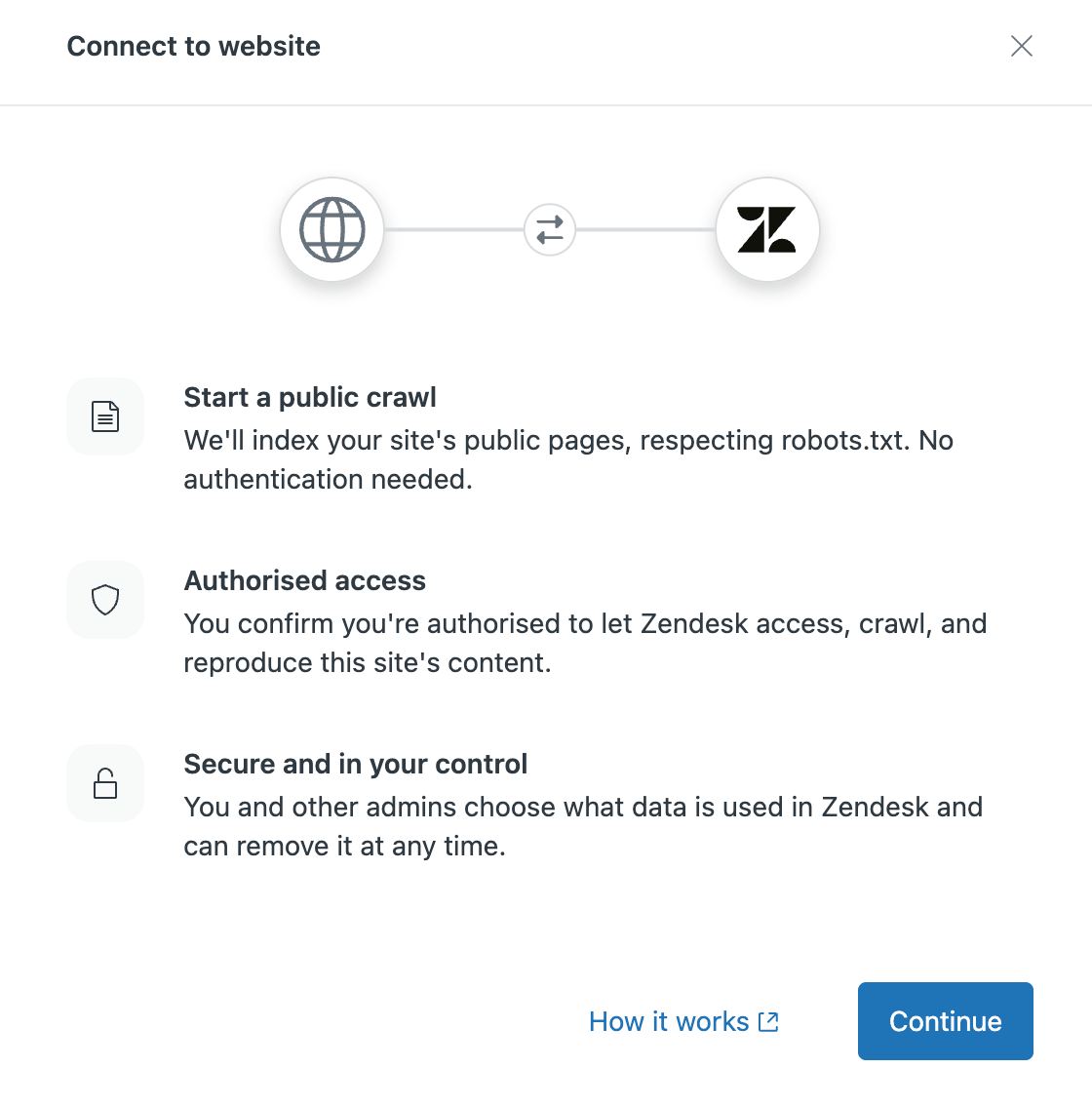
The web crawler lets you crawl and index external content for use wherever you use external content in your Zendesk account without developer resources. You can set up multiple crawlers to crawl and index different content in the same or different websites. You can also crawl a list of specific URLs without having to crawl an entire site.
When users perform a search in your help center, relevant external content discovered by the crawler is ranked and presented on the search results page, where users can filter the results and click the links to view the external content link in another browser tab.
About the web crawler
You can create up to 20 web crawlers to crawl and index external content in the same or different websites. Content from crawled websites and pages within websites are made available wherever you use external content in your Zendesk account. External sites that you want to crawl must have a sitemap that lists the pages for the web crawler. In addition, the pages you want to crawl must be public (non-authenticated).
- Crawl the entire site, the crawler automatically locates the sitemap associated with the starting URL or sitemap you specify, then uses it to crawl all pages within that site.
- Limit your crawl to individual pages, you can specify up to five URLs that you want to crawl. The Limit crawl to these URLs option is automatically selected if you enter more than one URL. However, if you enter just one starting URL, you can still manually select this option to restrict the crawl to a single page. If you enter a sitemap, this option is deselected and disabled, as the crawler must crawl all pages within the sitemap.
When you create a new crawler, the name that you assign to the crawler will be used to create the Source value. Source values are used as filters in your help center search. If you want to change the name later, you can always edit or assign a different source name. See Managing web crawlers.
After they've been configured, crawlers are scheduled to run periodically, visiting the pages in the sitemap and ingesting content from those sources into the help center search indexes. If a sitemap isn't available, crawlers will follow links on the top level page to visit the secondary pages and ingest their content. The crawler continues in this manner, visiting each linked page, and then following the links to the next page in the site hierarchy. This continues until the crawler has either crawled all linked content four levels deep or the entire site, whichever comes first. The crawler only follows links that lead to pages within the site domain; no external pages are visited.
Web crawlers index content that is in the page source on the initial page load, even if it's hidden by a UI element, such as an accordion. Web crawlers can also use adaptive crawling to capture content that requires JavaScript to render. Before processing each section of a website, the crawler automatically samples a small number of pages and compares results between a standard fetch and a full browser render. If the browser render captures significantly more content, the crawler switches to browser mode for that section of the site. This means different parts of the same website can be crawled in different modes. For example, a static blog section might use standard fetching, while a dynamic app section uses browser rendering. This process happens automatically with no configuration required.
Web crawlers don't crawl links on the pages they visit; they only visit the pages in the sitemap that they are configured to use. If the crawler fails to collect information from a website during a regularly scheduled crawl (for example, if the website is down or if there are network issues), the help center will retain the results from the previous crawl, which will continue to be searchable in the help center.
Setting up a web crawler
- The web crawler does not work with websites that use gzip file compression encoding. You will not see search results from these sites.
- A crawl-delay will not be respected by the web crawler when set on external site robots.txt records.
- The changefreq tag doesn't affect the web crawler in any way.
To set up the web crawler
-
In Knowledge admin, click Settings (
 ) in the sidebar.
) in the sidebar.
- Click Search settings.
- Under Crawlers, click Manage.
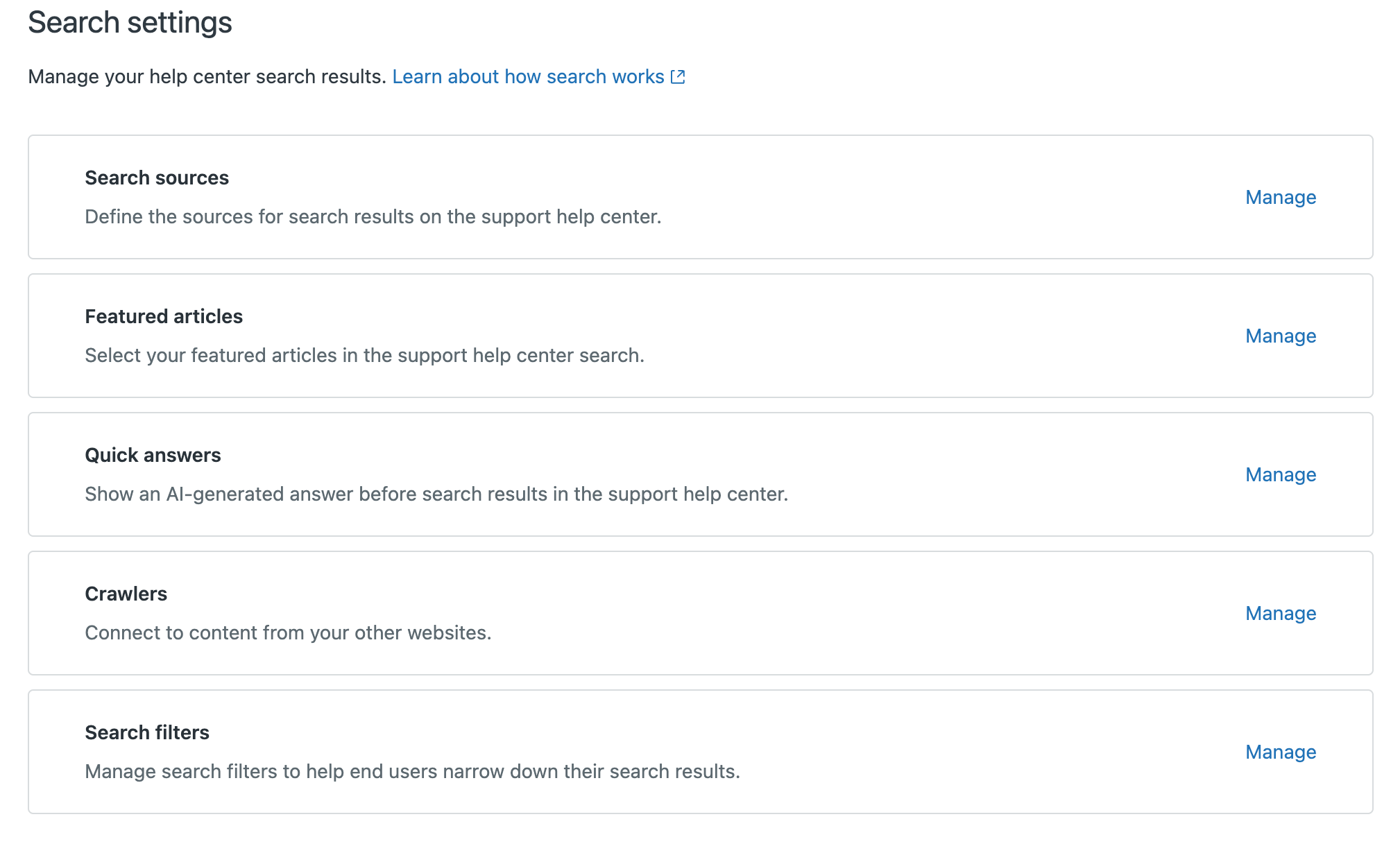
- Click Add Crawler.

- Click Continue.
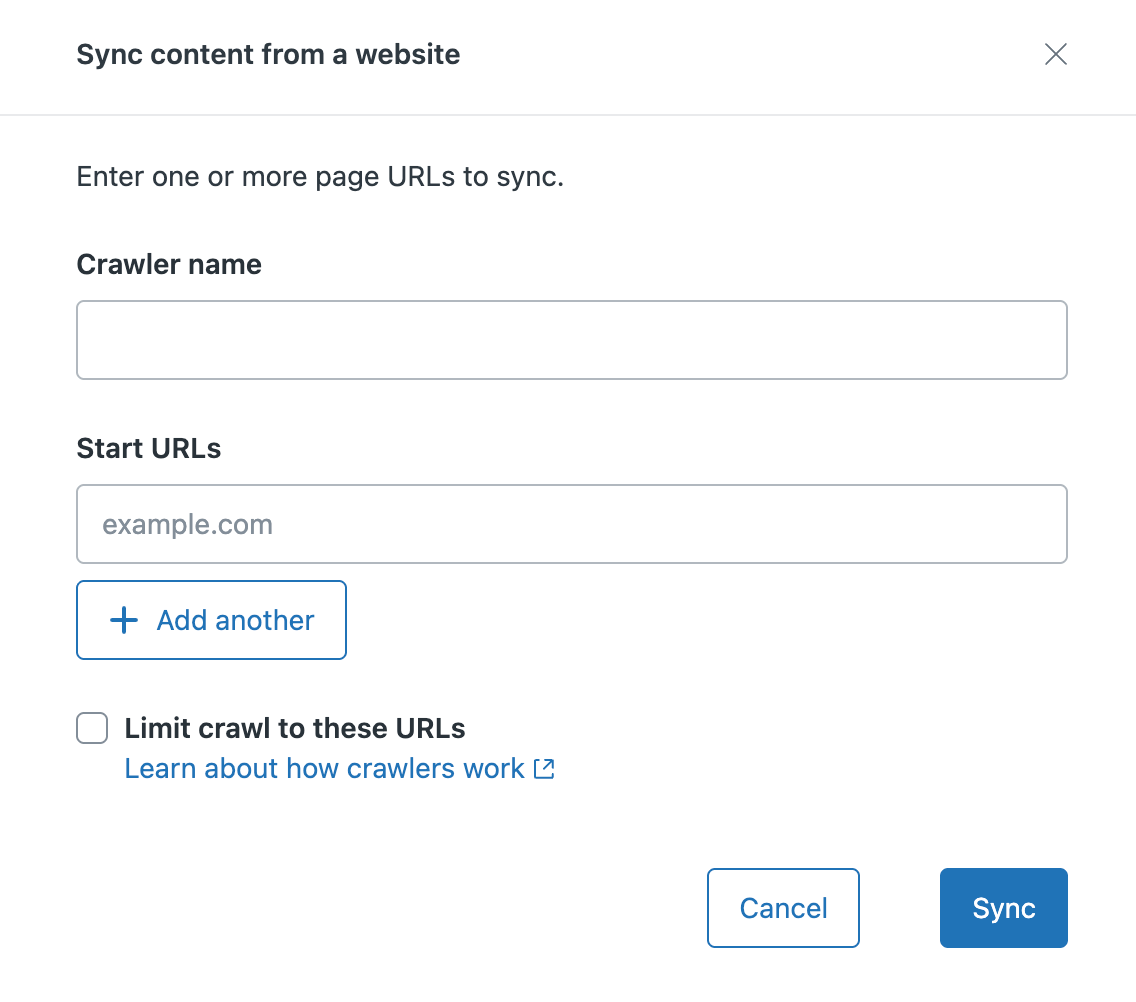
- In Sync content from a website, enter the following:
- Crawler name that you want to assign to the crawler. This name identifies your web crawler on the crawler management list, and is used to create the search source value used as the filter in your help center search.
-
Start URLs for the site or pages that you want to crawl. If
you want to:
- Crawl an entire website, then enter the primary domain (for example, zendesk.com) or the sitemap path (for example, zendesk.com/sitemap.xml)
-
Limit crawling to individual pages, enter the
domain/page value in this field (for example,
test.com/faq.htm). Click + Add another to add up to
five URLs.
When you select this option, the crawler will only crawl and index the start URLs specified during setup.
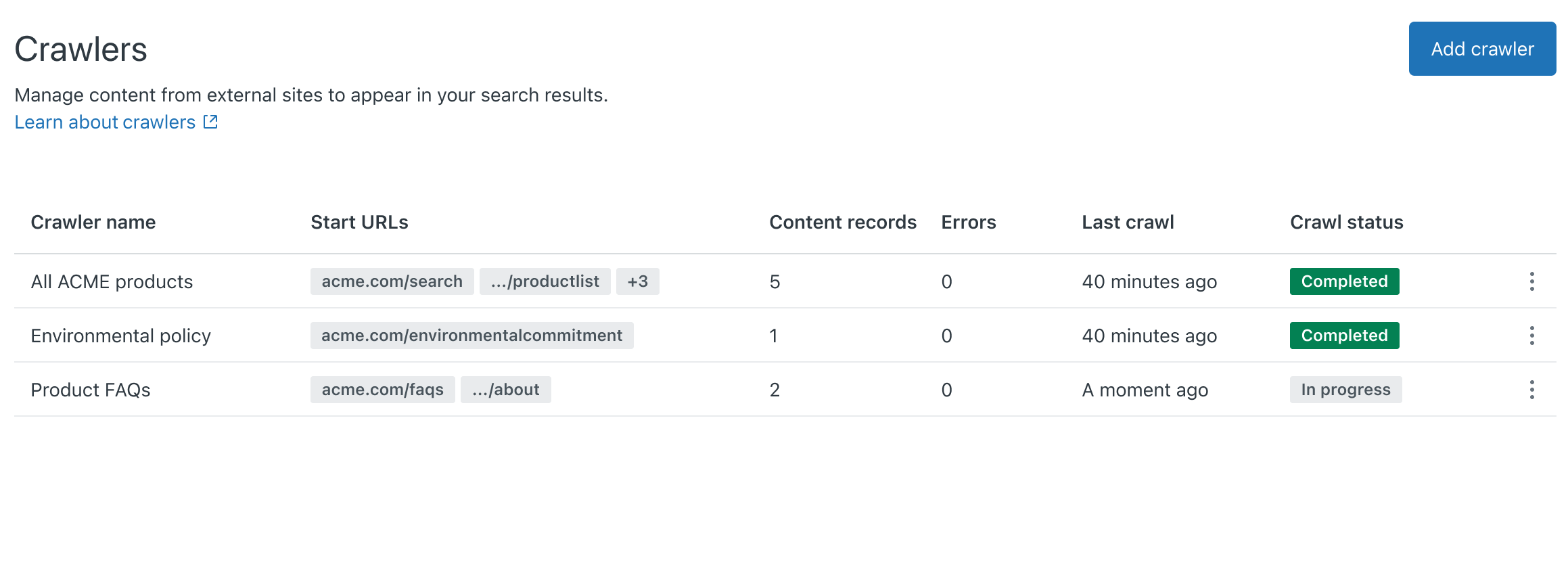
- Click Sync. The web crawler is added to the Crawlers page. Within 24 hours, the crawler will fetch and parse the specified sitemap. When the sitemap processing succeeds, the crawler begins to crawl the pages and index its content. If the crawler fails, the crawler owner will receive an email notification with troubleshooting tips to help resolve the issue. The crawler will try again periodically.Note: Zendesk/External-Content is the user agent for the web crawler. To prevent the crawler from failing due to a firewall blocking requests, whitelist (or allow-list) Zendesk/External-Content.
- Help center search, then you need to select the content that you want to include and exclude in help center search results. See Including external content in your help center search results.
- Knowledge section of the context panel for agents, see Configuring Knowledge in the context panel.